A. Gelbukh, S. Galicia-Haro, I. Bolshakov. Three dictionary-based techniques of disambiguation. Proc. TAINA-98, Workshop on Artificial Intelligent, 1998, CIC-IPN, Mexico D.F., ISBN 970-18-2057-6, pp. 78 - 89.
Three dictionary-based
techniques
of disambiguation
Alexander F. Gelbukh
Sofía Natalia Galicia Haro
Igor A. Bolshakov
Centro de Investigación en Computación, Instituto Politécnico
Nacional,
Av. Juan de Dios Bátiz, A.P. 75-476, C.P. 07738, México D.F.,
+52 (5) 729-6000, ext. 56544, 56602, fax 586-2936,
{gelbukh, sofia,
igor}@pollux.cic.ipn.mx, gelbukh(?)micron.msk.ru
Abstract
It is argued for that ambiguity resolution is one of the most important and difficult tasks in the modern applied linguistics. All the methods of ambiguity resolution are heuristical, so as many as possible methods should be used in each case to resolve ambiguity, and different dictionaries should “vote” for each variants. Three such methods are discussed, namely, the methods based on a government patterns dictionary, on a word combinations dictionary and on a semantic network dictionary. The authors took part in development of all the three kinds of dictionaries, though for different languages: Spanish, Russian, and English.
Introduction
As it is well known, the area of intelligent text processing includes three major parts: morphology and lexicography, syntax, and semantics. In each of these areas the methods of determining of the corresponding structure are studied:
· Morphology studies the methods of determining what words are used in the text,
· Syntax studies the methods of determining of the structure of the phrases,
· Semantics studies the methods of determining of the concepts mentioned in the text and their relationships.
In each case, the result can be ambiguous. For example, the Spanish word form fue can be understood as the word ir or ser. In fact the task of choosing the correct variant is much more difficult than that of determining all the possible variants. The difference is in that the possible variants are determined by the methods studied within the corresponding science, e.g., the both interpretations for fue can be found by morphological methods. On the contrary, to choose the correct variant one should employ the methods of much deeper nature, often semantic. Thus ambiguity resolution is “external” with respect to each area (such as morphology), while determining all the variants is its “internal,” direct task.
Now that the main “internal” problems of morphology and even syntax per se can be generally considered solved enough, there is little success in the area of ambiguity resolution, which is, as we have noted, an interdisciplinary task. This makes ambiguity resolution one of the most difficult but at the same time most important problems at the current state of applied linguistics [6].
Types of ambiguity
Syntactic ambiguity
A phrase is syntactically ambiguous if there are several possible interpretations of the syntactic connection between the words in the phrase. For example, the phrase The man sees a cat with a telescope is ambiguous. Four of the possible interpretations of the phrase are shown in Fig. 1.
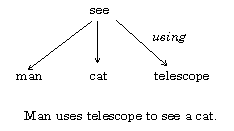
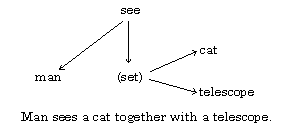
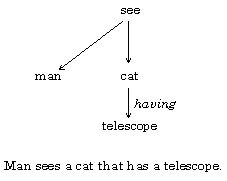
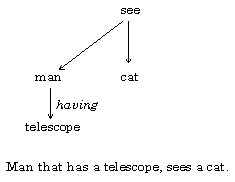
Fig. 1. Variants of the syntactic structure of a phrase.
The correct variant is the first one (‘man uses the telescope to see the cat’), but the choice can not be done basing on only syntactic criteria.
Spanish in many cases presents more problems with syntactic ambiguity than some other languages, since it does not have neither fixed word order like English, nor a system of morphological cases like Russian.
Lexical ambiguity
A word is ambiguous if there are several possible variants of its semantic interpretations in the phrase, i.e., the word form is homonymous. For example, a pocket Spanish-English dictionary lists the following meanings of the Spanish word gato: cat, moneybag, jack, sneak thief, trigger, outdoor market, hot-water bottle, blunder.
Thus, the Spanish phrase Veo un gato is ambiguous: it is not clear whether the object is a cat, or a jack, etc. This ambiguity generally can not be resolved. However, in a more specific context, like El gato capturó un ratón, the ambiguity can be resolved by taking into account some additional information, i.e., by an analysis other than purely lexical.
Referential ambiguity
Referential ambiguity, in the simplest case, arises from the use of pronouns. Each pronoun (or zero subject in Spanish) refers to some word, usually mentioned previously in the text: John took a cake from the table. It was sweet. = The cake was sweet; Juan tomó un pastel de la mesa. Fue dulce. = El pastel fue dulce.
The task arises to choose the correct word to substitute for the pronoun or zero subject. How can be the word pastel preferred over the words mesa and even Juan in the previous example: *La mesa fue dulce; *Juan fue dulce?
Zero subjects in Spanish present more problems than pronouns in some other languages. For example, in English phrase The man sees a cat with a telescope. It is furry. there are two possible candidates for it: cat and telescope, but not man. In the corresponding Russian phrase Chelovek vidit koshku v teleskop. Ona pushistaja. the only possible candidate for ona is koshka (cat) since it is the only feminine word in the text, and the pronoun is feminine. However in the Spanish phrase El hombre ve un gato con el telescopio. Es peludo. all the three nouns are possible candidates for the subject of es.
Ambiguity resolution
To analyze a text, one should relate the text with some specific dictionary entries, find some structure in the text, add the information present in the text implicitly. Of course, such an analysis should generate exactly one result. However, when the text has ambiguous elements, several or many possible variants of its structure are built during its analysis, but one does not know which variant is the correct one, so that no one variant can be chosen as the result of analysis. To really analyze the text, we need to resolve ambiguity, i.e., choose one of the variants.
As we have seen, ambiguity can be resolved only by taking into account the context and by addressing to knowledge more specific than syntactic rules, or rules of agreement in gender and number for pronouns, etc. Usually the necessary knowledge is of lexical nature, i.e., specific for individual words. Thus, comprehensive dictionaries should be used for ambiguity resolution.
The general scheme of using the dictionaries for ambiguity resolution is the same for different dictionaries:
· Locate the differences between variants;
· For each difference, verify the relationships of the word or link in question to the context by the dictionary;
· For each variant, count the number of words or combinations found in the dictionary;
· Choose the variant with the greatest number of words or combinations found in the dictionary.
It quite can happen that in one variant some words or combinations are better, and in another variant other words are better. The decision is made by “voting” of the words: the best variant contains more words found in the dictionary. What is more, it can happen that according to one dictionary some variant is better than others, but according to another dictionary another variant is better. Again, the decision is made by “voting” of the methods and dictionaries. Since most of the methods of ambiguity resolution are heuristical and not very much reliable, the more methods are tried the better.
In this work we describe three such possible “voters:”
· Government patterns dictionary,
· Word combinations dictionary,
· Semantic network dictionary.
In each case, all or some of them should be used and the results combined to make the final decision.
GPD: Use of syntactic government patterns dictionary
What is GPD
The first dictionary useful for ambiguity resolution we will consider is a syntactical government patterns (or subcategorization frames) dictionary (GPD). In simple words, this dictionary lists the prepositions required, or governed, by some words. The use of prepositions is especially important for Spanish, since nearly all the syntactic relationships are expressed in Spanish by prepositions (English uses, let us say, attributive constructions; Russian uses grammatical cases, etc.).
The authors have developed a Spanish dictionary that for the most frequent verbs, nouns, and adjectives lists their valences (so-called actants) and the prepositions[1] that marks these valences in the texts [4]. Fig. 2 shows an example of the dictionary entry (N stands for noun, na stands for not animate, an stands for animate).
expresar
X expresses issue Y to person W by means of Z
|
Number |
Government pattern |
Example |
|
X = 1 who / what expresses? |
||
|
1.1 |
N |
la sociedad civil / oración ~ |
|
Y = 2; what? |
||
|
2.1 |
N (na) |
~ su posición / sentido |
|
W = 3; to whom? |
||
|
3.1 |
a N (an) |
~ a sus compañeros |
|
Z = 4; by means of what? |
||
|
4.1 |
en N (na) |
~ en las urnas |
|
4.2 |
mediante N (na) |
~ mediante palabras simples |
|
4.3 |
con N (na) |
~ con sus propias palabras |
|
POSIBLE: |
|
|
|
1 0 2 |
La sociedad civil expresó su posición. |
|
|
1 0 2 3 |
Ella expresó su sentir a Juan. |
|
|
1 0 2 3 4 |
El señor expresó su pésame a los familiares con pocas palabras. |
|
|
1 0 2 4 |
La oración expresa un sentido amplio mediante palabras simples. |
|
|
0 2,0 2 3, 0 2 4, 0 2 3 4 (The other examples are omitted for brevity) |
|
|
|
IMPOSIBLE: |
|
|
|
1 0 |
*La sociedad civil expresó. |
|
|
1 0 3 |
*La sociedad civil expresó a los demás. |
|
|
0 |
*Expresa. |
|
|
0 3 |
*Expresó a sus compañeros. |
|
|
1 0 4, 0 4, 1 0 3 4, 0 3 4 (The other examples are omitted for brevity) |
|
|
Fig. 2. A government patterns dictionary entry.
Now we are also compiling a similar dictionary with the frequencies of the corresponding combinations.
Syntactic disambiguation with GPD
The government patterns dictionary is intended mostly for syntactic disambiguation, namely, for the most common and difficult-to-resolve type of syntactic disambiguation: prepositional phrase attachment.
Here are some examples of Spanish ambiguous phrases: encontrarse con el director del Instituto, enredar al hermano de Miguel en una intriga. In the first phrase, it is not clear whether del Instituto is connected with encontrarse or director. However, the dictionary has an entry director de ... but not encontrarse de ..., that helps to resolve the ambiguity. In the second example, the dictionary has the entries hermano de ... and enredar en ..., that helps to eliminate the wrong interpretations *enredar de Miguel, *hermano en intriga.
Lexical disambiguation with GPD
Lexical disambiguation with GPD is based on the differences between the government patterns of the homonymous words. For example, the Spanish word proceder has several meaning: ‘bring someone to trial’, ‘originate from somewhere’, etc. They can be distinguished in the contexts proceder contra alguien = ‘bring someone to trial’, proceder de algo = ‘originate from somewhere’ since their government patterns are different, i.e., they form different entries in the dictionary.
Another example: te cargadoversus el jefe cargado del trabajo. Only one of the homonyms of the word cargado can be used without preposition, and only the other can be used with de.
Referential disambiguation with GPD
The referential ambiguity in some cases can be resolved by the same mechanism as the lexical ambiguity. For a pronoun in question, each of the possible candidates is tried, and the resulting word combinations are checked against the dictionary.
Let us consider an exampleMi hermana oyó una plática de ciencia y una sobre educación. The possible candidates for the pronoun uno are hermana, plática, ciencia, that results in the hypothetical combinations hermana sobre …, plática sobre …, ciencia sobre … The only combination present in the dictionary is plática sobre …, that allows to choose the interpretation of una as plática.
CrossLexica™: Use of word combinations dictionary
What is CrossLexica™
The second type of the dictionaries useful for disambiguation tasks are the dictionaries of word combinations. These dictionaries contain information about the occurrences of pairs of words in texts, e.g., good idea (but not *green idea), deep sleep (but not *furiously sleep), idea works (but not *idea sleeps)[2].
The simplest type of such information is just binary: whether or not a given pair of words occurs in texts, or at least occurs with a sufficient frequency. In more detailed computer dictionaries, the frequency of occurrences is given. Such dictionaries are used in so-called lexical attraction parsing models [11].
The dictionaries of this type provide more detailed information than the government patterns dictionaries, since for a given word they list not only the prepositions, but all the words that can appear together with the given one in a text, or, more precisely, that can be syntactically connected with the given one in a phrase.
On the other hand, such a dictionary is simpler than a thesaurus or a lexical functions dictionary (we describe these in the next sections), since they do not indicate the type of the relationship between the given two words. Thus such a dictionary is much easier to compile than a thesaurus. In fact such a dictionary can be extracted from a large enough corpus of texts.
As an example of a word combinations dictionary, we will consider the CrossLexica™ dictionary compiled by some of the authors for Russian language; now we are planning to develop a similar dictionary for Spanish, see Fig. 3.
Fig. 3. A fragment of the CrossLexica™ word combinations dictionary.
The dictionary consists of two parts. The main part are word combinations. Additionally, the dictionary contains a simple thesaurus that includes synonyms, more general words (Paris is-a city), parts (book has-a-part page), etc. The thesaurus is used to automatically generate more hypothetical word combinations not included in the dictionary directly, e.g., to walk around Paris (from to walk around a city), page of a book, etc.
Here are some examples of Spanish word combinations: junta de gobierno, poner atención (not *pagar atención), café cargado (not *café duro), gato peludo, ver con telescopio.
The Russian dictionary now contains more than half million word combinations, as well as about half million relationships of the thesaurus, that can generate about 20 million hypothetical word combinations [1, 2]. We expect similar figures for the Spanish version.
Syntactic disambiguation with CrossLexica™
Though most of our experience with this type of dictionaries is related to Russian, we will describe the examples from English, since there is nothing language-specific in the examples. Let us consider again the phrase The man sees a cat with a telescope.
To resolve the ambiguity, it is enough to note that the combination see with a telescope is present in the word combinations dictionary, while *cat with a telescope is not. This observation gives more chances to the first variant of the analysis: ‘The man uses the telescope to see the cat’ rather than ‘The man sees a cat that has a telescope’.
If the variants differ in several links, each link under the question is checked against the dictionary, and the variant is chosen that has a greater number of links present in the dictionary.
In lexical attraction parsing schemes [11], i.e., if the dictionary provides also the frequencies of the combinations, the variants are assigned weights according to the frequencies of the combinations rather than simple yes-or-no judgments. If both combinations see with a telescope and cat with a telescope are present in the dictionary but the frequency of the first one is greater than that of the second one, then the first variant of the analysis is assigned a better weight.
Lexical disambiguation with CrossLexica™
We suppose that the homonyms in the word combinations dictionary are distinguished, e.g., for any occurrence of the Spanish word gato it is indicted which of its senses is meant, like gatocat or gatojack.
Let is consider again the example Veo un gato peludo, with the ambiguous lexem gato: ‘cat’ or ‘jack’. The word combinations in which the word under question participates are checked against the dictionary. Since the combination gato peludo is present in the dictionary with the sense mark gatocat, the first variant of analysis should be chosen. If in the dictionary there are several combinations with the given word, the decision is made by choosing the variant that agrees with the dictionary in a greater number of the combinations. In case of lexical attraction dictionary, their frequencies are combined.
Other Spanish examples: té cargado, el jefe cargado del trabajo. The dictionary contains the combinations té cargadostrong and cargadoresponsible del trabajo.
Referential disambiguation with CrossLexica™
As in the section on the government patterns, the referential ambiguity can be resolved in some cases by substitution the pronoun in question with each candidate and checking the resulting combinations against the dictionary.
Let us consider an example: Mi hermano puso un café ligero en el escritorio y uno cargado. Possible candidates for uno are hermano, café, escritorio, that results in the possible combinations hermano cargado, café cargado, escritorio cargado. Only the combination café cargado is present in the dictionary of word combinations. In the lexical attraction dictionary other combinations might be present as well, but the frequency of the combination café cargado would be greater than those of the other combinations.
FACTOTUM® SemNet™: Use of a semantic network dictionary
What is FACTOTUM® SemNet™
The most sophisticated type of the dictionaries considered in this articles is a thesaurus. This dictionary lists the words related by meaning and specifies the type of the relationships between them. The related words do not need to (and in most cases do not) appear in the texts together, instead, their relationships reflect the commonality in their meaning or in the situations in which the referred concepts participate.
Here are several example of the pairs of related words, along with the type of their relationships: cat IS-A animal, cat CAN USE mouse, cat DESTROYS mouse, telescope IS-TOOL to see, telescope IS-A object, animal CAN HAVE object, etc. It is convenient to represent a thesaurus in the form of a graph, see Fig. 4.
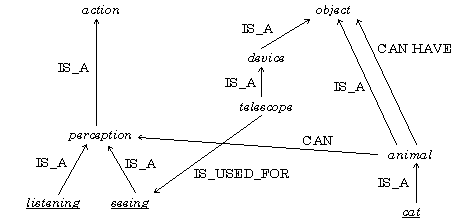
Fig. 4. A fragment of the thesaurus.
A thesaurus represents “common knowledge” of people about the standard situations. It is considered that for good results in text understanding of the general language, a thesaurus should contain 1 to 10 million individual links.
Two of the authors have participated in the project of P. Cassidy of MICRA, Inc. aimed on development of a large-scale thesaurus of English [3]. The FACTOTUM® SemNet™ thesaurus includes now about 150 thousand concepts and about 120 thousand links other than of IS-A type (clearly it includes about 150 thousand links of IS-A, at least of for almost each concepts). The authors have an experience of translation of this thesaurus into Russian; now we are planning to develop a similar recourse for Spanish.
Syntactic disambiguation with FACTOTUM® SemNet™
We will first need a concept of a path in a semantic network. A path is a chain of relationships, e.g., the chain programmer USES computer, computer HAS-PART disk, disk CONTAINS information represents one of the possible paths between the concepts programmer and information. A path is a complex relationship. In other words, they are relationships implicitly present in the thesaurus. Though there is no relation between programmer and information included directly in the thesaurus, it can be inferred, by finding the path, that these two words are related.
The shorter is the path between two words, the closer they are related. Thus, really interesting are the shortest paths between two words. Of course, not only one, the shortest, path is of interest, since other short enough paths represent other types of relationships. However, the path much longer than the shortest one are of little interest.
What is more, any two words in the thesaurus can be connected with a path. However, all paths between some words are long, while some other words can be connected with short paths. Thus, the length of the shortest path in the network between the two given words can be used as a measure of their semantic closeness. To make this measure more precise, some types of the links should be considered “longer” than others. For example, IS-A is a very close link, while CAN HAVE is “long” enough, i.e., does not indicate much closeness between the concepts.
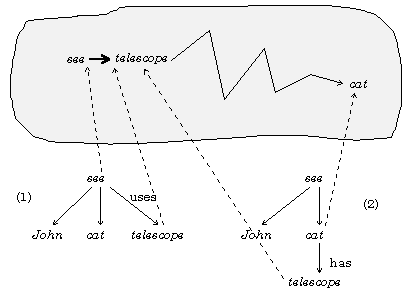
Fig. 5. Disambiguation with paths in semantic network.
This measure can be used for disambiguation. Let us again consider the example The man sees a cat with a telescope with the two variants of the structure: ‘uses telescope to see’ versus ‘cat that has a telescope’. In Fig. 4 we can see that there is a short path between see and telescope: one TOOL relationship. There is also a path between cat and telescope: cat IS-A animal, animal CAN HAVE object, telescope IS-A object. However, this second path is longer, indicating less degree of closeness between the concepts cat and telescope than between see and telescope, see Fig. 5. Thus, the first variant should be chosen.
Lexical disambiguation with FACTOTUM® SemNet™
Semantic networks have been used for word sense disambiguation by a number of researchers [7, 8, 9, 10]. The process of lexical disambiguation with a semantic network is quite similar to the use of the other types of dictionaries. We suppose that the individual senses of the homonymous words are marked in the thesaurus, e.g., gatocat DESTROYS ratónanimal, gatojack IS-TOOL elevar, computadora HAS-PART ratóndevice.
To disambiguate a word, the distance between each sense of this word and the surrounding words should be measured. The sense close enough to some of the surrounding words should be chosen. Let us consider the same Spanish example: Veo un gato con pelo largo. In the thesaurus, there is a short enough path between gatocat and pelo: gatocat HAS pelo, but the shortest path between gatojack and pelo (such as jack is used with a car, car can have a cover inside, cover can have fur) is much longer, i.e., worse.
Another example: Conecto un ratón a mi computadora. The path between computadora and ratóndevice is shorter than between computadora and ratónanimal.
A useful modification of this method is using the distance between the word in question and the principal topic of the text or its part such as the paragraph. The principal topic of the text can be determined with the system CLASITEX developed in our Center [5]. The use of the principal topics instead of all the surrounding words reduces the number of comparisons necessary for the algorithm and in some cases allows to better take into account the wide context.
Ideally both methods should be used: if the near context does not provide reliable enough information, i.e., all the tried paths prove to be too long, or the phrase is too short so that there are too little word pairs, then the wide context should be taken into account, first the paragraph, then, if the ambiguity is not yet resolved reliably, the greater units or the whole text.
Referential disambiguation with FACTOTUM® SemNet™
As in the previous sections, to resolve the referential ambiguity, we try to substitute the pronoun in question with each candidate and assess the quality of the resulting combinations with the same procedure as we use for lexical disambiguation. In the case of the use of a thesaurus, we assess the quality of the variants by comparison the word with the surrounding words or with the principal topics of the text.
Let us consider an example: The man sees a cat with a telescope. It is furry. The possible candidates for it are: man, cat, telescope. The resulting phrases are: man is furry, cat is furry, telescope is furry. The semantic distance, i.e., the length of the path, between cat and fur is the closest, thus, it here is cat.
Conclusions
Ambiguity is the most difficult problem of computational linguistics. It can be resolved by “voting” of different methods of analysis. Special dictionaries of combinatorial type, those that give the information for more than one word, can help in this task. Three dictionaries useful for ambiguity resolution were discussed:
· Government patterns dictionary,
· Word combinations dictionary,
· Semantic network dictionary.
Each of the discussed methods proved to be useful in the resolution of syntactic and lexical ambiguity. What is more, the methods of lexical ambiguity resolutions proved to be useful for referential ambiguity resolution as well.
References
1. Bolshakov I.A. Multifunction thesaurus for Russian word processing. 4th Conference on Applied Natural Language Processing, Stuttgart, Germany, 1994.
3. Bolshakov, I.A., P.J. Cassidy, A.F. Gelbukh. Parallel English and Russian hierarchical thesauri with semantic links, based on an enriched Roget’s thesaurus (in Russian, abstract in English). In Proceedings of International Workshop Dialogue’95: Computational Linguistics and its Applications, Khazan, 1995.
4. Gelbukh, A.F., I.A. Bolshakov, and S.N. Galicia-Haro. Automatic learning of a syntactical government patterns dictionary from Web-retrieved texts. Proc. of CONALD-98, Pittsburgh, PA, 1998.
5. Guzmán, A. Finding the main themes in a Spanish document. Expert Systems with Applications, V. 14, N 1-2, 1998.
6. Hirst, Graeme. Semantic interpretation and the resolution of ambiguity. Cambridge University Press, 1992.
7. Sussna, M. Word Sense disambiguation for free text indexing using a massive semantic network. In Proceedings of CIKM, 1993.
8. Voorhees, E.M. Using WordNet to disambiguate word sense for text retrieval. In Proceedings of ACM SIGIR Conference, 1993, pp. 171-180.
9. Yarowsky, David. Unsupervised Word Sense Disambiguation Rivaling Supervised Methods. In Proceedings of the 33rd Annual Meeting of the Amer. Soc. for Comp. Ling., 1995, pp. 189-196.
10.Yarowsky, David. Word Sense Disambiguation Using Statistical Models of Roget's Categories Training on Large Corpora. In Proceedings of COLING-92, 1992, pp. 454-460.
11.Yuret, Deniz. Discovery of linguistic relations using lexical attraction. Ph.D. thesis, MIT, 1998. See http: // xxx. lanl. gov / abs / cmp-lg / 9805009.