Alexander Gelbukh, Grigori Sidorov, and Liliana Chanona-Hernández. Compilation of a Spanish representative corpus. Proc. CICLing-2002, 3rd International Conference on Intelligent Text Processing and Computational Linguistics, February 17–23, 2002, Mexico City. Lecture Notes in Computer Science N 2276, Springer-Verlag, pp. 285–288.
Compilation of a Spanish Representative Corpus*
Center for Computing
Research, National Polytechnic Institute
{gelbukh, sidorov}@cic.ipn.mx, lchanona@mail.com
Abstract. Due to the Zipf law, even a very large corpus contains very few occurrences (tokens) for the majority of its different words (types). Only a corpus containing enough occurrences of even rare words can provide necessary statistical information for the study of contextual usage of words. We call such corpus representative and suggest to use Internet for its compilation. The corresponding algorithm and its application to Spanish are described. Different concepts of a representative corpus are discussed.
1 Introduction
Our motivation for this work was the statistical research on collocations and subcategorization in Spanish. For this, we needed to calculate, for each word, the relative frequencies of different types of the contexts in which the word is used. This research required a statistically significant number of contexts of each word. However, due to the Zipf law, any corpus contains very few occurrences (tokens) for the majority of the different words (types) used in it. Thus, even a very large corpus provides very poor combinatorial information for the vast majority of words. On the other hand, the vast majority of the size of the traditional corpus is wasted on the repetition of the same few words.
For this type of statistical research, we suggest the use of a new type of corpus, which we call a representative corpus. Such a corpus contains a fixed (and sufficient—say, 50) number of contexts for each word under consideration—ideally, for as many words of the language as possible (we call these words the vocabulary of the corpus). Such a corpus can be obtained as a subset of a larger corpus, selecting a fixed number of occurrences (in context) of the words included in the vocabulary. However, such a full corpus from which this subset is selected should be really huge.
It has been suggested to use Internet as a huge corpus—for example, “virtual corpus” [2]. Though we use Internet to create a real (rather than virtual) corpus, our considerations do not significantly depend on this.
An important decision in compiling such a corpus concerns the criteria of selection of specific occurrences. One of our requirements was proportional presence of all inflective forms of the words. Other possible requirements could include proportional representation of syntactic structures or different types of texts (styles or genres).
In this paper, we will describe the procedure we used for the compilation of a Spanish representative corpus, and then discuss the obtained results.
2 Algorithm
We consider a corpus lexically and morphologically representative if it contains the contexts for its inflectional forms of the lexemes of included in its vocabulary, in a specific proportion. There are several possible ways to calculate the proportions, which gives different strategies for the selection of the occurrences:
- A specific number of contexts (possibly depending on the specific paradigm position) per wordform of any lemma.
- A specific number of contexts per lemma (possibly depending on part of speech).
In the latter case, this number of contexts per lemma can, similarly, be distributed among its wordforms:
- in an equal proportion,
- in a proportion depending on the specific paradigm position, or
- in the proportion of their frequencies in texts for the specific lemma.
We have chosen the last approach.
Using AltaVista search engine, we looked for the contexts of specific lemmas and wordforms in Internet, selected the contexts according to our criteria, and collected them, thus compiling our corpus. The process is illustrated in Fig. 1.
The algorithm is controlled by the agenda, which is a list of words for which the corpus should contain contexts but does not yet contain them. Iteratively, a word is taken from the agenda, the pages containing this word are retrieved from Internet, and “good” contexts are selected for inclusion into the corpus. Also, the retrieved pages are used to find new words; these are added to the agenda, so that at a later iteration their contexts will be looked for. The process stops when the agenda is empty or after a time limit is exceeded. Below we describe this process in more detail.
First, an initial vocabulary (word list) is compiled from various resources (dictionaries and traditional corpora), see left hand part of Fig. 1. The block of lexical analysis selects only some part of the data (say, for dictionaries, it can select only headwords). This forms the initial seed of data to be put onto the agenda.
This seed is filtered to prevent passing of the non-lexical elements (numbers, web addresses, etc.) to agenda. Then the words are morphologically normalized to form lemmas, which are put onto the agenda. Note that later (upper part of Fig. 1) all inflectional forms of each lemma are generated; thus if the seed contained a form did, the contexts will be looked for for the forms do, does, done, doing as well.
Then the lemmas are taken (by the control module) from the agenda one by one, all inflectional forms are generated for each lemma, and for each form, the desired number of contexts is determined by the weight calculation module (upper part of Fig. 1).
Recall that we have chosen the proportion of wordforms according to their frequencies in texts. We estimate these frequencies through the number of documents in Internet containing given wordform. Fortunately, AltaVista search engine provides this number. With this search engine it can be also guaranteed that only the pages in specific language (Spanish in our case) are considered. However, we do not resolve lexical ambiguity within the given language: what is looked for is a letter string rather a wordform of a specific lemma; overcoming this difficulty is a topic of our future work.
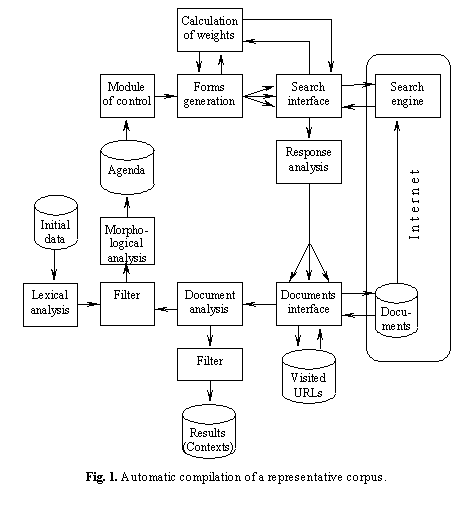 After the desired number of
contexts for a given wordform is determined, pages containing this wordform are
retrieved from Internet (right hand part of Fig. 1; duplicate loading of
the same URL is avoided), the contexts are found, filtered using some criteria
of suitability (see below) and added to the corpus (bottom part of
Fig. 1). For a given wordform, the process is repeated until the desired
number of suitable contexts is added to the corpus.
After the desired number of
contexts for a given wordform is determined, pages containing this wordform are
retrieved from Internet (right hand part of Fig. 1; duplicate loading of
the same URL is avoided), the contexts are found, filtered using some criteria
of suitability (see below) and added to the corpus (bottom part of
Fig. 1). For a given wordform, the process is repeated until the desired
number of suitable contexts is added to the corpus.
A number of heuristics is used to prevent “bad” contexts from inclusion to the corpus. Say, a “good” context should have enough words around the wordform in question, it should consist of plain text rather than control elements or graphics, it should not resemble too closely a context already existing in the corpus, etc.
Each time a page is retrieved, it is searched for strings absent in the vocabulary. These potentially new words are filtered, analyzed, and added to the agenda in the same manner as the initial seed (as described above), thus enriching the corpus’ vocabulary (left hand part of Fig. 1).
3 Experimental Results
Using the headwords from an existing Spanish explanatory dictionary (Anaya), we obtained a seed of about 30,000 lemmas. Since we used only headwords, no morphological normalization was necessary.
For the selection of contexts, we used the value of at least N = 50 contexts per lemma; however, if the paradigm of a lemma had more than N wordforms, we included one context per wordform. However, in the morphological paradigms we ignored the Spanish verbal forms with clitics.
We used the following criteria for a context to be included in the corpus:
- It should contain at least 8 words, and
- 3-word contexts should not repeat. A 3-word context is composed by the wordform itself, one significant word to the left and one to the right (by significant word we mean any word but auxiliary words such as articles, prepositions, etc.).
Until now, we have compiled a corpus with the vocabulary of approximately 45,000 lemmas. It consists of over 100 million words.
4 Conclusions
We have suggested a special type of a corpus—a representative corpus—that does not present the problems traditional corpora present dues to the Zipf law. Such corpus is useful for the statistical research on word combinability, where a statistically significant number of contexts of word usage is required. We have also discussed a method for compilation of such corpus using Internet as a source. The method has been applied to compile a large Spanish representative corpus.
The use of this corpus for learning Spanish subcategorization and collocation dictionaries is the topic of our future work.
References
1. Biber, D., S. Conrad, and D. Reppen (1998). Corpus linguistics. Investigating language structure and use. Cambridge University Press, Cambridge.
2. Kilgariff, A. (2001). Web as corpus. In: Proc. of Corpus Linguistics 2001 conference, University center for computer corpus research on language, technical papers vol. 13, Lancaster University, 2001, pp 342-344.