Abstract
Advanced form of the subcategorization information for verbs in languages with relaxed word order constraints is proposed. Such information is considered specific for each verb and is oriented to automatic text processing in mentioned languages. Advanced subcategorization frame (ASF) is expected to reflect relation between syntactic structure and semantic valences of the verb. It indicates which words (mainly prepositions) introduce possible complements of the verb, how these complements can be combined in a phrase, and with what probabilities specific valence combinations are expected. It includes also semantic features such as animity; for Spanish, animity feature facilitates the connection of direct complement to verbs and discrimination between different meanings for a given verb.
Parsing natural language on the base of this information is viewed as making a sequence of disambiguation decisions. The ASFs address mainly the problems of decision on: (1) disambiguation of prepositional phrase attachment, (2) considering long-distance links between words to disambiguate interpretations more accurately, and (3) selecting a variant from a set of weighted alternatives.
Keywords: syntax, subcategorization, lexicon, actants, valences, government patterns.
1. Introduction[1]
Subcategorization frames (SF) are known for a long time [Boguraev, 1987; EAGLES, 1996]. Such a frame reflects a specific combination of complements for a given verb, including their specific order in texts. So they are useful to constrain possible analyses generated by the parser. They also help in automatic text generation and language learning. Because of their usefulness, much effort was applied to compile subcategorization dictionaries for natural language processing (NLP), mainly for English, e. g., ALVEY [Boguraev, 87] and COMLEX [Grishman et al, 1994]).
In the last years, the importance of dictionaries for NLP is growing. In dictionaries, linguistic knowledge is usually divided into different language levels, with direct or indirect specification of verb complements and valences. We use the term valence to describe semantically an actant of the verb, i. e., to describe the semantic role of the actant. Recent research proposed also to build syntactic structures from the dictionary or lexicon which contains specification of verb complements, as in Tree Adjoining Grammars [Joshi & Srinivas, 94], or syntactic patterns [Roche, 97]. Therefore, a machine dictionary with subcategorization information is one of the key components in NLP. However, such a dictionary could specify more lexical requirements imposed by verbs connected to their semantics to process texts of more broad style categories.
The subcategorization information considered in practical dictionaries for NLP is based on several criteria: specific grammar formalism, linguistic phenomena, applications, etc. For example, ACQUILEX [Sanfilippo, 93] bases verb subcategorization on Unification Categorial Grammar. In contrast, ASFs are to be used with different kinds of grammar formalisms so that their description is kept flexible, i.e., as flexible as the information structure permits. We propose to include in ASFs the information required for analyzing languages with rather free word order, such as Spanish, and syntactic information connected with semantics of the verb necessary for syntactic and deeper levels of NLP. In addition, we propose to specify not only all possible complements combinations, but also specific words introducing each complement. This idea is taken from the Meaning Û Text Theory that uses so-called government patterns (GP) [Mel’cuk, 1988; Steele, 1990]. In this theory, each headword has a pattern describing its meaning, its actants, specific words that introduce its complements, and the information on complement combinations, including the order of their occurrences in the text, on obligatory actants and forbidden combinations.
Such form of subcategorization information permits to include some related semantic knowledge: the meaning of the headword and its valences, their animity if necessary, etc. An ASF also considers the description of subject that, for example, COMLEX does not consider in the constituent structure unless the subject has to be morphosyntactically constrained. In addition, with ASFs a more accurate parsing is possible due to definition of a kind of lexical attraction, i.e., relations between individual words (in our case specific verb and prepositions) and obligatory presence of specific valences and their combinations. These features are to be included in an ASF to have a closer link between syntactic and semantic analyses to cope with multiple variants of word order in unrestricted texts. We use the name advanced subcategorization frame (ASF) to distinguish our form from the well-known terms usually related to specific traditions and theories.
Subcategorization frames and government patterns describe subcategorization information from the point of view of different linguistics traditions: constituents and dependencies respectively. In the recent theories in these two traditions, these two forms have more commonalties than differences, though some features are still not included in them, though such constraints simplify description for specific languages.
In this article, we review the currently used representations for subcategorization frames and government patterns. Then some examples are analyzed to explain the selection of proposed subcategorization information and the way to describe it. Then some examples of ASFs are presented and discussed. Finally, we describe the differences obtained as compared to information from other authors.
The statistical results included in the examples were obtained from a large corpus of Spanish[2], namely, LEXESP of Barcelona University, a 2.5 million words corpus annotated with part of speech tags and other morphological features. To obtain these results, we found all sentences in the corpus containing the given verb. Then we extracted the complements for the verb from each sentence and manually classified all complements with the aim of detecting the complements related to valences; circumstantial complements were ignored. Finally, we made a complement classification to identify valences of the given verb in the sentences. We also calculated statistical weights for complements and their combinations; hereafter, as a simplification, percentages are used for these weights. Each ASF includes the weight of specific type of complements that define valence. Each headword verb has weights for valence combinations. It should be mentioned that in the classical description of GPs, statistical information is not considered: GPs strictly define the possible type of complement for each valence, and possible and impossible combinations of them. However, we consider that in languages with relaxed word order constraints it is better to define the weights of combinations rather than to just specify the possible and impossible combinations. The statistical information has the purpose to increase the efficiency of ambiguity resolution of the parser.
The main information for the proposed ASF is connected with semantics and characteristics of languages with relaxed word order constraints such as Spanish. These characteristics differ from English and by consequence lack in usual SFs. Thus, in ASFs subcategorization information for all valences is grouped for a specific headword verb with all necessary statistical information. All this information gives a realistic pattern for accurate parsing and the relevant semantic information.
2. Subcategorization frames
Subcategorization information has been considered in modern grammar formalisms. This information generally involves reference to morphological, syntactical and semantic levels of grammatical description. So, the formalism and the levels considered in it define the description form and the level where the description is positioned. For example, the formalisms without a semantic level representation describe semantic information in syntactic terms; the formalisms that consider thematic role describe actants by role features. Effort to standardize the subcategorization information has been carried out [EAGLES, 96], however, subcategorization information in practical dictionaries has been defined considering theoretical biases, or the application-driven needs, or both. What we describe in this section is the divergence in information with practical dictionaries focused in required information for languages with relaxed order constraints such as Spanish.
Generally, complement structure of a verb is known as its subcategorization frame or class. These SFs are considered as patterns for composition of complements that are ruled by different verbs. A SF usually is a class, and many verbs can have the same combination of complements that constitutes this class. For example, [Briscoe & Carrol, 1997] has automatically extracted 160 classes; COMLEX lists 92 so-called subcategorization features which represent grammatical function structure and constituent structure.
We argue that such classification carried out for English is not totally adequate. We propose that description of actants for each verb should not only describe the meaning, but a more adequate description of some syntactic features. For example, absence of subject in impersonal verbs results in neglecting of morphological features (person and number).
In the traditional SFs, the complement order is fixed and all complements occur after the verb. For example, an SF, NP PP (to), means that after the verb one noun group appears followed by a prepositional phrase beginning with the preposition to, such as for the verb abandon in COMLEX [Grishman, 94]. The permutation PP (to) NP can exist only if it is explicitly expressed with another frame. This description is useful for English because of its rather strict word order; in Spanish this order is freer, for example: Expresó(V) sus ideas(NP) con palabras sencillas(PP), Expresó(V) con palabras sencillas(PP) sus ideas(NP), and Con palabras sencillas(PP) expresó(V) sus ideas(NP) are equally possible, such permutations being quite usual. Even if [EAGLES, 96] considers several European languages, in their recommendations the authors include the linear order of complements only as optional information, though they mention that for some languages the ordering constraints can be completely necessary.
SFs usually consider a set of complements, and the complete set of SFs for languages like English is not very large. [Briscoe & Carrol 1997] found only 160 SFs classes, which is a superset of previously compiled sets. In Spanish, the variety of preposition usage is so big that the entire collection is very large and many subcategorization classes would be required to describe only one verb. The example of SFs of the verb acusar presented below shows the quantity of required data. Namely, traditional SFs representing more than 10% of occurrences in the corpus for the verb acusar are:
|
1. a NP |
5. a NP de V_NF |
|
2. de NP |
6. Æ |
|
3. de V_INF |
7. NP |
|
4. a NP de NP |
|
Here NP is a noun phrase, V_INF is an infinitival verb phrase; specific literal words are italicized.
3. Government patterns
In the Meaning Û Text Theory [Steele, 1990], syntactic dictionary zone describes correspondence between semantic and syntactic valences of the headword, all ways of realization of the syntactic valences, and the indication of obligatoriness of presence for each actant (if necessary). For this, the dictionary presents a government pattern table and the GP restrictions; also examples are usually given. The restrictions considered in GP can be of any type (semantic, syntactic, or morphological). The compatibility between syntactic valences is considered among those restrictions. The examples cover all possibilities: examples for each actant, examples of all possible combination of actants, and finally examples of impossible or undesirable combinations.
The main part of a GP is the list of syntactic valences of the headword. These are listed in a rather arbitrary order, though the order of growing obliqueness is preferred: subject, then direct object, then indirect object, etc. Each headword usually imposes certain order on its actants. For example, an active entity (subject) occupies the first place, then the principal object of the action (direct complement) follows, then another (indirect) complement (if it exists), etc. Also the way of expression for headword meaning influences this order. For example, the expression for Spanish acusar: person X accuses person Y of action Z before a person W.
Other obligatory information at each syntactic valence is the list of all possible ways of expressing this valence in texts. The order of the options for a given valence is arbitrary, though the most frequent options usually go first. The options are expressed with symbols of parts of speech or specific words.
Following the notation of GP table and list of examples, we can describe the Spanish verb acusar as:
|
1 = X |
2 = Y |
3 = Z |
4 = W |
|
||
|
1. NP |
2. a NP |
1. de NP |
4. ante NP |
|
||
|
|
|
2. de INF |
|
|
||
|
obligatory |
obligatory |
|
|
|
||
|
C.1 + C2 |
Juan acusa a María. |
||||
|
C.1 + C2 |
Juan acusa a María |
||||
|
C.1 + C.2 + C.3.1 |
Juan acusa a María de robo. |
||||
|
C.1+ C.2 + C.3.1 + C.4 |
Juan acusa a María de robo ante los demás estudiantes. |
||||
|
Prohibited: |
|
||||
|
C.1 + C.3.1 |
*Juan acusa de robo. |
||||
|
C.3.1 + C.4 |
*Acusa de robo ante los demás estudiantes |
||||
Though in a complete dictionary, syntactic zone specifies all possible examples after the GP table, in our example only some elements of the complete list of possible combinations of actants and some elements of the list of examples for impossible or undesirable combinations were showed. Obligatory indication was the only consideration for impossible combination examples. We omitted the list of examples for each actant because they are implicit in the previous examples.
This example shows how preposition usage allows for identification of prepositional phrases that realize the valences of a given verb. Another example, the Spanish verb expresar ‘express’, according to [DEUM, 96], has the meaning related not only to telling something to someone, but with the manner the subject does this. Spanish speakers use preposition a to introduce an animated actant to whom something is expressed, and several prepositions (en, de, con, mediante) to say by means of what he or she expresses something. Preposition usage also aids to distinguish between verb meanings. Many verbs have different meanings distinguishable by the corresponding prepositions, for example, lanzar: lanzar1 ‘throw’, lanzar2, ‘throw out’,etc.; these homonyms use different prepositions.
4. ASFs for languages with relaxed word order constraints
For such languages, describing complements as usual SFs do (with fix complement order, i.e., without order preferences) could lead to errors or at least problems. For example, the Spanish phrase le acusas ‘you accuse him/her’ uses le as a pronoun for the accused person, in spite of the “unusual” word order. Another example: ellos quieren acusarle ‘they want to accuse you’ where the clitic represents the person accused. The SF number 6 from the example in section 2 considers acusar as an intransitive verb; it represents sentences that seem to end with the verb without specifying the person that is accused, though in fact this information is located before the verb or just within the verb form.
Missing description of subject in subcategorization information could result in erroneous recognition of complements. For example, distinction between inanimate and animate noun groups permits subject inversion detection for some verbs; however, if we can not make such distinction, then we recognize a wrong SF with erroneous valences, as with the verb acusar in the phrase:
... se:PPR acusa:V el atleta:NP ...
(PPR stands for a personal pronoun). The subject inversion here looks like a NP type complement. In section 3, the valences for this verb were described, and the only valence with NP type realization was the subject. The SF of NP type, appearing in section 2, represents complements for another meaning of the verb acusar (related to reveal). This confusion between subject and complement results in a wrong structure or wrong meaning assignment to the verb in such sentences.
There is semantic information detectable in syntactic analysis that must be considered in ASFs: for example, detecting syntactic valences that are linked to semantic valences in deeper analysis levels and distinguishing between complements of the verb and circumstances described by the same SF. The identification of syntactic valences of the verb is accomplished through detecting introductory complement words. For some verbs, only one introductory word is used to realize each valence; for other verbs, there are several such words related to the same syntactic valence. For example, for acusar, de NP is referred to the action of which somebody is accused, but for the verb expresarse (reflexive ‘express’), prepositions en, de, con and mediante (en NP, de NP, con NP, mediante NP) refer to the way somebody expresses something.
For some verbs, only one SF is enough to describe both complements (or valences) of the verb and the circumstances. For example, locative verbs such as colocar ‘collocate’ require complements related to place with prepositions and noun phrases with locative meaning, like en ‘in’ and espacio ‘space’. The frame en NP describes place and time complements for the verb colocar, for example: coloca en este espacio ‘collocates in this space’ and coloca en este momento ‘collocates in this moment’. The former case is related to a valence of the verb, while the latter one is a circumstance and thus is not connected with any valence.
These examples suggest selecting of subcategorization information on the basis of GP, including subject description, specifying introductory words for valences, and describing valence permutations and possible and impossible valence combinations. In addition, it suggests including animity and type of the complement (locative, etc.) features in ASF. Thus, the subcategorization information proposed for ASFs is: subject description, differentiation of valences and circumstances, statistical information for each type of valence realization and valence combinations, and specification of animity and locativeness in valence realization.
Animity has some peculiarities in Spanish. For many European languages, the direct object is connected to the verb without prepositions. However, in Spanish animate entities are connected by preposition a, which is substitutable by pronominal forms [Cano, 87]: le, les, etc. Inanimate entities are connected directly, i.e., without any prepositions. Animity can be considered as a personification: for example, government in Spanish is addressed with preposition a: acusaron al Gobierno. Besides persons, the category of animity is considered covering groups of persons; animals; and some abstract entities: political parties, organizations, etc.
The use of preposition a for animity in fact is related to different uses, but here we only consider its use connected with the direct object. One of such uses is related to distinguish between the meanings of a given verb: for example, querer algo ‘to have the desire to obtain something’ and querer a alguien ‘to love or to estimate somebody’. The principal use that we differentiate is related with animate and inanimate nouns: for example, veo una casa ‘I see a house’ and veo a mi vecina ‘I see my neighbor’. Thus, in Spanish animity is evidently a syntactical feature, though it has clear semantic allusion. This feature is included in ASF mainly with connection to the preposition a.
Spanish has a freer word order (though not totally free) and by consequence, the possible combinations are limited. Impossible combinations could be defined on the base of experience, though in this case they will not reflect the change of language style and the preferences in some domains. Considering obligatory presence, we can list some impossible combinations, but not all. So, statistical corpus-based weights were considered to acquire such information. If one valence occurs in all sentences extracted for a given verb from the corpus, in one or several different realizations, this is considered an evidence of obligatoriness, represented in our notation (see below) by a 100%. This weight will be used by a parser to find even long distance links for valences. For example, the verb acusar requires the presence of direct object; with this specification, the parser should try to find this piece of information somewhere, after or before the verb.

To build an ASF dictionary, first, for possible valence
realizations, the weights for each valence related to a specific introductory
word or preposition are calculated. Then, the weights for each valence in
different positions related to the verb are obtained for possible valence combinations.
This statistical information gives a way to evaluate specific type descriptions
of valences and valence combinations to increase the efficiency of ambiguity
resolution during parsing.
5. Representation of ASFs
The ASFs are considered specific for each verb word. The homonymous verbs are distinguished by numbers, for example: acusar1, acusar2, the order in the numeration being quite arbitrary. Each pair of homonyms should have at least one different element in their ASFs. An ASF is represented in the Figure 1.
The information necessary to fill in these frames is the information of usual SFs plus syntactic valence information of the verb, semantic features (animity and type of complement: locative, etc.), and statistics of common use. We describe the form to acquire this information first from linguistic sources (Fig. 2; “—” stands for numbers that are not important for the present discussion; “~” stands for the verb itself) and then from corpus.
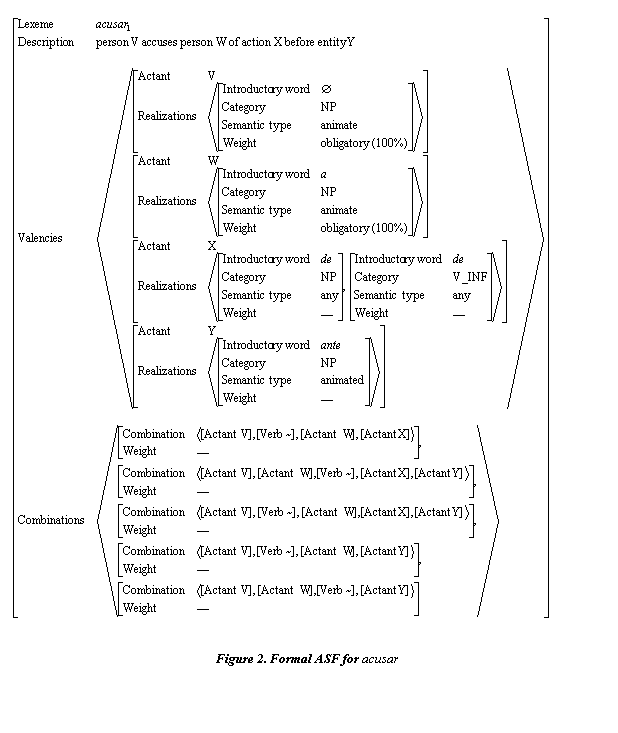
For Spanish, there are no dictionaries with complete
subcategorization information. There is some spread information considered by
several authors that we have been taking into account for the ASFs. For
example, Penadés [1994] considered the verb acusar
among the 145 verbs analyzed, with the following syntactic-semantic scheme:
|
alguien |
acusa |
a alguien |
de algo |
|
Pure internal direct causative agent |
Direct intrinsic causative action |
Specific affected |
Specification |

Other authors, e.g., Alonso [1960] showed some usage examples:
a alguno al, ante el juez, de haber robado,
de los pecados (for reflexive verb), de lo mal
que se ha portado (for reflexive verb). Nañez [1995] presents
preposition usage in alphabetical order for syntactic constructions, according
to him, acusar employs three
prepositions: a, ante, de;some examples are given using the same
form as Alonso did. For the verb acusar
and only considering information from the mentioned authors, we have in Figure
2 the corresponding ASF.
Obligatory occurrence of valences is marked with 100% weight. From such syntactic-semantic scheme, all valences could be considered obligatory. The last valence is described as de NP, but Alonso considers also de V_INF (e. g. de haber robado), so the weights for X valence and the weights for all non-obligatory valences or unknown frequencies are marked with “—”.
Taking into account the information proposed in the previous section, and considering only all the sentences for acusar from the LEXESP corpus, the corresponding ASFs can be built as showed in Fig. 3 and 4.
Fig. 2 presented a formal example, while Fig. 3 and 4 use a more practical form just as shorthand.
The two examples for acusar show the difference in subcategorization information for the two verbs: acusar1and acusar2. For the second one, the complement NP makes the distinction in meaning if we discriminate between common nouns and animate nouns. DEUM [1996] shows three different meanings for this verb, acusar1 specified as Penadés, acusar2 with a NP as direct object, and acusar3 recibo ‘action of receipt’. In LEXESP, acusar1represents 86.5% of sentences for verb acusar, and acusar2 represents 13.5%. Of these two cases, the former is more complex; we discuss this
statistics in the next paragraphs. The probabilities of valence combinations for acusar1appear in Combinations section, the universe being the total number of sentences for the given verb.
There are some combinations representing little number of sentences in each case. The combinations [VW~YX, 0.44%], [VW~XY, 0.44%], [WV~Y, 0.44%] show statistics of combinations related to the valence Y, which represents the entity before which the subject accuses. Despite in LEXESP these cases are rare – one sentence for each case – in legal texts this valence appears more frequently. This is an indication of corpus specificity. This obliged us to work in two different ways: obtaining more texts with diversity of topics on them and making specific domain dictionaries.
The combinations [V~WX, 40.97%], [V~W, 7.05%], [VW~X, 27.75%], [WV~X, 10.13%], [VW~, 5.28%], represent the most common use. The last three ones represent almost half of the total combinations showing the presence of an obligatory valence before the verb in different positions.
The valence W indicates two types of realizations: with the preposition a or with personal pronoun. We consider that this distinction must be described, because even if in common uses any personal noun could be substituted by a personal pronoun, for this verb the valence occurrences are almost equal before and after the verb. In LEXESP, 47.56% of total sentences have this valence before the verb, 11% use a as the introductory word for W, and the remainder use PPR. The total percentage is not 100% because of three sentences with direct speech.

The use of personal pronoun requires more analysis for
automatic acquisition because of the difficult-to-analyze pronouns, especially se. Cano [87] mentioned that se is used almost in 25% of total verb
phrases but its use varies from reflexive to reflexive passive and impersonal
form. Also he mentioned that other authors considered it as a lexical addition
with repercussion on verb meaning. We found that 36.56% of total sentences in
LEXESP use personal pronoun for W valence before the verb and 10.13% use it as
a part of the verb form. We formally considered the latter case as V~W.
Finally, we will discuss the V valence, which only appears 58.13% despite its obligatory condition. There are mainly two reasons for this fact. One reason is the use of reflexive pronouns expressing the same person for subject and direct object. This case was represented by very few sentences, and agreement between reflexive and verbal form helps to disambiguate this lack of subject. The second reason representing 39.2% of total sentences is the absence of subject that some theories consider as so called zero subject. The use of word se as impersonal pronoun and the use of zero subject for linking subject in long-distance lexical position requires deep syntactic analysis, capable of finding specific subjects outside the selected text window or even in previous sentences. The same discussion applies to V valence for acusar2.
6. Acquiring information from corpus
For Spanish, currently there are no dictionaries with complete enough subcategorization information, and huge effort is required to manually compile such a dictionary. What is more, manually compiled dictionaries usually have some disadvantages, e.g., new usage of words is not reflected in them, not to mention compilation errors and specific topic domain dependency. However, recent work on automatic extraction of syntactic information from corpora has demonstrated the possibility to compile a dictionary for traditional SFs that permits easy maintenance, corpus updating, and specific domain considerations. For example, Brent [1991] and Manning [1993] have described acquisition of small number of subcategorization frames for English, and Monedero et al [1995] for Spanish.
To compile a dictionary of ASFs, connecting syntactic, statistical, and semantic knowledge is required. In the semantic part, it is necessary to add animity and locativeness marks to LEXESP markup. Lexical attraction between headword verbs and prepositions is to be detected to describe valences of the verb and to distinguish meanings. The technique to acquire such a lexical attraction differs from those known methods for prepositional phrase (PP) attachment [Ratnaparkhi 1998] because they are addressed to link in any PP, and they not distinguish between PP describing valences and PP describing circumstantial complements. However, those methods for PP attachment could help with noun groups. In Spanish, noun groups usually are attached to the verb or to another noun group with prepositions. For example, while noun phrases in English of the type Noun Noun does not imply prepositional phrase attachment, the same noun phrase in Spanish could have the type Noun preposition Noun.
Taking into account that Spanish has relaxed word order constraints, as we have shown in examples above, combinations of complements become a serious problem. In the program we developed for automatic acquisition of the ASF dictionary, the part related to syntactical and statistical information has grown in a system that now contains six components that are sequentially applied to the marked up (“morphed”) LEXESP corpus. We are using collocation extraction and statistical methods in an iterative manner for acquiring the knowledge on ASFs. The iteration process was conceived as a tool that permits us to compare complements detecting similarity in any position. As we have shown, syntactic valences can appear before the verb; therefore, we need to combine the methods for detecting the same complements at both sides of the verb.
However, valence detection requires human participation. The information extracted from the corpus helps detecting verb valences (as opposed to circumstances) by manual annotation.
Conclusions
We have described an advanced form of subcategorization information for languages with relaxed word order constraints. The advantages of the use of ASFs for parsing (as compared with usual SFs), the required information that ASFs take into account, and the initial steps for acquiring an ASF dictionary from a corpus were discussed.
While usual SFs are defined as a unique representation for all possible complements of verbs, the suggested ASFs are defined for each specific verb to specify its valences and some specific semantic information. The same ASFs can be used for nouns and adjectives that subcategorize for some complements.
ASFs provide the information necessary to differentiate the meaning of verbs, to discriminate the valences of the verb, etc. They also help in more accurate parsing and introduce relations of the syntactic valences to the semantic valences of the verb.
References
Alonso Pedraz, M. 1960. Diccionario Ideoconstructivo. En Ciencia del Lenguaje y Arte del Estilo. Editorial Aguilar. Madrid, España.
Boguraev, B. et al. 1987. The derivation of a grammatically-indexed lexicon from the Longman Dictionary of Contemporary English. In Proceedings of the 25th Annual Meeting of the Association for Computational Linguistics, Stanford, CA.
Brent, M. 1991. Automatic acquisition of subcategorization frames from untagged text. In Proceedings of the 29th Annual Meeting of the Association for Computational Linguistics. Berkeley, CA.
Briscoe, E. & Carroll, J. 1997. Automatic extraction of subcategorization from corpora. In Proceedings of the 5th ACL Conference on Applied Natural Language Processing. Washington, DC.
Cano Aguilar, R. 1987. Estructuras sintácticas transitivas en el español actual. Editorial Gredos. Madrid.
DEUM. 1996. Diccionario del Español Usual en México. El Colegio de México. México.
EAGLES. 1996. Recommendations on Subcategorization. http:// www.ilc.pi.cnr.it/EAGLES96/ synlex/ synlex.html
Joshi, A. and B. Srinivas. 1994. Disambiguation of Super Parts (or Supertags) of Speech Almost Parsing. In Proceedings of the 15th International Conference on Computational Linguistics, pp. 154-160 (COLING-94).
Grishman, R., C. Macleod and A. Meyers. 1994. Comlex syntax: building a computational lexicon. In the proceedings of the 15th Conference on Computational Linguistics, pp. 268-272 (COLING-94).
Manning, C. 1993. Automatic acquisition of a large subcategorisation dictionary from corpora. In Proceedings of the 31st Annual Meeting of the Association for Computational Linguistics. Columbus, Ohio.
Mel’cuk, I. A. 1988. Dependency Syntax: Theory and Practice. State University of New York Press. Albany
Monedero, J. et al. 1995. Obtención automática de marcos de subcategorización verbal a partir de texto etiquetado: el sistema SOAMAS. En Actas del XI Congreso de la Sociedad Española para el Procesamiento del Lenguaje Natural (SEPLN 95: Bilbao), págs. 241-254.
Penadés Martínez, I. 1994. Esquemas Sintáctico-Semánticos de los Verbos Atributivos del Español. Servicio de Publicaciones. Universidad de Alcalá. España.
Nañez Fernández, E. 1995. Diccionario de construcciones sintácticas del español. Preposiciones. Ediciones de la Universidad Autónoma de Madrid. España
Ratnaparkhi, A. 1998. Statistical Models for Unsupervised Prepositional Phrase Attachment. In Proceedings of the 36th Annual Meeting of the Association for Computational Linguistics. Montreal, Quebec, Canada.
Roche, E. 1997 Parsing with Finite-State Transducers. In Finite-State Language Processing dited by E. Roche and Y. Schabes. The MIT Press.
Sanfilippo, A. 1993. LKB encoding of lexical knowledge, in T. Briscoe, A. Copestake & V. de Paiva (eds.), Default inheritance in unification-based approaches to the lexicon. CUP, Cambridge.
Steele, J. 1990. Meaning – Text Theory. Linguistics, Lexicography, and Implications. James Steele, editor. University of Ottawa press.