I. Bolshakov, A. Gelbukh, S. Galicia Haro. Simulation in linguistics: assessing and tuning text analysis methods with quasi-text generators (in extenso in Russian, with abstract in English). Proc. Annual International Conf. on Applied Linguistics Dialogue-98, November 1998, Moscow, Russia, vol. 2, ISBN 5-900004-20-1 (vol. 2), ISBN 5-900004-21-X, pp. 768-775.
See English text below.
ИМИТАЦИОННОЕ
МОДЕЛИРОВАНИЕ
В
ЛИНГВИСТИКЕ:
ОЦЕНКА И
ОТЛАДКА
МЕТОДОВ
АНАЛИЗА
С ПОМОЩЬЮ
ГЕНЕРАТОРА
КВАЗИТЕКСТА
Игорь
Большаков[1]
Александр
Гельбух[2]
София
Галисия-Аро[3]
Предлагается в процессе разработки и оценки анализаторов текстов использовать искусственно сгенерированные корпуса «квазитекстов». Это позволяет непосредственно моделировать структуры, служащие входными данными разрабатываемого алгоритма, в случае, когда в распоряжении разработчика таких данных нет. При этом можно варьировать различные параметры входных данных. Если разрабатываемый алгоритм предназначен для выявления структуры, не наблюдаемой по тексту непосредственно, то моделирование процесса генерации и последующее сравнение результатов анализа с заложенными в генератор параметрами представляется единственным средством оценки точности работы алгоритма. Описывается генератор квазитекста, использованный для оценки метода автоматического извлечения словаря моделей управления из корпуса текстов.
1. Введение
На необходимость проведения экспериментов для отладки и оценки алгоритмов анализа текста, а также разработки специальных инструментов для этой цели неоднократно указывалось в литературе. В большинстве случаев разработчики ограничиваются проверкой нового метода на достаточно большом корпусе реальных текстов. Однако, как и в программировании, как и в естественных науках, испытания в реальных условиях, то есть на реальных текстах, являются необходимой, но не единственной частью процесса испытаний. Различные методики предлагаются для создания искусственных корпусов текстов, специально предназначенных для испытаний методов анализа текста. Так, в [2] из реального корпуса удаляется часть информации, причем доля и природа удаляемой информации варьируются. В [3] предлагается вручную создавать корпуса примеров, по одному на каждую синтаксическую конструкцию, включая, в целях проверки заложенных в грамматику ограничений, и заведомо неграмматичные конструкции.
Основным недостатком этих методов является их непригодность для оценки глобальных характеристик текста, не наблюдаемых непосредственно и, следовательно, не подлежащих ручной разметке в корпусе. Кроме того, при таком подходе невозможно широко варьировать параметры текста. В данной работе описывается подход, использованный нами при разработке метода разрешения синтаксической неоднозначности, основанного на подсчете числа синтагматических связей определенного вида [1]. Непосредственно генерируется необходимое представление текста, в нашем случае синтаксическая структура, причем моделируются только существенные для алгоритма черты этого представления, что значительно упрощает генерацию и варьирование параметров.
2. Имитационное моделирование при оценке статистических методов
Для проверки статистических методов анализа мы предлагаем подход, основанный на полностью автоматической генерации текста, или, лучше сказать, квазитекста. Такой квазитекст содержит только существенные для процесса анализа характеристики и генерируется в форме, пригодной для непосредственного применения разрабатываемого алгоритма. Так, если разрабатываемый алгоритм основан на учете определенных характеристик синтаксических деревьев, то генератор квазитекста подает на его вход уже готовые синтаксические структуры. Они не содержат ни конкретных лексем, ни их морфологических характеристик, ни определенного порядка слов, не говоря уже о каком-либо смысле. Узлы этих структур помечены числами вместо лексем, вид структуры выбирается случайным образом. При генерации учитываются только существенные для разрабатываемого метода статистические характеристики, например, частоты появления определенных связей и «лексем», статистическое распределение числа узлов и т.д.
Методика экспериментов и структура генератора зависят от целей и структуры алгоритма, для проверки которого они предназначены. В нашем случае алгоритм предназначался для построения словаря моделей управления (МУ) по корпусу текстов и одновременного разрешения синтаксической неоднозначности в этом корпусе [1]. Словарь МУ является частью стратегии генерации текста, не наблюдаемой по тексту непосредственно. Поэтому для оценки качества составленного словаря недостаточно было использовать, скажем, размеченный вручную корпус текстов — нужен был бы «образцовый» словарь МУ, а его составление как раз и было задачей разрабатываемого метода. Ввиду статистической природы алгоритма эксперименты на корпусе из нескольких фраз, для которых такой словарь можно построить вручную, были бы неубедительны.
Ситуация усугублялась тем, что разрабатываемый метод разрешения неоднозначности существенно использовал характеристики анализатора — частоты и типы совершаемых им ошибок. Следовательно, для проверки на реальном корпусе нужен был бы большой синтаксически размеченный корпус, а также конкретный синтаксический анализатор. К сожалению, нам неизвестны такие корпуса для испанского языка, с которым мы в настоящее время работаем, да и для русского тоже. Но даже если бы они у нас и были, варьирование параметров в реальном тексте, а также грамматики было бы затруднительно. К тому же нам необходимо было убедиться в работоспособности метода до начала работ по созданию синтаксического анализатора. Поэтому мы построили модель генератора текста и синтаксического анализатора. Общая схема нашей системы показана на ¡Error! Argumento de modificador desconocido..
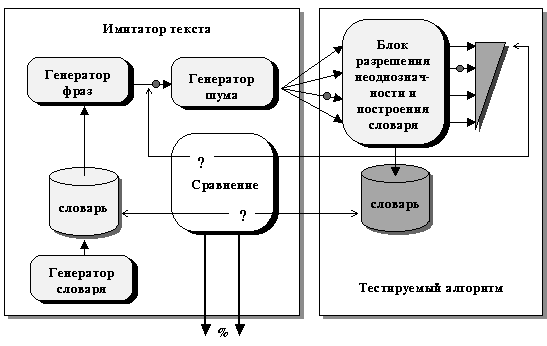
Рис. 1. Схема тестирования алгоритма разрешения неоднозначности.
Собственно моделью генерации текста является генератор фраз. Он выдает независимые фразы, точнее, готовые синтаксические структуры, на основе заложенной в него стратегии генерации текста, опирающейся на словарь МУ. Моделью синтаксического анализатора является генератор шума. Он имитирует характерные ошибки синтаксического анализатора путем добавления к построенной генератором фраз «истинной» структуре нескольких «ложных» структур. На его выходе появляется типичный для синтаксического анализатора набор альтернативных вариантов синтаксической структуры.
Эти данные подаются на вход тестируемого алгоритма. Этот алгоритм назначает отдельным вариантам веса, его цель — угадать, какой из них был на самом деле сгенерирован генератором фраз. На ¡Error! Argumento de modificador desconocido. эти веса показаны в виде треугольной диаграммы, наибольшая толщина соответствует варианту, получившему наилучшую оценку. Кроме того, при его работе строится словарь МУ. Цель алгоритма снова — угадать, какой словарь МУ использовал генератор фраз, в том числе найти вероятность употребления каждого отдельного сочетания. В этот словарь включаются и частоты типичных ошибок синтаксического анализатора. Подробно описание работы алгоритма см. в [1].
Затем система сравнивает полученные результаты с априорно известными. Так, вариант, получивший наилучшую оценку, сравнивается с вариантом, на самом деле сгенерированным генератором фраз (на Рис. 1 он помечен жирной точкой). Далее, словарь, полученный в результате работы тестируемого алгоритма, сравнивается со словарем, на самом деле используемым генератором фраз[4]. Кроме того, используется второй корпус текстов, не показанный на Рис. 1, сгенерированный тем же генератором фраз и генератором шума, но, возможно, с несколько другими параметрами. После каждой итерации этот второй корпус анализируется с помощью словаря, построенного алгоритмом на данный момент по первому корпусу. Оценка результатов анализа дает представление о возможности использования словаря, созданного по одному корпусу, для разрешения неоднозначности в другом корпусе.
В экспериментах мы пробовали различные сочетания параметров генерации обучающего и тестового корпуса, а также различные схемы подсчета статистических весов в разрабатываемом алгоритме. Наибольшие проблемы доставлял попадающий в словарь мусор из наиболее редких сочетаний. Мы пробовали различные варианты учета этих редких сочетаний и пришли к необходимости добавлять к каждому сочетанию некоторое число l вхождений в ложные варианты, что во много раз улучшило точность работы алгоритма. Оптимальное значение этой константы было подобрано экспериментально с помощью автоматического перебора с некоторым шагом. Автоматически же были получены графики зависимости точности работы алгоритма от различных параметров текста, синтаксического анализатора и самого алгоритма.
3. Генерация квазитекста и искусственного словаря МУ
В этом разделе описываются приемы, использовавшиеся нами при генерации квазитекста и искусственного словаря МУ. Всюду, где возможно, мы использовали закон распределения Ципфа, состоящий в том, что в ряду значений случайной величины, упорядоченных по вероятности появления, вероятность появления n-го значения пропорциональна 1/n. Для вычисления значения случайной величины, распределенной по Ципфу в полуинтервале [0, N), мы использовали приближенную функцию Zipf (N) = 0.56 (1.786 N + 0.893)R – 0.5, где R — равномерно распределенная на отрезке [0, 1] случайная величина[5].
Моделью синтаксической структуры фразы в интересующем нас случае являлся набор номеров лексем со списком «зависимых» от каждой лексемы предлогов (поскольку мы работали с испанским языком, падежи мы не учитывали, но их введение не представляет никакой трудности). Вот пример типичной фразы: Word13 ® prep7; Word0; Word874 ® prep0, prep31; Word73; Word2. Данная фраза содержит 6 «значимых» слов и 3 предлога, в данном случае нас интересует только привязка предлогов к управляющим словам и не интересует привязка управляемых слов к предлогам. Порядок слов во фразе нас также не интересует, однако порядок предлогов, связанных с конкретным словом, является существенным.
Генерация словаря МУ. Поскольку модель должна быть проверена с разными вариантами заполнения словаря, словарь генерировался автоматически. Сначала для каждого слова выбиралось количество актантов, мы использовали закон Ципфа в интервале от 0 до 5, поскольку реальное распределение для данного языка нам не было известно. Таким образом, наибольшее число слов вообще не имело валентностей. Затем для каждого актантного места определялось число возможных предлогов, мы снова использовали закон Ципфа в интервале от 1 до 3, хотя такой выбор и не является лингвистически обоснованным. Затем выбирались предлоги, оформляющие актантные места, вновь по закону Ципфа. Мы считали, что список предлогов упорядочен по частоте, поэтому функция Zipf (P), где P — число предлогов в языке, непосредственно давала номер предлога. С вероятностью 40% актант объявлялся обязательным, то есть отмечалось, что при данном слове обязан присутствовать ровно один из предлогов, оформляющих данную валентность, см. ¡Error! Argumento de modificador desconocido..

Рис. 2. Статья
искусственного
словаря МУ.
Частоты
сочетаний
обратно
пропорциональны
их номерам.
После этого моделировались ограничения на совместимость способов выражения актантов — из всех возможных сочетаний предлогов по одному из каждого актанта (с учетом того, что необязательные валентности могут опускаться) отбирались некоторые сочетания с 80%-й вероятностью, и составлялся список возможных сочетаний данного слова с различными предлогами. Варианты сочетаний в этом списке перемешивались случайным образом, что имитировало назначение им частот употребления по закону Ципфа, поскольку именно этот закон использовался алгоритмом генерации фраз при выборе сочетания из данного списка, как это описано ниже.
Генерация
фразы. При
генерации
фразы
сначала
выбиралась длина
фразы l.
Мы использовали
формулу,
зависящую от
трех параметров:
m,
определяющего
минимальное
значение, a — среднее
значение и w —
дисперсию,
например, m = 2, a = 4, w = 2.
Формула
имела вид l = m + (a – m)![]() при h ¹ 0, l =
a при h = 0, где h —
нормально
распределенная
случайная величина,
то есть 6
минус сумма
12-и равномерно
распределенных
на отрезке [0, 1]
случайных
величин.
Далее
выбирались
слова,
входящие во
фразу, и
связанные с
ними предлоги.
Мы снова
считали, что
словник
упорядочен
по частоте,
поэтому
функция Zipf (W),
где W —
число слов в
словнике,
непосредственно
давала номер
очередного
слова. Таким
образом,
слово Word0 было
самым
частотным
словом во «фразах»,
Word1 — вдвое
более редким,
Word2 — втрое и т.д.
Из хранящегося
в словаря МУ
массива
возможных для
данного
слова
сочетаний
предлогов,
см. Рис. 2,
выбиралось
одно из
сочетаний,
при этом мы снова
использовали
функцию Zipf (С),
где C —
число
сочетаний,
возможных
для данного слова,
хотя опять же
ее
использование
здесь вряд ли
лингвистически
оправдано.
при h ¹ 0, l =
a при h = 0, где h —
нормально
распределенная
случайная величина,
то есть 6
минус сумма
12-и равномерно
распределенных
на отрезке [0, 1]
случайных
величин.
Далее
выбирались
слова,
входящие во
фразу, и
связанные с
ними предлоги.
Мы снова
считали, что
словник
упорядочен
по частоте,
поэтому
функция Zipf (W),
где W —
число слов в
словнике,
непосредственно
давала номер
очередного
слова. Таким
образом,
слово Word0 было
самым
частотным
словом во «фразах»,
Word1 — вдвое
более редким,
Word2 — втрое и т.д.
Из хранящегося
в словаря МУ
массива
возможных для
данного
слова
сочетаний
предлогов,
см. Рис. 2,
выбиралось
одно из
сочетаний,
при этом мы снова
использовали
функцию Zipf (С),
где C —
число
сочетаний,
возможных
для данного слова,
хотя опять же
ее
использование
здесь вряд ли
лингвистически
оправдано.
Добавление шума. Блок добавления шума представляет собой модель синтаксического анализатора, строящего кроме правильной несколько, возможно, много, неправильных структур. После того, как фраза была сгенерирована, к ней добавлялись «ошибочные» варианты разбора путем перемешивания присутствующих в ней предлогов. Например, следующий «ошибочный» вариант строился по приведенной выше «фразе»: Word13 ® prep0; Word0 ® prep31; Word874; Word73 ® prep7; Word2. Для этого рассматривались все возможные сочетания данных слов с данным набором предлогов, и из них отбирались некоторые, поскольку моделируемый синтаксический анализатор строит не все возможные варианты структуры. В данном случае мы просто оставляли сочетания, выбранные случайно с 20%-й вероятностью. На всякий случай варианты перемешивались. Слишком длинные фразы отбрасывались из-за технических ограничений. Исходная фраза всегда включалась в набор вариантов, то есть мы полагали, что синтаксический анализатор всегда строит правильную структуру, но кроме нее, сколько-то неправильных. Полученный таким образом набор вариантов подавался на вход тестируемого алгоритма.
4. Результаты экспериментов
Как уже говорилось, разработанный нами имитатор текста предназначался для оценки и отладки алгоритма построения словаря МУ и разрешения синтаксической неоднозначности. Мы генерировали два корпуса текста, первый использовался для итеративного обучения алгоритма — построения словаря, второй — для проверки точности алгоритма разрешения неоднозначности с помощью словаря, построенного по первому корпусу. Эти два корпуса строились на основе одного и того же словаря МУ или слегка разных.
В экспериментах мы подбирали различные выражения для подсчета весов вариантов и сочетаний, а также различные значения параметров. Методика экспериментов в этих двух случаях была разной. Подбор параметров выполнялся автоматически: значение параметра менялось с некоторым шагом, и весь процесс испытаний автоматически повторялся. Программа запоминала значение параметра, при котором был достигнут наилучший результат, а также строила график зависимости точности работы алгоритма от варьируемого параметра. Например, таким образом было найдено, что значение упомянутого в [1] параметра l должно быть примерно равно числу фраз в корпусе. График показывает, что точность мало зависит от значения l в пределах примерно 10-кратного отклонения от оптимального, однако катастрофически падает при нулевом или очень большом значении. При этом было проверено, что характеристики самого корпуса слабо влияют на оптимальное значение l.
Подбор формул подсчета весов проводился вручную. При каждом изменении формулы строился график зависимости точности метода от номера итерации. В определенных случаях наблюдались графики с описанным в [2] поведением «ранний максимум»: после нескольких итераций достигалась максимальная точность, однако затем она постепенно или быстро падала. От таких вариантов метода пришлось отказаться, поскольку при работе на реальном тексте предсказать число итераций до достижения максимума не представляется возможным или, во всяком случае, мы пока не нашли, как это сделать. Напротив, при других формулах расчета состояние алгоритма стабилизировалось или, по крайней мере, оставалось достаточно стабильным после многих десятков итераций. В таком варианте метод и изложен нами в [1].
При каждом эксперименте нам предъявлялся автоматически построенный протокол расхождений результатов работы алгоритма и «реальных» параметров, заложенных в генератор квазитекста, что значительно облегчало анализ результатов. Возможно, дальнейшие эксперименты помогут выявить причины отдельных расхождений и найти способы улучшения методики подсчета. Интересно было бы понять причины падения точности после достижения «раннего максимума» и найти возможность определять номер итерации, на которой этот максимум достигается.
5. Заключение
Предлагаемая методика позволяет автоматически генерировать корпуса текстов с заданными параметрами, предназначенные для отладки и оценки точности работы алгоритмов анализа текста. Мы видим следующие преимущества данного метода по сравнению с использованием для этой цели только размеченных вручную реальных корпусов текстов:
· При моделировании внутренние параметры модели, не наблюдаемые непосредственно по тексту, такие, как стратегия генерации, словари сочетаемости и т.д., непосредственно доступны исследователю и могут сравниваться с результатами работы алгоритма, в то время как получение таких данных для реального языка является либо отдельной задачей будущего для психолингвистики, либо как раз целью разработки тестируемого алгоритма.
· При моделировании текста можно варьировать его структуру, или «жанр» — размер словаря, длину фраз, степень однородности и т.д., проверяя тестируемый алгоритм на устойчивость работы с разными «жанрами». Можно также выяснять зависимость определенных параметров алгоритма от параметров входного текста, отметая случайные совпадения.
· Реальный размеченный корпус может просто отсутствовать или быть недоступным исследователю, особенно при разработке методов анализа для какого-либо языка, кроме английского, или может отсутствовать корпус с ручной разметкой нужного типа.
· Моделирование позволяет построить непосредственно нужную структуру текста, например, синтаксическую, минуя поверхностную и морфологическую, причем со всеми «недостатками» реальных результатов синтаксического анализа. Например, для отладки на реальном тексте алгоритма разрешения синтаксической неоднозначности кроме размеченного вручную корпуса текста — информации о «правильной» структуре — необходим еще и собственно анализатор, вносящий эту неоднозначность. В этом случае моделирование может помочь доказать работоспособность метода еще до дорогостоящей разработки самого анализатора, и тем самым убедить как себя, так и руководство в самой необходимости развертывания работ по созданию синтаксического анализатора.
Естественно, моделироваться должны только процессы, существенные для тестируемого алгоритма. Так, в нашем случае процесс назначения предлогов управляющим словам и его частотные характеристики тщательно моделировались, в то время как, скажем, длина фразы, очевидным образом связанная со структурой словаря МУ и легко выводимая из процесса формирования фразы, задавалась непосредственно, поскольку для нашего алгоритма механизм, определяющий длину фразы, был несущественен, а реалистичное ее значение — существенно. В заключение необходимо еще раз подчеркнуть, что моделирование не заменяет тестирования на реальных текстах, а служит этапом подготовки к нему.
Литература
SIMULATION
IN LINGUISTICS:
ASSESSING
AND TUNING TEXT ANALYSIS METHODS
WITH QUASI-TEXT GENERATORS
Igor Bolshakov
Alexander Gelbukh
Sofia Galicia-Haro
An experience of using an artificially generated text corpus in development of a statistical method of syntactic disambiguation and dictionary learning [1], as well as the structure of the generator used is described. Using an artificially generated text corpus as a testbed for statistical methods has the following advantages over the use of just manually marked up real text corpora, or degraded corpora [2], or manually compiled sets of examples [3]: (1) the internal structures underlying the generation process, such as combinatorial information, are available and can be compared with the ones guessed by the algorithm being developed, while in the real text corpus they are not observable, (2) the parameters of the test corpus can be widely varied, to check the robustness of the algorithm, (3) the real text corpora might not be available for a given language or with the markup of the necessary type, (4) with simulation, the input data for the algorithm can be generated immediately in the necessary form, e.g., in the form of syntactic structure, bypassing the surface and morphological ones. The latter is useful when the very plans of the development of, let us say, the syntactical analyzer depend on the success of the method being assessed.