A. Gelbukh, I. Bolshakov, S. Galicia Haro. Automatic Learning of a Syntactical Government Patterns Dictionary from Web-Retrieved Texts. Proc. International Conference on Automatic Learning and Discovery, Carnegie Mellon University, Pittsburgh, PA, USA, June 11 - 13, pp. 261 - 267, 1998.
Automatic
Learning
of a Syntactical Government Patterns Dictionary
from Web-Retrieved Texts
A.F Gelbukh
I.A. Bolshakov
S.N. Galicia-Haro
gelbukh(?)pollux.cic.ipn.mx
Natural Language Laboratory,
Centro de Investigación en Computación,
Instituto Politécnico Nacional,
Mexico City
A statistical-based technique is proposed that given a large text corpus, allows to automatically compile a government patterns dictionary useful for the resolution of ambiguity of prepositional phrases attachment in syntax analysis. It is suggested that a dictionary used for syntactic disambiguation should reflect not only the properties of the language and text, but also the properties of the specific analyzer used for parsing. The use of computer simulation for assessing the parsing results and for investigation of different methods is discussed.
The Laboratory of Natural Language Processing of our Center deploys a project on extracting information from natural language texts, currently our target language being Spanish. For this purpose, morphological, syntactic, and semantic analyzers are being developed*.
In our research, we emphasize the importance of lexical linguistic knowledge, i.e., various dictionaries. One of the most important dictionaries used in our syntactic analyzer is a dictionary of syntactic government patterns.
Since such a dictionary should contain statistical weights of words and their combinations with words of specific types, we employ the methods of automated learning of such a dictionary from the texts collected in different ways, including retrieving them from the Internet. In this article, the methods we use for the compilation of the dictionary and for prepositional phrases attachment disambiguation are described in detail.
1. Dictionary of syntactic government patterns
This dictionary provides the information on the actants of each word, the possible ways of their expression in the text, and the possibility or impossibility of their co-occurrence in one sentence with one and the same word. Such a dictionary (nothing was yet said about any statistical weights) can be compiled manually, using examples from the texts and the linguistic intuition of a native speaker. Here is an example of a dictionary entry from the version of Spanish dictionary manually compiled in our laboratory:
|
mover |
||
|
Actants |
Expressions |
Examples |
|
X = 1: who moves? |
1.1. Noun (animate) |
el cargador movió |
|
Y = 2: what moves |
2.1. Noun (inanimate) |
movió los muebles |
|
|
2.2. a Noun (animate) |
movió a la niña |
|
Z = 3: from where? |
3.1. de Noun (location) |
movió de la sala |
|
|
3.2. desde Noun (location) |
movió desde la casa |
|
W = 4: to where? |
4.1. a Noun (location) |
movió al corredor |
|
|
4.2. hasta Noun (location) |
movió hasta la oficina |
|
|
4.3. hacia Noun (inanimate) |
movió hacia la derecha |
|
V = 5: through what? |
5.1.por Noun (inanimate) |
movió por la puerta |
|
|
5.2. a través deNoun (inanimate) |
movió a través de la ventana |
|
Usage notes |
1. Obligatory: 2 2. Not recommended: 3.1 + 4.2, 3.2 + 4.1. |
|
In this example it is shown that the Spanish word mover ‘to move’ has 5 actants; the fourth actant, for example, can be expressed with three different prepositions, the second actant is obligatory, i.e., the verb is transitive, and some combinations of actants are not recommended. Any combinations of prepositions expressing the same actant are still impossible: “*El cargador movió los muebles de la sala desde la casa” ‘*The worker moved the furniture from the hall from the house,’ or at least special punctuation is to be used.
Note that in most cases the actants are expressed in the text by means of prepositions, at least in Spanish and English (in some other languages morphological cases are used, but all the techniques described here are fully applicable to those languages as well).
A dictionary of such kind is useful not only for text generation, but also within text analysis, for syntactic disambiguation. Namely, the syntactic hypotheses that contain the combinations listed in the dictionary should be preferred over the ones that contain the combinations not listed there. For example, in the Spanish phrase “El alumno movió los libros sobre la revolución a otro estante” ‘The pupil moved the books about the revolution to another shelf’ the syntactic hypothesis containing the wrong links “*mover ® sobre revolución” and “*libro ® a estante” will be rejected, while the hypothesis containing the links “mover ® a estante” and “libro® sobre revolución,” present in the dictionary, will be accepted.
2. Statistical weights and their use for syntactic disambiguation
The dictionary discussed above can be represented as a list of possible combinations of words with prepositions and, optionally, with some characteristics of the words introduced by these prepositions. In the simplest form such a list contains entries like the following:
1. mover + de
2. mover + hasta
3. mover + desde + hasta + por
4. mover + de + a través de,
etc.
The usefulness of such a dictionary increases if statistical weights are assigned to the combinations. Such weights have several possible uses. For example, a very rarely used combination, though included in the dictionary, should not give much preference to a hypothesis where it was found.
Another use of statistical weights is to handle the case when both hypotheses contain the links found in the dictionary. In this case the preference should be given to the hypothesis containing the more frequent links. For example, in Spanish phrase “Hablo con el director de la universidad” ‘I speak with the director of the university’ or ‘I speak with the director about the university’ the preference should be given to the first interpretation because the link “hablar ® de” though it is possible, it has less weight than the link “director ® de.”
However, the statistical weights give actually the possibility to change the whole point of view on the nature and use of the dictionary that is used for the purpose of disambiguation. In the traditional view, the dictionary reflects the properties of the language itself, of the texts, giving the answer to the question: What words, word combinations, or syntactic constructions are used in the texts? In our model, the dictionary reflects the properties of the specific syntactic analyzer used for the analysis of these texts, giving the answer to the question: What kinds of errors does this specific analyzer make when reporting such words, word combinations, or syntactic constructions?
Really, for the purposes of disambiguation there is no reason to include in the dictionary the combinations that have the same frequency in all the syntactic hypotheses, both true and false, produced by a specific analyzer. On the other hand, those combinations whose frequencies in the true and false variants of analysis are the most different have the maximal “distinguishing power”.
In
our dictionary, the weight of a combination, let us say the combination number i in the list, is defined as the
quotient ![]() , where
, where ![]() is the frequency of
the combinationin the correct
variants of parsing, i.e., in the texts, and
is the frequency of
the combinationin the correct
variants of parsing, i.e., in the texts, and ![]() is its frequency in
the incorrect variants of syntactic structure produced by this specific
analyzer.
is its frequency in
the incorrect variants of syntactic structure produced by this specific
analyzer.
In the process of disambiguation, for each variant of the parsing of a phrase, the dictionary weights of all the combinations found in the variant are multiplied. The variant chosen is that with the greatest value of this product. These products, after normalization, represent the probability for the variant to be the true one. Here, we omit a rather simple mathematical reasoning justifying this method.
Thus, some combinations can have a weight greater than 1, which means that this combination appears in correct variants more frequently than in incorrect ones. Others can have a weight inferior to 1, which means that they more frequently appear in false variants. Finally, some combinations may have a weight of 1, which means that this combination is useless for disambiguation, even if it is frequent in the texts.
Yet
again, these weights, namely the ![]() divisor, depend on
the specific analyzer used in the system, since they are intended to be used
for detecting the errors made by this specific analyzer. However, for the same
combinations, the traditional weights, i.e., the frequencies in the texts, are
represented by the values
divisor, depend on
the specific analyzer used in the system, since they are intended to be used
for detecting the errors made by this specific analyzer. However, for the same
combinations, the traditional weights, i.e., the frequencies in the texts, are
represented by the values ![]() and, for reference,
can be also included in the dictionary.
and, for reference,
can be also included in the dictionary.
3. Learning the government patterns dictionary from a text corpus
It is obvious that it is not possible to compile manually a large dictionary of such kind, i.e., with the frequencies, using only the linguistic intuition of a native speaker. An automatic procedure should be provided to compile the dictionary on the basis of the parsing results obtained with a text corpus.
What is more, the calculation of the weights is to be re-done each time a significant modification is made to the parsing algorithm or the grammar. Of course, a “general” model of the parser can be also used to obtain some “parser-independent” weights, but the weights trained on a specific parser will work better.
It is not a problem to calculate such weights provided that there is a marked-up text corpus available, i.e., a corpus where the correct syntactic relationships are marked manually or by some analyzer. However, for a specific subject area, or a specific genre, or a specific language such as Spanish or Russian, or just for a specific set of texts, such information is often absent. The goal of our algorithm is to determine the correct parsing of each phrase of the text corpus, having no such information beforehand.
Thus, our procedure has two interrelated goals: first, to determine the correct structure of each phrase of the corpus, and second, to compile a dictionary for such disambiguation. This dictionary depends on the type of the text and on the specific analyzer. As a by-product, a traditional government patterns dictionary is also produced, of course only in the part of the possible and impossible combinations, not in the part of the meaning of actants, while the meaning should be assigned manually to the actants.
In the resulting parsed corpus, each syntactical hypothesis is assigned a weight, which is the probability of this hypothesis to be the true one. As it was explained above, this weight is calculated as a product of the dictionary weights of all the combinations found in it. These products are normalized within the set of hypotheses produced for the same phrase.
The procedure that we use is iterative. It approaches the two goals mentioned above in alternating steps: first it estimates the hypotheses on the basis of the current weights in the dictionary, then re-evaluates the weights in the dictionary on the basis of the current weights of the hypotheses of each phrase, and repeats the process.
The
process starts with an empty dictionary. In the first iteration, for each
phrase, all the hypotheses produced by the parser have equal weights. Then, the
frequencies ![]() and
and ![]() are determined for
each combination found at least once in any of the variants produced by the
parser for the phrases of the corpus. Since at this stage it is unknown which
variants are correct, when determining the number
are determined for
each combination found at least once in any of the variants produced by the
parser for the phrases of the corpus. Since at this stage it is unknown which
variants are correct, when determining the number ![]() of occurrences of the
combination in the correct variants, we sum up the weights wj of each variant j
where the combination was found, since these weights represent the probability
for a variant to be the correct one. Similarly, to determine
of occurrences of the
combination in the correct variants, we sum up the weights wj of each variant j
where the combination was found, since these weights represent the probability
for a variant to be the correct one. Similarly, to determine ![]() we sum up the values
we sum up the values ![]() since this value
represents the probability that the given variant is incorrect. We can
summarize these expressions as follows:
since this value
represents the probability that the given variant is incorrect. We can
summarize these expressions as follows:
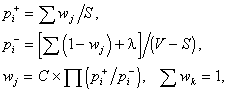
where
S is the total number of sentences, V is the total number of variants, i.e.,
hypotheses, in the corpus. In the first two lines, the addition is done only by
the variants where the combination i
appears; the significance of l
will be explained in the next section. In the third line, the multiplication is
done by all the combinations that appear in the variant j, and the addition is done by all the variants of the structure of
one and the same phrase. The divisors in the first two lines, and the constant C in the third line, are introduced only
for normalization: S is the total
number of correct variants and ![]() of incorrect ones.
of incorrect ones.
To solve this system of equations, we use an iterative method: first the first two lines are calculated, then the third line. When calculating the expression in the third line, we first ignore the constant C, and then divide all the values wj by the sum shown in the third line.
4. Assessing the accuracy of the method by a simulation experiment
To assess the accuracy, convergence, and reproducibility of the results of the method, a simulation program that simulates the process of generating and parsing a text corpus was developed. The main idea is to check if the algorithm will guess correctly both the syntactic structures that the generator “meant” and the dictionary that the generator had in its “mind.” If it does guess them correctly, then there is a hope that it also guesses correctly the structures meant by a human composing a text as well as the dictionary the human has in his or her brain.
Instead of real words and prepositions, just numbers are used. The generator produces random “phrases” according to the frequencies and dictionaries programmed in it. These phrases are generated in the syntactic representation rather than as plain text, in other words, what the generator produces is a sequence of syntactic trees. The frequencies of all the combinations of words and prepositions that the generator uses are known to the researcher, but not to the program that implements our algorithm of dictionary compilation. In our implementation, the frequencies used by the generator for the word and preposition usage, for the number of actants of a word, for the usage of the combinations of actants, etc., generally correspond to the Zipf law.
After the generator produces a phrase, some variants of its interpretation are randomly generated and added to the correct variant to model the generation of “incorrect” variants; we added 20% of all the possible combinations between the given set of words and the given set of prepositions. So the output of the generator contains “hypotheses” of the phrase’s structure, sometimes thousands of them, while exactly one of them is “correct”. The researcher knows which variant was the correct one, but the algorithm does not. The correct hypotheses contain only the combinations that are present in the dictionary built in the generator, while the incorrect ones may, and probably will, contain the combinations absent in it.
These
data, the mixture of the correct and wrong variants, is analyzed by our algorithm.
The algorithm compiles the dictionary and also marks up the corpus with the
probabilities of the variants, thus guessing which variants of the parsing are
the correct ones. Among other data, the dictionary contains the guessed
probabilities ![]() .
.
The results produced by the algorithm can be compared with the true frequencies and true syntactic structures produced by the generator, since all of them are known to the researcher; in particular, the true dictionary of the government patterns used by the generator is known. We consider the number of sentences for which the structure was guessed correctly and the number of dictionary combinations guessed correctly, to be the main indicators of the procedure’s accuracy.
The larger the corpus the better the procedure works. In our experiments, for a dictionary of a total of 1000 words and 100 prepositions and for a corpus of 1000 such artificially generated phrases, the number of correctly guessed variants was 90%, or 87% for the phrases that had more than one variant, that constituted 75% of the corpus, with 161 variants of the parsing per phrase in average. For a “corpus” of only 200 phrases, the accuracy of the procedure was 85%, or 80% on ambiguous phrases only. The convergence of the method was always very good.
While
experimenting with the simulation program, with different “corpora” we tried
different methods of calculations, compared the results, and accounted for the
errors. We observed that a significant cause of errors were the combinations
that appeared in only one or few sentences. Since they never appeared in the
wrong variants, their quotient ![]() reached huge values
and became a cause of errors. Artificial addition of some noise in the form of
a few fictive “occurrences” of each combination in false variants solved the
problem[1].
In the formulae given in the previous section this change is reflected by
introducing an additional constant l.
The value for lproved not to
be critical. The best results were obtained with l»
S, while the values 10 times less or
greater lead to only insignificantly worse results.
reached huge values
and became a cause of errors. Artificial addition of some noise in the form of
a few fictive “occurrences” of each combination in false variants solved the
problem[1].
In the formulae given in the previous section this change is reflected by
introducing an additional constant l.
The value for lproved not to
be critical. The best results were obtained with l»
S, while the values 10 times less or
greater lead to only insignificantly worse results.
Experiments with assignment of the initial weights of the variants did not give so far any better results than just using the equal initial weights, even when the initial weights distinguished well the correct and incorrect variants, e.g., rising the number of phrases initially guessed correctly from 18% to 37%.
We are continuing the experiments with the simulation program. The new experiments will deal with implementation of new features in the generator (word combinations dictionary, control of the length of the phrase and the number of prepositions, linear order, etc.) as well as enhancements to the iterative procedure (dynamic correction of the value of l, playing with the initial weights, etc.).
Conclusions
An ongoing research on development of a linguistic processor for extracting information from texts is being conducted in the NLP Laboratory of CIC, IPN, Mexico City. The processor will heavily rely on the use of large dictionaries of various kinds; some of such dictionaries will be automatically extracted from the text corpora, including the texts retrieved from the Web.
A syntactic parser is currently one of our key goals. One of the principal dictionaries it uses is the dictionary of government patterns. In this article we proposed a technique that allows the automatic compilation of such a dictionary, as well as to resolve syntactic ambiguity in a large text corpus. This techniques is based on the statistics of the use of specific prepositions after specific words. Probably the same procedure with little modifications can be used to automatically learn other types of lexical combinatorial information, such as free word combinations.
We also proposed a new point of view on the dictionary used for ambiguity resolution. Namely, such a dictionary should reflect not only the properties of texts and language, but also the properties of the specific analyzer, in the first place the probabilities for it to make a specific error.
The use of a computer simulation for assessing the results of the parsing and for investigation of different methods was discussed.