I.A.
Bolshakov, A. Gelbukh. A Very Large Database of Collocations and
Semantic Links. Proc. NLDB'2000: 5th International Conference
on Applications of Natural Language to Information Systems, Versailles,
France, June 28-30, 2000. Lecture Notes in Computer Science, Springer-Verlag.
A
Very Large Database
of Collocations and Semantic Links
Igor Bolshakov and
Alexander Gelbukh
Center for Computing
Research, National Polytechnic Institute,
Av. Juan Dios Bátiz s/n
esq. Mendizabal, col. Zacatenco, 07738, México DF., Mexico.
{igor,gelbukh}@cic.ipn.mx
Abstract. A computational system manages a very large database of
collocations (word combinations) and semantic links. The collocations are
related (in the meaning of a dependency grammar) word pairs, joint immediately
or through prepositions. Synonyms, antonyms, subclasses, superclasses, etc.
represent semantic relations and form a thesaurus. The structure of the system
is universal, so that its language-dependent parts are easily adjustable to any
specific language (English, Spanish, Russian, etc.). Inference rules for prediction
of highly probable new collocations automatically enrich the database at
runtime. The inference is assisted by the available thesaurus links. The aim of
the system is word processing, foreign language learning, parse filtering, and
lexical disambiguation.
Keywords: dictionary, collocations, thesaurus, syntactic relations, semantic relations, lexical disambiguation.
Introduction
Word processing and computerized learning of
foreign languages include mastering not only the vocabulary of separate words,
but also common relations between them. The most important relations are
·
dependency links between words, with
give word combinations (collocations) occurring in texts with or without
interruption (e.g., fold ® [in one’s] arms, way ® [of]
speaking, deep ¬ admiration, kiss
® passionately, etc.), and
·
semantic links of all kinds (small – little, small – big, apple-tree
– tree, house –room, treatment – doctor, etc.).
To enable writing
a correct text in an unknown language (or sublanguage) with the aid of
computer, author needs a linguistic database with registered links of the mentioned
types and with the most possible completeness.
In [1, 2], a preliminary description of the
CrossLexica system was given. It was
planned as a very large (unrealizable in the printed form) database reflecting
multiplicity of relations between Russian words.
The further research has shown that the
basic ideas of CrossLexica are
equally applicable to other languages, between them English, Spanish or French.
The structure of the system contains only few features dependent on the
specific language. Properties of morphology, the use of obligatory articles or
other determinants of nouns, the word order, and some other morphosyntactic
features can be rather easily adjusted to some universal structure. However,
each version of the system is dedicated to a specific language, and another
language can be optionally embedded only for queries.
In the past, the valuable printed
dictionary of English collocations was created by Benson, Benson, and Ilson
[3], while the WordNet project [4] has produced a very large database of only semantic
links between English words. The analogous works for Italian [5] and other
European languages are also known, whereas in [6] large-scale database of
uninterrupted Japanese collocations was reported. However, we are unaware so
far of systems covering both semantic and syntactic relations and deriving
benefits from this coexistence. It is worth to claim that the combined system
is in no way WordNet-like, since its collocation-oriented part can be much more
bulky and contain information unprecedented in the modern word processors.
The continuing research has proved a
broader applicability of the important property of CrossLexica to use semantic
relations already available in its database for predicting collocations that
were not yet available in it in the explicit form. Let us call this feature
self-enrichment of the database.
Step by step, the set of relations between
words, i.e., textual, semantic, and other, has slightly broadened and
stabilized in CrossLexica. It became clear how to incorporate to it and to
rationally use any complementary language (we have selected English for the
Russian version). This dictionary permits to enter the query words in the
native user’s language and to receive the output data in the language to be
referenced.
The opinion has also settled that such
systems, in their developed form, permit to create more correct and flexible
texts while word processing, to learn foreign languages, to filter results of
parsing, to disambiguate lexical homonyms, and to converse the phonetic writing
to ideographic one for Japanese [6].
In this paper, the description of the
universal structure of the system is given, with broader explanations of its
relations, labeling of words and relations, and the inference capability. The
fully developed version of the system – Russian – is described in some detail,
as well as some peculiarities of underdeveloped English and Spanish versions.
Examples are mainly given in English.
Structure of the system
The structure of the system under investigation
is a set of many-to-many relations upon a general lexicon. The types of
relations are chosen in such a way that they cover the majority of relations
between words and do not depend on the specific language, at least for major
European languages.
Textual relations link words of different
parts of speech, as it is shown in Fig. 1. Four main parts of speech are considered,
i.e., nouns N, verbs V, adjectives Adj, and adverbs Adv,
in their syntactic roles. The syntactic role of an adjective or an adverb can
be played by a prepositional group as well, e.g., man ® (from the South) or speak ® (at random). Each arrow
in Fig. 1 represents an oriented syntactic link corresponding to dependency
approach in syntax. It is possible to retrieve such relations from the side of
both ruling and dependent word, i.e. moving along the oriented dependency chain
or against it.
A syntactic relation between two words can
be realized in a text through a preposition in between, a special grammatical
case of noun (e.g., in Slavonic languages), a specific finite form of verb, a
word order of linked words, or a combination of any these ways. All these features
are reflected in the system entries. Since nouns in different grammatical
numbers can correspond to different sets of collocations, the sets are to be
included into the system dictionary separately.
All types of commonly used collocations are
registered in the system: quite free combinations like white dress or to see a book,
lexically restricted combinations like strong
tea or to give attention (cf. the
notion of lexical function in [9]) and idiomatic (phraseologically fixed) combinations
like kick the bucket or hot dog. The criterion of involving of a
restricted and praseological combination is the very fact that the combination
can be ascribed to one of these classes. The involving of the free combinations
is not so evident, and we have taken them rather arbitrary. Nevertheless, as features
of Russian version show (see later), the semantics itself essentially restricts
the number of possible “free” combinations.
|
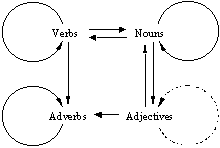
Fig. 1. Various
types of syntactic links.
|
Some idiomatic or commonly used
uninterrupted combinations are additionally included to the lexicon as its
direct entries. As to 3-ary collocations, the system is not destined to contain
them, but a very simple mean, namely dots, is used to represent 2-ary
collocation with obligatory third participant or fourth participant.
Semantic relations link words of different
parts of speech in any-to-any manner. Usually they form a full graph, cf. Fig.
1. We proceed from the idea that many separate meaning can be expressed in any
language by words or word combinations of four main parts of speech. For verbs
this is rather evident (see later an example). For living creatures, things,
and artifacts this is dubious (what id the verb equivalent in meaning to fly
or stone?). For such terms, the verb group in the set of four POS groups
is empty.
User interface
The easiest way to describe an interactive
system is to characterize its user’s interface. For English version, it is
shown in Fig. 3, with necessary explanations given later.
In standard mode, the screen of the system
seems like a page of a book, in which the formatted results of retrieval
operations are output. The operations are prompted by the query consisting of a
separate keyword of a short uninterrupted collocation and are performed within
the system database. (The keyword is shown in the small window at left higher
corner.)
There are two bookmarks with inscriptions
at the upper edge and not less that 14 additional labeled bookmarks at the
right edge.
The first upper-side bookmark, Dictionary, permits a user to enter
queries, directly extracting them from the system dictionary. This is dictionary
of the basic language of the version, i.e., of the language to get references
about or to learn. The entries of the dictionary are presented in alphabetic
order in the left sub-window with a slider. To select necessary dictionary
item, it is necessary to enter its initial disambiguated part.
|

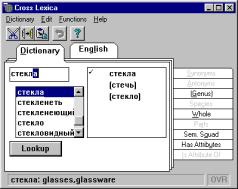 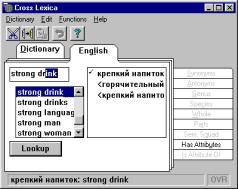
Fig. 2. Two dictionaries
of the Russian version.
|
In the parallel sub-window at the right
side, all possible normalized forms of the string already entered are given.
For example, if English wordform were
is entered, the standard form be is
given there. In some cases, the results of normalization can be multiple. For
example, for the English form lacking
the normalized forms are lack V
and lacking Adj, labeled with
part-of-speech tags.
The second upper-side bookmark permits a
user to select the query in the complementary (usually native language of the
user), e.g. in English, within the Russian version of the system. The system
does not contain data about the second language, it only permits to introduce
queries.
The window of the supplementary language
presents a lexicographically ordered list of words of this language. In
contrast to the basic language dictionary, the forms can be not normalized and
the amount of short collocations in it is much higher, since all these entries
are translations from the basic language.
One important function of the system is to
assist in the translation of each word of the basic language. It translates
them separately, without translating the whole collocation. However, in the
opposite direction, i.e., from supplementary language to the basic one, through
a special filtering, the system automatically forms correct translation of a
whole collocation even in cases, when word-by-word translation might give wrong
result. For example, the translation of the English combination strong tea to Russian also gives the
idiomatic combination krepkiy chay,
though krepkiy has numerous
autonomous translations: firm, robust,
strong, etc.
Main types of relations
The numerous bookmarks at the right side of the
“book page” correspond to the referential functions of the system. These
functions are divided to three groups corresponding to various relations
between words, i.e., semantic, syntactic, and the rest.
We describe these functions through English
examples.
Semantic relations
Synonyms gives
synonymy group for the query keyword.
The group is headed with its dominant, with the most generalized and neutral
meaning. Note that only synonyms are used now in the commercial word
processors.
Antonyms gives the list of antonyms of the keyword, like small for big and vice versa.
Genus is the generic notion (superclass) for the keyword. For example,
all the words radio, newspapers, and television have the common superclass mass media.
Species are specific concepts (subclasses) for the keyword. This relation
is inverse to Genus.
Whole represents a holistic notion with respect to the keyword. For
example, all the words clutch, brakes, and motor give car as a possible value of the whole. Of course, each of these
words can have different other value(s) of the holistic concept and all the
concepts contained in the database are output as a list.
Parts represent parts with respect to the keyword, so that this reflects
the relation inverse to Whole.
Sem. Squad represents semantic derivatives of the keyword. For example, each
word of the structure
while forming a query, gives the other words of
the same structure as its semantic derivatives. All these words correspond to
the same meaning, but express it by various parts of speech and from various
viewpoints (can play different semantic roles).
Syntactic relations
Has Attributes
represents a list of collocations, in which the keyword, being a noun, an
adjective or a verb, is attributed with some other word: an adjective or an
adverb. For example, the noun act can
be attributed with barbaric, courageous,
criminal; the noun period, with incubation, prehistoric, transitional, etc.
Is Attribute Of is reverse to the previous relation and represents a list of
collocations, in which keyword, being adjective or adverb, attributes the other
word of any part of speech. For example, the adjective national can be an attribute for the nouns autonomy, economy, institute, currency; the adjective economic, for the nouns activities, aid, zone, etc.
|
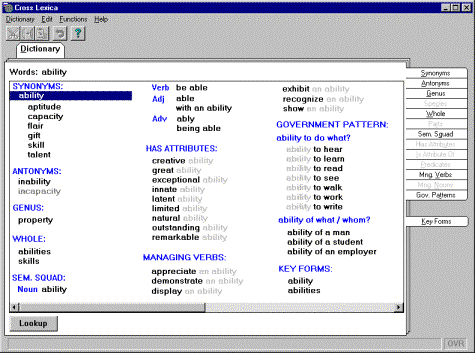
Fig. 3. English
version.
|
In Romance and Slavonic languages, an adjective
usually agrees its morphologic form with its ruling noun, e.g., in Spanish, trabajos
científicos. In all
necessary cases, the agreement is made by the system automatically.
Predicates represents a list of collocations, in which the queried noun is the
grammatical subject and various verbs are common predicates for it. For
example, the noun heart commonly uses
predicates sinks, aches, bleeds; the
noun money uses burns, is close, is flush, etc.
Mng. Verbs represents the list of collocations, in which the queried noun is a
complement and a common verb is its governor. For example, the noun head can have governing verbs bare, beat (into), bend, shake; the noun
enemy can have arrange (with), attack, chase, etc.
Mng. Nouns represent the list of collocations, in which the queried noun is
ruled by various other nouns. For example, the noun clock can be ruled by hand
(of), regulation (of), etc.
Mng. Adjectives represent the list of collocations, in which substantial keyword is
ruled by different adjectives. For example, the noun rage can be ruled by mad
(with).
Gov. Patterns represent schemes, according which the keyword (usually verb or
noun) rules other words, usually nouns, and give also the lists of specific
collocations for each subpattern. In the case of verbs, these are just their
subcategorization frames, but with unfixed word order in the pair. For example,
the verb have has the pattern what / whom? with examples of
dependents capacity, money, family;
the pattern in what? with examples hand, reach; and pattern between
what / whom? with examples friends,
eyes. Conceptually, this function is inverse to Mng. Nouns, Mng. Verbs
and Predicates
relations. The system forms the patterns automatically, through the inversion
of functions mentioned above.
Coordinated
Pairs represent a word complementary to the
keyword, if the both constitute a stable coordinated pair: back and forth, black and white, body and soul, good and evil, now and
then, etc.
Relacions of other types
Paronyms represent the
list of words of the same part of speech and the same root, but with
potentially quite different meaning and collocations. For example, sensation is a representative of the
paronymous group: sensationalism, sense,
sensitivity, sensibility, sensuality, sentiment.
Key Forms represent the list of all morphologic forms (morphologic paradigm)
possible for this keyword. Irregular English verbs have here all their forms
explicitly.In Slavonic languages
like Russian, the paradigms of nouns and adjectives are rather numerous, not
speaking about verbs.
Homonyms
Each homonymous word in the database forms a
separate entry of a system dictionary. Each entry is supplied with numeric
label and a short explanation of meaning. User can choose the necessary entry
or observe them in parallel. It is important, that each homonym have its specific
syntactic and semantic links.
Usage marks
The simple set of usage marks selected for the
items of the database seems sufficient for a common user. In contrast to many
other dictionaries, it contains only two “coordinates”:
·
Idiomacity reflects metaphoric (figurative) use of words and collocations. For
an idiomatic collocation, the meaning is not simply a combination of the
meanings of its components. Three different grades are considered: (1) literal
use (no label); (2) idiomatic and non-idiomatic interpretations are possible (kick the bucket), and (3) only idiomatic
interpretation possible (hot dog).
·
Scope of usage has five grades: (1) neutral: no label and no limitations on the
use; (2) special, bookish or obsolete: use in writing is recommended when meaning
is well known to the user; (3) colloquial: use in writing is not recommended;
(4) vulgar: both writing and oral use is prohibitive; and (5) incorrect
(contradicts to the language norm).
As a rule, the
labels of the scope given at a word are transferred to all its collocations.
Inference ability
The unique property of the system is the online
inference ability to enrich its base of collocations. The idea is that if the
system has no information on some type of relations (e.g., on attributes) of a
word, but does have it for another word somehow similar to the former, the
available information is transferred to the unspecified or underspecified word.
The types of the word similarity are as follows.
Genus. Suppose the complete combinatorial description of the notion refreshing drink. For example, verbs are
known that combine with it: to bottle, to
have, to pour, etc. In contrast, the same information on Coca-Cola is not given in the system database,
except that this notion is a subclass of refreshing
drink. In this case, the system transfers the information connected with
the superclass to any its subclass that does not have its own information of
the same type. Thus, it is determined that the indicated verbs are also
applicable to Coca Cola, see Fig. 4.
Synonym. Suppose that he noun coating
has no collocations in the database, but it belongs to the synonymy group with layer as the group dominant. If layer is completely characterized in the
database, the system transfers the information connected with it to all group
members lacking the complete description. Thus, a user can recognize that there
exist collocations of the type cover with
a coating.
Supplementary
number of noun. If a noun is given in the
system dictionary in both singular and plural forms, but only one of these
forms is completely characterized in the system, then the collocations of one
number are transferred to the supplementary one.
These types of self-enrichment are applied
to all syntactic relations except Gov. Patterns, since this transfer
reflects semantic properties not always not always corresponding to syntactic
ones.
Enrichment of
antonyms. Besides of antonyms recorded in
common dictionaries, synonyms of these antonyms and antonyms of the synonymous
dominant of the word are output as quasi-antonyms. This is the only semantic
relation, which is subject to the enrichment.
Precautions in inferences
In each case, the inherited information is
visually indicated on the screen as not guaranteed. Indeed, some inferences are
nevertheless wrong. For example, berries
as superclass can have nearly any color, smell and taste, but its subclass blueberries are scarcely yellow. Hence, our inference rules have
to avoid at least the most frequent errors.
Classifying
adjectives. The adjectival attributes sometimes
imply incorrect combinations while inferring like *European Argentina (through
the inference chain Argentina Þ country & European country). To avoid them, the
system does not use the adjectives called classifying for the enrichment. They
reflect properties that convert a specific notion to its subclasses, e.g., country Þ European / American / African
country. In contradistinction to them, non-classifying adjectives like agrarian, beautiful, great, industrial, small do not translate the superclass country to any subclass, so that collocation beautiful Argentina is
considered valid by the system while the enrichment.
Idiomatic and
scope labeled collocations are not transferred
to any subclasses either. It is obvious that the collocation hot poodle based on the chain (poodle Ü dog) & (hot ¬ dog) is wrong.
With all these precautions, the
hundred-per-cent correctness of the inferences is impossible, without further
semantic research.
Parse filtering and lexical disambiguation
The system in its standard form has a user’s
interface and interacts with a user in word processing or foreign language
learning. However, the database with such contents can be directly used for
advanced parsing and lexical disambiguation.
If a collocation is directly occurs in a
sentence, it proves the part of dependency tree, in which its components plays
the same syntactic roles. The collocation database functions like a filter of
possible parse trees. It can be realized through augmented weighting of
optional trees with subtrees already found in the database. This idea is the
directly connected with that of [7].
Different homonyms usually have their own
collocations (more rarely, they overlap). For example, bank1 (financial) has attributes commercial, credit, reserve, saving, etc., while bank2 (at shore) has
attributes rugged, sloping, steep, etc.
Thus, if the word bank is attributed,
it can be disambiguated with high probability on the stage of parsing.
Three versions of the system
Russian. The Russian
version of the system is near to its completion, though there are no reasonable
limits for the database and lexicon size. Now it has the lexicon (including
common uninterrupted collocations and prepositional phrases) of ca. 110,000
entries.
The
statistics of unilateral semantic links in this version is as follows:
|
Semantic derivatives
|
804,400
|
|
Synonyms
|
193,900
|
|
Part/whole
|
17,300
|
|
Paronyms
|
13,500
|
|
Antonyms
|
10,000
|
|
Subclass/superclass
|
8,500
|
|
Total
|
1,047,600
|
Note, that for
semantic derivatives, synonyms, and paronyms, the numbers of unilateral links
were counted as Si ni
(ni – 1), where ni is number of members in ith group. That is why the links
connecting semantic derivatives and synonyms are much more numerous than the
derivatives and synonyms themselves.
For syntactic unilateral links, the statistics
is:
|
Verbs – their noun complements
|
342,400
|
|
Verbs – their subjects
|
182,800
|
|
Nouns – short-form adjectives
|
52,600
|
|
Attributive collocations
|
595,000
|
|
Nouns – their noun complements
|
216,600
|
|
Verbs – their infinitive complements
|
21,400
|
|
Nouns – their
infinitive complements
|
10,800
|
|
Copulative collocations
|
12,400
|
|
Coordinated pairs
|
3,600
|
|
Total
|
1437,600
|
Summarizing all
relations gives ca. 2.5 million explicitly recorded links. Foe evaluation of
the text coverage, 12 text fragments of ca. 1 KB length were taken from various
sources (books on computer science, computational linguistics, and radars;
abstract journals on technologies; newspaper articles on politics, economics,
popular science, belles-lettres, and sport; advertising leaflets). The count of
covered collocations was performed by hand, with permanent access to the
database. The results varied from 43% (abstracts) to 65% (ads). The inference
capability gives not more than 5% rise in coverage so far, since the names of
underspecified subclasses turned to be rather rare in texts, and the thesauric
part of the system is not yet brought to perfection.
Some statistics on the fertility of
different words in respect of collocations is pertinent. If to divide the
number of the collocations “verbs – their noun complements” to
the number of the involved nouns, the mean value is 15.7, whereas the division
to the number of the involved verbs gives 17.9. If to divide the number of the
collocations “nouns – their noun complements” to the number
of the dependent nouns, the mean value is 13.6, whereas the division to the
number of the ruling nouns gives 12.8. The mean number of attributes is 15.5.
This series of fertility indicators can be
broadened, all of them being in a rather narrow interval 11 to 18. This proves
that even the inclusion into the database of collocations considered
linguistically quite free gives on average only ca. 20 different words
syntactically connected with each given word, in each category of collocations
(both dependent and ruling syntactic positions are considered). The evident
reason of this constraint is semantics of words, so that the total variety of
collocations in each specific case does not exceed the some limits.
|

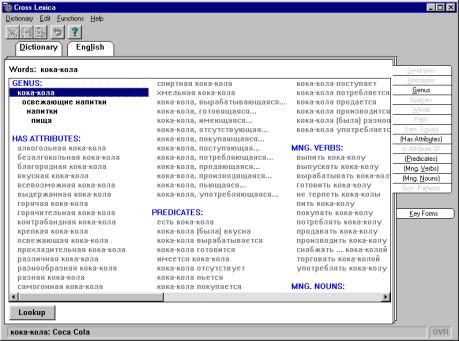
Fig.
4. An example of enrichment: the key Coca
Cola (Russian version).
|
The source database of any language has the
shape of formatted text files. Besides labels of lexical homonymity,
idiomacity, and scope, the Russian version contains numerical labels at
homonymous prepositions (they imply different grammatical cases of dependent
nouns) and sparse accentuation information. The Russian source files with
collocations “verbs – their noun complements” and “nouns –
their noun complements” contain also dots replacing obligatory complements,
which are not participants of the given relation. The dots are not used in the
automatic formation of government patterns, since every complement in Russian
is expressed through its own combination of a preposition and the corresponding
grammatical case.
The methods of automatic acquisition of
collocations are well known in the literature on computing linguistics [7, 8].
We used them in a rather limited and “russified” manner. E.g., one acquisition
program searched for only attributes of each textual noun positioned about it
as (-3, +1) and agreed with it in number, gender, and case. The major part of
the database was gathered manually, by scanning a great variety of texts:
newspapers, magazines, books, manuals, leaflets, ads, etc.
At the stage of automatic compiling of the
runtime database, morphological lemmatizer reduces indirect cases of nouns and
finite verb forms to their dictionary norm. A similar lemmatizer normalizes
forms in the query.
English. An example of how English version functions is given in Fig. 3, for
the query ability. This version is
under development, the size of its source base is now less that one tenth of
Russian database. The special labeling of its source files includes: a delimiter
of prepositions coming after English verbs, like in put on | (a) bandage. The problems of what tenses,
more numerous in English, are to be represented in each “predicate – subject”
collocation and what articles (definite/indefinite/zero) are to given at each
noun are not yet solved.
The best semantic subsystem for the English
version might be WordNet [5].
Spanish. This version is also under development. The morphological lemmatizer
is needed here for personal forms of verbs.
Conclusions
A system for word processing and learning foreign
languages is described. It contains a very large database consisting of
semantic and syntactic relations between words of the system lexicon. The
structure of such a system is in essence language-independent. The developed Russian
version has shown the promising nature of such combined systems.
References
1.
Bolshakov, I. A. Multifunctional
thesaurus for computerized preparation of Russian texts. Automatic Documentation and Mathematical Linguistics. Allerton
Press Inc. Vol. 28, No. 1, 1994, p. 13-28.
2.
Bolshakov, I. A. Multifunction
thesaurus for Russian word processing. Proceedings
of 4th Conference on Applied Natural language Processing, Stuttgart,
13-15 October, 1994, p. 200-202.
3.
Benson, M., et al. The BBI Combinatory Dictionary of English. John Benjamin Publ.,
Amsterdam, Philadelphia, 1989.
4.
Fellbaum, Ch. (ed.) WordNet as
Electronic Lexical Database. MIT Press, 1998.
5.
Calzolari, N., R. Bindi. Acquisition
of Lexical Information from a Large Textual Italian Corpus. Proc. of COLING-90, Helsinki, 1990.
6.
Yasuo Koyama, et al.
Large Scale Collocation Data and Their Application to
Japanese Word Processor Technology. Proc. Intern. Conf. COLING-ACL’98, v. I, p.
694-698.
7.
Satoshi Sekine., et
al. Automatic Learning for Semantic Collocation. Proc.
3rd Conf. ANLP, Trento, Italy, 1992, p. 104-110.
8.
Smadja, F. Retreiving Collocations
from text: Xtract. Computational Linguistics. Vol. 19, No. 1, p. 143-177.
9.
Leo Wanner (ed.) Lexical Functions in Lexicography and Natural Language Processing.
Studies in Language Companion Series ser.31. John Benjamin Publ., Amsterdam,
Philadelphia 1996.