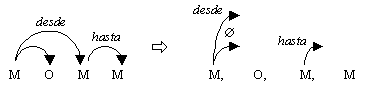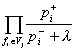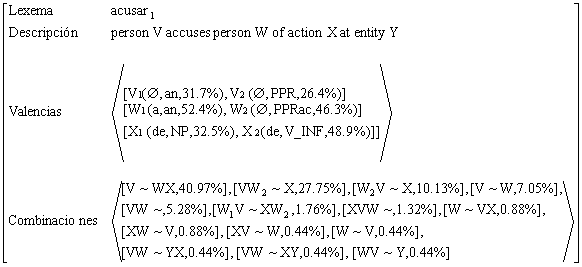|
|
Instituto Politécnico Nacional
|
|



Análisis sintáctico
conducido por un diccionario
de patrones de manejo sintáctico
para lenguaje español
Tesis doctoral
Presenta: M. en C. Sofía Natalia Galicia Haro
Director de tesis:
Dr. Alexander Gelbukh
Codirector: Dr. Igor Bolshakov
México, D.F.
Agosto 2000
Capítulo 2. Compilación del diccionario de verbos españoles con sus estructuras de valencias
Capítulo 3. Análisis sintáctico y desambiguación basada en patrones de manejo avanzados
Capítulo 4. Colección de estadísticas de las combinaciones de subcategorización como método práctico
Lista de publicaciones de la tesista sobre el tema de tesis
Tabla detallada de contenido
Lenguaje natural y lingüística teórica
Peculiaridades sintácticas del español
Ambigüedades en lenguaje natural
Aplicación del modelo de dependencias al español
Algoritmo de adquisición de patrones de manejo
Compilación del diccionario de patrones de manejo
Algoritmo de desambiguación sintáctica
1.1 Gramáticas generativas y la tradición estructuralista europea
Gramática generativa en su primera etapa
Los sucesores y la paliación de los defectos del modelo transformacional
De las reglas a las restricciones
Métodos sin estructura sintáctica
Convergencia de los dos enfoques
1.2 Valencias sintácticas: enfoques diversos
Valencias Sintácticas en la MTT
Métodos lexicográficos tradicionales de compilación de diccionarios
Revisión de los enfoques diversos para la descripción de valencias sintácticas
1.3 Métodos estadísticos: una herramienta para búsqueda de regularidades
Distribución de rangos de frecuencias
Predicción estadística de secuencias aleatorias de palabras
Capítulo 2. Compilación del diccionario de verbos españoles con sus estructuras de valencias
2.1 Diversidad numérica de valencias
2.2 Ejemplos de patrones de manejo para verbos.
2.3 Ejemplos de patrones de manejo para sustantivos y adjetivos
2.4 Dependencia del objeto directo en la animidad, como una peculiaridad del español
2.5 Otra definición de la noción de animidad y su uso
2.6 Repetición limitada de los objetos como otra peculiaridad del español.
2.7 El complemento beneficiario en el español y su duplicación
2.8 Otras complejidades de la representación de valencias
Estado incompleto en el nivel sintáctico
Correspondencia desigual entre valencias sintácticas y semánticas
Mapeo de valencias semánticas a sintácticas
2.9 Ejemplos de complicaciones de patrones de manejo para verbos del español
2.10 Métodos tradicionales para caracterizar formalmente las valencias
2.11 Los patrones de manejo avanzados, como un método alternativo
Capítulo 3. Análisis sintáctico y desambiguación basada en patrones de manejo avanzados
3.1 Antecedentes del sistema propuesto
Idea de combinación de métodos
3.2 Estructura general del analizador
3.3 Creación de la gramática generativa experimental
Desarrollo y ampliación de cobertura de la gramática
Verificación preliminar de la gramática
3.4 Compendio de reglas gramaticales
Signos convencionales de la gramática
3.5 Algoritmo de transformación de árboles de constituyentes a árboles de dependencias
Algoritmo básico de transformación
3.6 Consideración de las reglas ponderadas
3.7 Consideración de la proximidad semántica
3.8 Análisis sintáctico en su versión última
Ejemplos de evaluación cuantitativa
Características de votación del analizador sintáctico
Capítulo 4. Colección de estadísticas de las combinaciones de subcategorización como método práctico
4.2 Información sintáctica para los PMA
Trabajos relacionados: Enlace de frases preposicionales
Trabajos relacionados: Obtención de marcos de subcategorización
4.3 Bases del método de obtención y evaluación de estadísticas de opciones de análisis sintáctico
4.4 Conversión del método en su aplicación a textos modelados
4.5 Conversión del método en su aplicación a textos reales
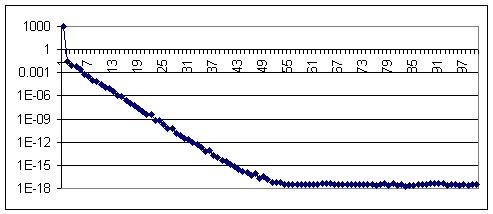
Pesos de las combinaciones y su uso
4.6 Ejemplos de verbos con combinaciones compiladas automáticamente
4.7 Sinopsis de estadísticas obtenidas y comparación de textos modelados y reales
4.9 Algunas conclusiones a favor de la automatización
4.11 Resultados de la aplicación de los pesos de combinaciones en el analizador básico
Rumbos de investigación posteriores
Lista de publicaciones de la tesista sobre el tema de tesis
Capítulos en libros de memorias de Springer
Capítulos en libros de Selected Papers
Figura 1. Estructuras sintácticas
Figura 3. Organización de la GB
Figura 4. Fragmento de cláusula relativa
Figura 5. Estructura para el pronombre she
Figura 6. Estructura de características mediante MAV
Figura 7. Estructura de características mediante MAV
Figura 8. Niveles de Representación en la MTT
Figura 9. Ejemplo de estructura de dependencias en la MTT
Figura 10. Relación indirecta entre sujeto y verbo
Figura 11. Relación indirecta entre sujeto y verbo
Figura 12. Descripción del verbo force
Figura 13. Ejemplo de una representación sintáctica superficial.
Figura 14 Red semántica para la frase Juan bebe bebidas alcohólicas con sus amigos.
Figura 15 Patrones de manejo avanzados
Figura 16.Estructura formal para el verbo acusar
Figura 17. Estructura del analizador con resolución de ambigüedad
Figura 18 Algoritmo de transformación de un árbol de constituyentes a uno de dependencias
Figura 21. Representaciones de árbol y de tabla para el grupo nominal El niño pequeño.
Figura 22. Algoritmo de análisis sintáctico ascendente de tabla.
Figura 23. Diferentes longitudes en los enlaces de la jerarquía.
Figura 24 Red semántica para la frase, Juan ve un gato con un telescopio
Figura 25 Ambigüedad sintáctica.
Figura 26. Modelo de análisis sintáctico y desambiguación
Figura 27 Multievaluación del modelo de multigeneración sintáctica.
Figura 29 Modelo de dos fuentes de generación
Figura 30 Algoritmo para calcular los pesos de combinaciones
Figura 32. Esquema de prueba del algoritmo
Figura 33. Una entrada del diccionario simulado.
Figura 34. El procedimiento iterativo con corpus de textos.
Figura 35. Estructura final formal de los PMA
Figura 36. PMA para el verbo acusar1
Introducción
Lenguaje natural y lingüística teórica
El lenguaje se considera como un mecanismo que nos permite hablar y entender. Los lenguajes naturales[1], es decir, el inglés, el francés, el español, etc. son una herramienta genuina para la comunicación entre los seres humanos, ya sea en forma oral o escrita.
Actualmente, el avance tecnológico en los medios de comunicación impresos y electrónicos nos permite obtener grandes volúmenes de información en forma escrita. La mayoría de esta información se presenta en forma de textos en lenguajes naturales. Toda esa información contenida en los textos es muy importante ya que permite analizar, comparar, entender el entorno en el que vive el ser humano.
Sin embargo, se presentan dificultades por la imposibilidad humana de manejar esa enorme cantidad de textos. Entre las herramientas que ayudan en las tareas diarias, la computadora es, hoy en día, una herramienta indispensable para el procesamiento de grandes volúmenes de datos. Pero todavía no se logra que una máquina al capturar una colección de textos los comprenda suficientemente bien; por ejemplo, para que pueda aconsejar qué hacer en determinado momento basándose en toda la información proporcionada, para que pueda responder a preguntas acerca de los temas contenidos en esa información pero no explícitamente descritos, o para que pueda elaborar un resumen de la información.
Para lograr esta enorme tarea de procesamiento de lenguaje natural por computadora, analizando oración por oración para obtener el sentido de los textos, es necesario conocer las reglas y los principios bajo los cuales funciona el lenguaje, a fin de reproducirlos y adecuarlos a la computadora, incluyendo posteriormente el procesamiento de lenguaje natural en el proceso general del conocimiento y el razonamiento.
El estudio del lenguaje, está relacionado con diversas disciplinas. De entre ellas, la Lingüística General es el estudio teórico que se ocupa de los métodos de investigación y de las cuestiones comunes a las diversas lenguas. Esta disciplina a su vez comprende una multitud de aspectos (temporales, metodológicos, sociales, culturales, de aprendizaje, etc.). Los aspectos metodológicos y de aplicación brindan los principios y las reglas necesarios en el procesamiento de textos.
Los principios y las reglas de la lingüística general, aunados a los métodos de la computación forman la Lingüística Computacional. Esta es la área dentro de la cuál se han desarrollado y discutido muchos formalismos adecuados para la computadora a fin de reproducir el funcionamiento del lenguaje con la finalidad de extraer sentido a partir de textos y viceversa, transformando los conceptos de sentidos específicos a los correspondientes textos correctos.
El proceso que se realiza con las herramientas proporcionadas por la Lingüística Computacional para realizar las tareas necesarias para pasar del texto a la estructura conceptual, y de ésta a los textos, lo denominamos, de aquí en adelante, proceso lingüístico de textos.
Proceso lingüístico de textos
El proceso lingüístico considera análisis y síntesis de textos, es decir, comprensión y generación de oraciones en lenguaje natural. Tanto en la generación como en la comprensión se realizan diferentes transformaciones o cambios de una estructura a otra para llegar al objetivo correspondiente, obtener los conceptos del texto o crear textos, respectivamente.
La generación de texto dentro de este ámbito empieza con la conceptualización del mensaje que se transmitirá y con la definición del nivel de generalización o de detalle en que se realizará. A continuación se sigue con la planeación de las estructuras. Los problemas específicos para construir estas estructuras están relacionados con las elecciones para representar un sentido específico, y con las elecciones de las estructuras particulares que se enlazan a las palabras. Existen otros criterios que intervienen en la construcción de la estructura, que no se consideran en el nivel de oración sino en el nivel del discurso completo, como la coherencia, expuesta mediante enlaces entre oraciones.
La comprensión en el proceso lingüístico, más compleja que la generación, parte de la representación de la información textual, es decir, de la cadena de palabras, y la traduce a diversas estructuras lingüísticas en varias etapas.
Las transformaciones que se requieren en el análisis y la síntesis son tan complejas que se dividen, tanto en la teoría como en la aplicación, en etapas generales. Para que la computadora realice estas etapas se requieren métodos adecuados para la descripción y construcción de las estructuras correspondientes, es decir, se requieren formalismos lingüísticos de representación y computacionales.
En la lingüística general se considera que tres niveles generales componen el procesamiento lingüístico: la morfología, la sintaxis y la semántica. En el procesamiento lingüístico de textos, entre estos niveles, se elaboran descripciones y transformaciones computacionales de estructuras, al menos en dos etapas, en la primera a una estructura sintáctica y en la segunda a la estructura conceptual. Estos niveles no están totalmente delimitados, investigadores diversos difieren un poco en los puntos de vista para esta delimitación pero las diferencias no son cruciales.
Cada uno de los niveles, tanto en la generación como en la comprensión, tiene sus propias reglas y requiere colecciones de datos (diccionarios) apropiadas, aunque ciertas tareas pueden compartir recursos en el análisis y en la síntesis de textos. De hecho, en la construcción de recursos para el procesamiento lingüístico de textos un concepto importante es compartir recursos, dados los grandes esfuerzos que normalmente se requieren para su compilación.
Nuestra investigación se centra en el análisis y en el nivel sintáctico. Por lo que los niveles morfológico y semántico se consideran como los niveles adyacentes, cada uno apoyado en sus propias características. La sintaxis tiene estrechas relaciones con ambos niveles. En el nivel morfológico, las características que están relacionadas con el nivel sintáctico son las categorías gramaticales (las partes del habla y sus subclases), y algunas características morfológicas.
Las partes del habla (part of speech en inglés, POS) son: sustantivo, verbo, artículo, etc. En el análisis se realiza un marcaje de POS cuando se asignan estas categorías gramaticales a cada palabra dada, es decir, cuando se indica la función de cada palabra en el contexto específico de la oración. Este marcaje se hace considerando características morfológicas y sintácticas del lenguaje.
Las características morfológicas relacionadas con la sintaxis son las combinaciones que pueden caracterizar paradigmas. Los paradigmas aquí se refieren a los grupos de palabras relacionadas por su semejanza de significantes (la mínima forma significativa en la palabra) o por alguna relación entre sus significados (idea contenida en el significante). Entre las características morfológicas que caracterizan paradigmas están las formas de conjugación de los verbos (amo, amas, ama, aman, etc.), las variantes que expresan género y número de sustantivos, etc. Por ejemplo, la palabra comen, donde la inflexión en describe tiempo presente, modo indicativo, tercera persona del plural. Estas características se utilizan para relacionar palabras, frases u oraciones entre sí, es decir, para la coordinación; por ejemplo, del verbo con el sujeto (ellos comen), del sustantivo con el adjetivo (casa roja), etc.
Otra característica morfológica con repercusiones sintácticas y semánticas es la relacionada a las formas homónimas. Existen diferentes palabras morfológicas, como banco, bancos, que son variantes de un mismo lexema (la parte constante de una palabra variable que expresa la idea principal contenida) y existen formas homónimas de un lexema, con diferente sentido, que conforman un vocablo común. Estas formas homónimas se numeran para describir sus sentidos. De esta forma, por ejemplo, se tiene banco1 y banco2, mientras el primero se refiere al sentido relacionado a guardar algo (banco de ojos, banco comercial), el segundo se refiere al sentido de asiento para una sola persona.
Formas homónimas como: querer1 tener el deseo de obtener algo, y querer2 amar o estimar a alguien, se distinguen por sus construcciones sintácticas, como se verá más adelante.
Sintaxis
La tarea principal en este nivel es describir cómo las palabras de la oración se relacionan y cuál es la función que cada palabra realiza en esa oración, es decir, construir la estructura de la oración de un lenguaje.
Las normas o reglas para construir las oraciones se definen para los seres humanos en una forma prescriptiva, indicando las formas de las frases correctas y condenando las formas desviadas, es decir, indicando cuáles se prefieren en el lenguaje. En contraste, en el procesamiento lingüístico de textos, las reglas deben ser descriptivas, estableciendo métodos que definan las frases posibles e imposibles del lenguaje específico de que se trate.
Las frases posibles son secuencias gramaticales, es decir, que obedecen leyes gramaticales, sin conocimiento del mundo, y las no gramaticales deben postergarse a niveles que consideren la noción de contexto, en un sentido amplio, y el razonamiento. Establecer métodos que determinen únicamente las secuencias gramaticales en el procesamiento lingüístico de textos ha sido el objetivo de los formalismos gramaticales en la Lingüística Computacional. En ella se han considerado dos enfoques para describir formalmente la gramaticalidad de las oraciones: las dependencias y los constituyentes.
Enfoque de constituyentes
Los constituyentes y la suposición de la estructura de frase, sugerida por Leonard Bloomfield en 1933, es el enfoque donde las oraciones se analizan mediante un proceso de segmentación y clasificación. Se segmenta la oración en sus partes constituyentes, se clasifican estas partes como categorías gramaticales, después se repite el proceso para cada parte dividiéndola en subconstituyentes, y así sucesivamente hasta que las partes sean las partes de la palabra indivisibles dentro de la gramática (morfemas).
La suposición de frase y la noción de constituyente, se aplica de la siguiente forma. La frase los niños pequeños estudian pocas horas se divide en el grupo nominal los niños pequeños más el grupo verbal estudian pocas horas, este último a su vez, se divide en el verbo estudian más el grupo nominal pocas horas y así sucesivamente.
En la perspectiva de constituyentes, la línea más importante de trabajo es la desarrollada por el eminente matemático y lingüística Noam Chomsky, desde los años cincuenta. [Chomsky, 57] dice que lo que nosotros sabemos, cuando conocemos un lenguaje, es un conjunto de palabras y reglas con las cuáles generamos cadenas de esas palabras.
Bajo este enfoque, aunque existe un número finito de palabras en el lenguaje, es posible generar un número infinito de oraciones mediante esas reglas, que también se emplean para la comprensión del lenguaje. Como una subclase, muy importante, de las gramáticas formales, estas reglas definen gramáticas independientes del contexto (Context Free Grammars en inglés, CFG). Sin embargo, existen al menos dos cuestiones principales cuando se trata de la cobertura amplia de un lenguaje natural: el número de reglas y la definición concreta de ellas.
El número requerido de reglas para analizar las oraciones de un lenguaje natural no tiene límite predeterminado porque debe haber tantas reglas como sean requeridas para expresar todas las variantes posibles de las secuencias de palabras que los hablantes nativos pueden realizar. En cuanto a la definición, se generan mucho más secuencias de palabras de las que realmente quieren producirse. Por ejemplo, una regla para definir grupos nominales en el español es: un artículo indefinido, seguido de un sustantivo y a continuación un grupo preposicional. Sin embargo, esta regla define tanto la plática sobre la libre empresa como *la solidaridad sobre la libre empresa[2]siendo ésta última una secuencia no gramatical.
En este enfoque, una información importante para el análisis sintáctico es la definida como subcategorización, referida a los complementos que una palabra rectora puede tener y la categoría gramatical de ellos. Los complementos, en la lingüística general, se definen como palabras, o grupos de elementos lingüísticos que funcionan como una unidad que completa el significado de uno o de varios componentes de la oración, e incluso de la oración entera. Esta información se ha agrupado en patrones que describen la composición de los complementos posibles para diferentes verbos, conocida como marcos de subcategorización.
Principalmente se considera que los verbos son las palabras del lenguaje que requieren estos marcos de subcategorización, los cuales pueden ser de diferentes tipos, simples como grupos nominales, o más complejos como por ejemplo, el verbo dar que subcategoriza un grupo nominal y un grupo preposicional, en ese orden, Da un libro a María. También se considera que la descripción de los complementos puede realizarse en términos sintácticos o en términos semánticos.
En términos sintácticos, se describen por su estructura y partes del habla. Por ejemplo: en diez pesos es un grupo preposicional compuesto de preposición, adjetivo numeral y sustantivo, en una tienda también es un grupo preposicional pero compuesto de una preposición, un artículo y un sustantivo. En este caso, como tanto adjetivo numeral seguido de sustantivo y artículo seguido de sustantivo forman un grupo nominal, el mismo marco: preposición seguida de grupo nominal, describe ambos complementos.
La descripción en términos semánticos, por no estar considerada en una forma ligada a la descripción sintáctica, en este enfoque, se ha complementado con los papeles temáticos. Estos papeles temáticos tienen su antecedente en los casos, que son relaciones abstractas semánticas entre los verbos y sus argumentos, establecida en la Gramática de Casos [Fillmore, 77]. Intentan explicar las diferencias en las distintas estructuras para un verbo, por ejemplo: Juan rompió la ventana con el martillo, El martillo rompió la ventana, La ventana se rompió. Con los papeles temáticos se establece que Juan, el martillo y la ventana, hacen el papel de agente, y el martillo en la primera frase es una herramienta.
Las combinaciones de los distintos complementos en la oración presentan otra complejidad. Por ejemplo, en la frase Compró el niño un libro en diez pesos en la tienda XX a un lado del metro Juárez a un vendedor alto de mal humor, existen seis grupos preposicionales (en la tienda, del metro Juárez, etc.) introducidos con solo tres preposiciones, a, en, de, y aparecen dos grupos nominales (el niño, un libro). Las posibles combinaciones no son aleatorias pero estos complementos o grupos lingüísticos pueden ir enlazados en diferentes combinaciones, unidos al verbo o a algunos sustantivos de los diferentes grupos de la oración, por ejemplo: Compró el niño, Compró un libro, Compró en diez pesos, Compró en la tienda XX, Compró a un vendedor alto, la tienda XX a un lado del metro Juárez.
Mientras para un hablante nativo es obvio cómo se relacionan los complementos, para una computadora son posibles todas las variantes: Compró a un lado, Compró del metro Juárez, Compró de mal humor, el niño en la tienda XX, etc.
Enfoque de dependencias
El primer intento real para construir una teoría que describiera las gramáticas de dependencias fue el trabajo de Lucien Tesnière en 1959. Las dependencias se establecen entre pares de palabras, donde una es principal o rectora y la otra está subordinada a (o dependiente de) la primera. Si cada palabra de la oración tiene una palabra propia rectora, la oración entera se ve como una estructura jerárquica de diferentes niveles, como un árbol de dependencias. La única palabra que no está subordinada a otra es la raíz del árbol.
Es importante notar que la motivación de muchas dependencias sintácticas es el sentido de las palabras. Por ejemplo en la frase Los niños pequeños estudian pocas horas, las palabras pequeños y pocas son modificadores de atributo de las palabras niños y horas respectivamente, y niños es el sujeto de estudiar. Un rasgo muy importante de las dependencias es que no son iguales: una sirve para modificar el significado de la otra, así la secuencia los niños pequeños denota ciertos niños, y estudian pocas horas denota una clase de estudio.
En el enfoque de dependencias, la línea de trabajo más importante es la desarrollada por el investigador Igor Mel’cuk desde los años sesenta, la Meaning Û Text Theory (MTT). Para [Mel’cuk, 79], en la sintaxis se describen los medios lingüísticos por los cuales se expresan todos los participantes que están implicados en el sentido mismo de los lexemas.
Bajo esta perspectiva, la descripción de conocimiento lingüístico es primordial. La descripción de los medios lingüísticos con los que se expresan los “objetos” del lexema se insertan junto con él en un diccionario, de esta forma se conoce de antemano cómo se relaciona el lexema con los distintos grupos de palabras en la oración. Por ejemplo, para el lexema plática aparecerá que utiliza la preposición sobre para introducir el tema, que solidaridad utiliza la preposición con, y que el verbo dar emplea un sustantivo para expresar el objeto donado y para introducir el receptor emplea la preposición a. Estas descripciones se denominan patrones de manejo.[3]
Una cuestión principal cuando se trata de la cobertura amplia de un lenguaje natural, empleando los patrones de manejo, se refiere al establecimiento de todo este conocimiento lingüístico que no se basa en lógica y que por lo tanto conlleva el enorme trabajo manual de la descripción de la colección completa de todos los posibles objetos de las palabras específicas (verbos, sustantivos o adjetivos). Por ejemplo, establecer la manera en que el lexema comprar expresa los participantes, en la acción de hacer que alguna cosa pase de una persona o entidad, a ser propiedad de otra persona o entidad, a cambio de una cantidad de dinero.
Con la sola descripción sintáctica de los complementos no hay una manera de establecer reglas para la computadora que definan las preposiciones específicas de cada verbo, por ejemplo la preposición en para el verbo comprar y no un grupo preposicional introducido por la preposición sobre. Y aún cuando se especificara particularmente para el verbo comprar que un complemento se introduce con la preposición en, se tiene que diferenciar entre grupos preposicionales como en diez pesos que expresa la cantidad de dinero y otros grupos preposicionales que expresan otros sentidos como en una tienda. Esta diferencia que implica un descriptor semántico está contemplada en la MTT.
En la MTT se relacionan los participantes semánticos con los complementos del verbo, es decir, la valencia semántica con la valencia sintáctica. Por ejemplo, la realización sintáctica en diez pesos se refiere a la cantidad de dinero por la cuál se compró algo si está relacionado con comprar o se trata de la cantidad en la cuál disminuye un precio si se trata de reducir, etc. En la MTT, la idea es establecer las valencias, es decir, los participantes referidos a la acción del verbo en cuestión, establecer quién realiza la acción, a quién está dirigida, qué se hace, etc. Por ejemplo, en la acción de beber, los participantes son quién bebe y qué bebe; en la acción comprar los participantes son: quién compra, qué compra, en cuanto lo compra, a quién se lo compra.
En este enfoque, también se considera necesario establecer la diferencia de los complementos seleccionados semánticamente, de los que expresan las circunstancias en las que se da la acción, que se denominan circunstanciales. Los complementos circunstanciales están relacionados al contexto local de la oración pero no expresan participantes en la acción del verbo, añaden información no relacionada directamente al sentido del lexema. Por ejemplo, en la frase, compró contra su voluntad un traje nuevo, el grupo preposicional contra su voluntad expresa un modificador a la acción comprar, pero no es un participante de la acción del verbo.
Peculiaridades sintácticas del español
Existen características dependientes del lenguaje que simplifican o vuelven más compleja la relación entre los grupos de palabras. Reconocer las combinaciones posibles de los verbos y sus complementos es menos complejo cuando en el lenguaje existen posiciones fijas de ocurrencia de ellos. Sin embargo esto varía, la estructura de la oración en diferentes lenguajes tiene diversos órdenes básicos y diferentes grados de libertad en el orden de palabras. Por ejemplo, el inglés y el español tienen un orden básico sujeto-verbo-complemento (SVC).
Esto no quiere decir que siempre se cumpla ese orden. Algunos lenguajes, como el inglés, tienen un orden más estricto, otros, como el español, tienen un grado de libertad mayor. Por ejemplo, la oración en español Juan vino a mi casa (SVC) se acepta sintácticamente en las siguientes variantes: A mi casa vino Juan (CVS), Vino Juan a mi casa (VSC), A mi casa Juan vino (CSV), Juan a mi casa vino (SCV), Vino a mi casa Juan (VCS), por lo que los participantes de las acciones pueden ocurrir en distintas posiciones respecto al verbo.
En español, al igual que en algunos otros lenguajes, el uso de las preposiciones es muy amplio. Este empleo, origina una gran cantidad de combinaciones de grupos preposicionales, pero también sirve para diferenciar, en muchos casos, la introducción de los participantes de una acción. Por ejemplo, en la frase Compró el niño un libro en diez pesos, los hablantes nativos reconocen que se utiliza la preposición en para introducir la expresión del precio del artículo comprado.
En español, el uso de preposiciones permite introducir sustantivos animados en el papel sintáctico de objeto directo, distinguir entre significados de verbos, distinguir participantes. Realmente, la preposición a entre otros usos, sirve para diferenciar el significado del complemento directo de algunos verbos, por ejemplo, querer algo (tener el deseo de obtener algo) y querer a alguien (amar o estimar a alguien). Si este conocimiento se omite en el nivel sintáctico entonces el análisis en el nivel semántico se vuelve más complejo. Esta información también es útil en la generación de lenguaje natural porque dado el sentido que se quiere transmitir existe la posibilidad de seleccionar la estructura precisa para él.
Otra peculiaridad del español es la repetición restringida de valencias. Por ejemplo en la frase: Arturo le dio la manzana a Victor, dónde le se emplea para establecer a quién le dieron la manzana y el grupo preposicional a Victor también representa al mismo participante. Otro ejemplo es: El disfraz de Arturo lo diseñó Victor, donde tanto lo como el disfraz de Arturo corresponden al objeto directo de diseñar. Esta repetición se da en forma de pronombres y sustantivos. Las implicaciones léxicas y sintácticas en cuanto a que algunos verbos presentan estas estructuras, a que se deben relacionar las dos expresiones de valencias sintácticas con la misma valencia semántica, y a posibles diferencias semánticas, competen al análisis sintáctico.
Ambigüedades en lenguaje natural
La ambigüedad, en el proceso lingüístico, se presenta cuando pueden admitirse distintas interpretaciones a partir de la representación o cuando existe confusión al tener diversas estructuras y no tener los elementos necesarios para eliminar las incorrectas. Para desambiguar, es decir, para seleccionar los significados o las estructuras, más adecuados, de un conjunto conocido de posibilidades, se requieren diversas estrategias de solución en cada caso.
Relacionada a la sintaxis, existe ambigüedad en el marcaje de partes del habla, esta ambigüedad se refiere a que una palabra puede tener varias categorías sintácticas, por ejemplo ante puede ser una preposición o un sustantivo, etc. Conocer la marca correcta para cada palabra de una oración ayudaría en la desambiguación sintáctica, sin embargo la desambiguación de este marcaje requiere a su vez cierta clase de análisis sintáctico.
En el análisis sintáctico es necesario tratar con diversas formas de ambigüedad. La ambigüedad principal ocurre cuando la información sintáctica no es suficiente para hacer una decisión de asignación de estructura. La ambigüedad existe aún para los hablantes nativos, es decir, hay diferentes lecturas para una misma frase. Por ejemplo, en la oración Javier habló con el profesor del CIC, puede pensarse en el profesor del CIC como un complemento de hablar o también puede leerse que Javier habló con el profesor sobre un tema, habló con él del CIC.
También existe ambigüedad en los complementos circunstanciales. Por ejemplo, en la frase Me gusta beber licores con mis amigos, el grupo con mis amigos es un complemento de beber y no de licores. Mientras un hablante nativo no considerará la posibilidad del complemento licores con mis amigos, para la computadora ambas posibilidades son reales.
Como mencionamos, la información léxica puede ayudar a resolver muchas ambigüedades, en otros casos la proximidad semántica puede ayudar en la desambiguación. Por ejemplo: Me gusta beber licores con menta y Me gusta beber licores con mis amigos; en ambas frases la clase semántica del sustantivo final ayuda a resolver la ambigüedad, es decir con que parte de la frase están enlazadas las frases preposicionales, con menta y con mis amigos. Ni menta ni amigos son palabras ambiguas pero amigos está más cercana semánticamente a beber que a licores y menta está más cercana a licor que a beber.
La ambigüedad es el problema más importante en el procesamiento de textos en lenguaje natural, por lo que la resolución de ambigüedades es la tarea más importante a llevar a cabo y el punto central de esta investigación. Debido a que existe ambigüedad aún para los humanos, no es una tarea de la resolución de ambigüedades lograr una única asignación de estructuras en el análisis sintáctico de textos, sino eliminar la gran cantidad de variantes que normalmente se producen. Con los resultados de esta tesis, logramos promover las variantes con mayor posibilidad de ser las correctas hacia el grupo inicial en la clasificación de las variantes sintácticas generadas para cada oración.
Esta tesis propone un modelo para resolver el problema del análisis sintáctico relacionado a la gran cantidad de variantes generadas cuando se analizan textos sin restricciones. El modelo considera un algoritmo de desambiguación basado en tres diferentes fuentes de conocimiento del lenguaje, de las cuales la fuente principal dirige el análisis mediante conocimiento lingüístico. El algoritmo de desambiguación sintáctica restringe la gran cantidad de variantes que normalmente se generan, así que la base del análisis sintáctico pasa de la tarea infinita de definir una gramática de cobertura total para el lenguaje, la forma tradicional, a la tarea principal de buscar los objetos de cada palabra.
La primera fuente de conocimiento es lingüística y se describe en una colección de patrones de manejo sintáctico que reúnen información de cómo las palabras del español especifican léxicamente sus objetos, la segunda fuente se describe en una gramática extendida independiente del contexto para el español, y la tercera fuente se basa en proximidad semántica entre palabras.
Para lograr este objetivo, primero analizamos las características del español, principalmente las que difieren de los lenguajes cuyo orden de palabras es más estricto, para describirlas bajo un enfoque generalizado de descripción de valencias, con mayor énfasis en el formalismo de la MTT. Basándonos en este análisis proponemos una forma nueva de descripción de los Patrones de manejo, la denominamos Patrones de manejo avanzados, con información cualitativa para el análisis sintáctico. Debido al conocimiento lingüístico que se requiere en dichos patrones, proponemos un método semiautomático de adquisición de esa información, a partir de un corpus de textos. Por último, proponemos un algoritmo para reducir el número de variantes posibles de análisis, es decir, de desambiguación sintáctica.
Por lo que la investigación descrita en esta tesis incluye nuevas contribuciones en los aspectos explicados en las siguientes secciones.
Aplicación del modelo de dependencias al español
Los formalismos para análisis sintáctico basados en constituyentes han sido más apropiados para el inglés, principalmente por su orden de palabras más estricto. Debido al apoyo y a la cantidad de investigadores que trabajan en esta línea, se ha aplicado a muchos otros lenguajes, aún cuando no comparten la mayoría de las características del inglés.
Los modelos de dependencias que representan una continuación de las tradiciones europeas antiguas en lenguajes con un orden de palabras más libre, se han orientado más hacia un trabajo descriptivo, por lo que se han empleado muy restringidamente y en pocos lenguajes. De entre los modelos de dependencias la Meaning Û Text Theory, que representa la tradición gramatical rusa, es la teoría más desarrollada, por su sistema formal que en alcance y contenido es comparable con la escuela generativa, de constituyentes.
Al español solamente se han aplicado formalismos basados en constituyentes. Una lista de los trabajos realizados basados en dependencias se encuentra en [DG Website, 99].
La aplicación de la MTT al español permite describir algunas características del español de una manera más natural y adecuada, como el orden más libre de palabras (comparado con el inglés), el uso de palabras específicas para introducir complementos seleccionados semánticamente y también para establecer la relación entre valencias sintácticas y semánticas.
Algoritmo de adquisición de patrones de manejo
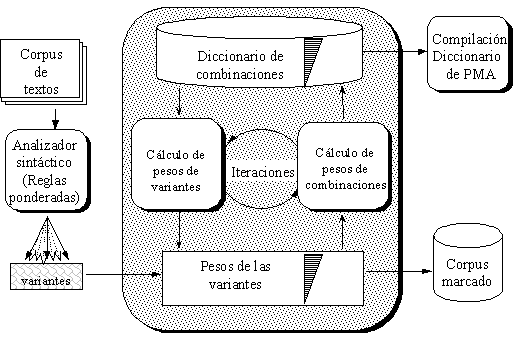
La aplicación de la MTT se ha realizado en forma limitada porque la compilación de los recursos necesarios, diccionarios principalmente, requiere un esfuerzo enorme, por la necesidad de descripción del lenguaje en términos lingüísticos en todos los niveles. Para eliminar esta desventaja elaboramos un algoritmo que emplea métodos estadísticos y lingüísticos.
Los métodos puramente lingüísticos tienen el defecto de requerir por mucho tiempo la participación de recursos humanos calificados. Los métodos estadísticos, se han empleado con buenos resultados, en diferentes líneas de investigación. Una área importante de aplicación para los métodos estadísticos es la adquisición de información léxica. Los sistemas basados solamente en métodos estadísticos no han logrado el éxito total para resolver la mayoría de los problemas de procesamiento de lenguaje natural para los cuales fueron aplicados, sin embargo han sido muy útiles, y combinados con conocimiento lingüístico han demostrado cierta superioridad.
En esta investigación se combinan métodos lingüísticos que permiten extraer estructuras sintácticas, y métodos estadísticos para la selección de variantes de estructuras con la finalidad de obtener los complementos de palabras específicas (verbos, adjetivos y sustantivos).
Compilación del diccionario de patrones de manejo
La compilación de un diccionario de patrones de manejo avanzados para el español permite abarcar una cobertura amplia del lenguaje porque reúne conocimiento puramente lingüístico que no es posible reproducir mediante razonamiento ni mediante algoritmos. Se han compilado muy pocos diccionarios de este tipo, principalmente porque se han compilado manualmente y porque los diccionarios desarrollados incluyen el modelo completo de la MTT.
La compilación de los patrones mediante el algoritmo lingüístico estadístico desarrollado permite incluir información estadística adicional para eliminar cierta ambigüedad en el análisis sintáctico y para favorecer determinadas realizaciones que aparecen con mayor frecuencia en corpus de textos, lo cual no ha sido considerado en compilaciones de este tipo de diccionarios.
Este diccionario es un recurso para el procesamiento del español que servirá tanto para el análisis como para la síntesis en el nivel sintáctico.
Algoritmo de desambiguación sintáctica
La principal contribución de este trabajo es en el avance del análisis sintáctico de textos en español sin restricción. En el español, la ambigüedad sintáctica se ve magnificada por la cantidad de frases preposicionales que se emplean, lo que ocasiona una mayor cantidad de variantes generadas en el análisis sintáctico.
Diversos formalismos se han desarrollado para tener una cobertura total en el análisis sintáctico de lenguajes naturales, sin embargo la principal dificultad que se ha presentado es reconocer las estructuras reales de entre una enorme cantidad de variantes generadas en dichos análisis.
Se han propuesto métodos que utilizan un solo modelado del lenguaje, por ejemplo con gramáticas independientes del contexto (CFG), con gramáticas de estructura de frase generalizada, con gramáticas de adjunción de árboles (TAG), etc. También se ha propuesto la combinación de formalismos con estadísticas, por ejemplo CFG con probabilidades, TAG con probabilidades, entre otros.
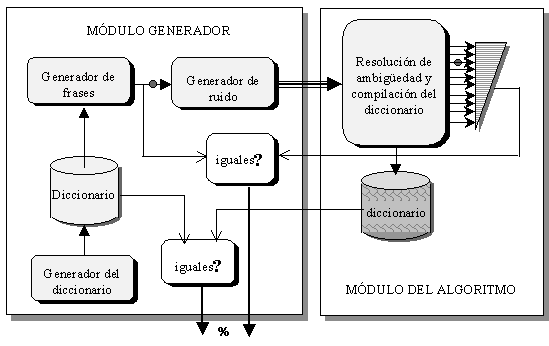
El algoritmo de desambiguación sintáctica que aquí presentamos se basa en la transformación a una forma compatible de las variantes sintácticas generadas mediante diversos modelos del lenguaje, en la evaluación cuantitativa de ellas y finalmente en una votación que clasifique las variantes para determinar las de mayor posibilidad de ser las correctas. Este algoritmo emplea como base principal el diccionario y los pesos de los patrones de manejo.
En el capítulo uno presentamos los antecedentes para el desarrollo de la investigación sobre análisis sintáctico, los formalismos gramaticales que se han desarrollado dentro de la lingüística computacional y las herramientas requeridas. A partir del capítulo dos presentamos nuestras aportaciones. En el capítulo dos desarrollamos la aplicación del modelo de dependencias al español, en el capítulo tres presentamos nuestro algoritmo de análisis y desambiguación sintáctica, y en el capítulo cuatro el algoritmo de adquisición del diccionario de patrones de manejo sintáctico.
En el capítulo uno, en la primera sección, revisamos las gramáticas generativas y las estructurales en su evolución histórica. Por una parte, la evolución de las teorías derivadas de los constituyentes para superar los problemas generados por las transformaciones y cómo se paliaron estos problemas mediante las restricciones. Por otra parte las teorías derivadas de las dependencias y los formalismos desarrollados. Por último, la tendencia lexicista como la convergencia de ambas descripciones.
Después presentamos la descripción de las estructuras sintácticas de los objetos de las palabras según cada uno de los formalismos representativos para comparar la información que cada uno propone y el nivel en el que sitúa su descripción. En la tercera sección del capítulo uno presentamos los métodos estadísticos para detectar regularidades en las secuencias de palabras en las oraciones, y en la última sección la noción de redes semánticas como descripción de conocimiento semántico.
En el capítulo dos presentamos la descripción detallada de las valencias, las complejidades que se presentan, las peculiaridades semánticas y sintácticas del español que se describen en los patrones de manejo y ejemplos de estos patrones para verbos, sustantivos y adjetivos. Describimos la información que proponemos para los nuevos patrones de manejo y la descripción de su notación formal. Presentamos también las diferencias entre la descripción de valencias en los enfoques considerados.
Presentamos primero la descripción del modelo general de análisis y desambiguación sintáctica, y posteriormente el algoritmo de compilación del diccionario ya que en ambos empleamos el analizador básico construido, basado en gramáticas generativas. Este analizador básico, representa una de las fuentes de conocimiento para el modelo general y en este contexto se describe detalladamente. En cambio, en la implantación del algoritmo de compilación del diccionario lo empleamos como herramienta de construcción de variantes.
En el capítulo tres describimos el modelo general de análisis sintáctico y desambiguación, propuesto, es decir, el modelo completo y cada uno de sus subsistemas. Describimos la gramática generativa experimental que desarrollamos, su creación, características y verificación. Presentamos el algoritmo seleccionado para realizar el análisis sintáctico con la gramática generativa. Describimos el algoritmo desarrollado para la transformación a una forma compatible de dependencias. Describimos también el empleo de la red semántica para la desambiguación sintáctica. Presentamos finalmente la formulación de la evaluación cuantitativa de las variantes sintácticas, el algoritmo de votación y su expansión a un multimodelo.
El algoritmo de adquisición de los patrones de manejo se describe en el capítulo cuatro. Presentamos primero la deducción del modelo, enseguida presentamos la evolución de su desarrollo, en su aplicación a textos modelados y posteriormente a textos reales, las estadísticas en ambos y su comparación. A continuación presentamos ejemplos de los patrones compilados, las estadísticas obtenidas y la comparación entre métodos de compilación en forma tradicional y en forma automatizada. Por último presentamos las pruebas realizadas sobre un conjunto de prueba para dar una medida de la efectividad del empleo del diccionario compilado.
Finalmente presentamos las conclusiones, que incluyen el motivo y las aportaciones de esta tesis, adicionalmente presentamos rumbos posteriores a esta investigación.
Capítulo 1.
Restrospectiva histórica de los formalismos gramaticales y algunas herramientas
en lingüística computacional
En muchas disciplinas, la retrospectiva histórica y el estado actual permiten una visión más clara de cada disciplina, desde el punto de vista de los principales enfoques y ejemplos representativos de cada una. Entonces presentamos de esta manera los formalismos gramaticales en la Lingüística Computacional. Consideramos los dos enfoques que por mucho tiempo se han considerado opuestos y que en años recientes tienen más coincidencias: la gramática generativa cuyo principal representante es la teoría desarrollada por Chomsky en sus diversas variantes, y la tradición estructuralista europea que proviene de Tesniére, con el ejemplo más representativo, la teoría Sentido Û Texto de I. A. Mel’cuk. El sistema formal de esta última, en alcance y contenido es comparable con la escuela generativa.
Se tiende a creer que las palabras componen una oración como una progresión en una sola dimensión. Sin embargo, la propiedad del lenguaje natural que es de importancia central en la sintaxis es que tiene dos dimensiones. La primera es explícita, el orden lineal de palabras, y la segunda es implícita, la estructura jerárquica de palabras. El orden lineal es lo mismo que la secuencia de las palabras en la oración. El papel de la estructura jerárquica se refiere a menudo como una dependencia, podemos ejemplificarla con las siguientes frases:
una persona sola en la construcción
una persona interesada en la construcción
En la primera frase, el grupo de palabras en la construcción se une al grupo una persona indicando el lugar donde se encuentra la persona, mientras que en la segunda frase el mismo grupo se une a interesada indicando cuál es su interés. Lo que hace la diferencia en las interpretaciones, no es evidentemente un orden lineal puesto que el grupo en la construcción se encuentra en el final de ambas frases, y tampoco se trata de la distancia lineal en las dos frases.
Tanto el orden lineal como la estructura jerárquica, aunque principalmente esta última, son el tema principal en los formalismos para el análisis sintáctico. Los enfoques que presentamos consideran esa jerarquía como relaciones entre combinaciones de las palabras o entre palabras mismas.
Siguiendo el paradigma de Chomsky se han desarrollado muchos formalismos para la descripción y el análisis, sintácticos. El concepto básico de la gramática generativa es simplemente un sistema de reglas que define de una manera formal y precisa un conjunto de secuencias (cadenas a partir de un vocabulario de palabras) que representan las oraciones bien formadas de un lenguaje específico. Las gramáticas bien conocidas en otras ramas de la ciencia de la computación, las expresiones regulares y las gramáticas independientes del contexto, son gramáticas generativas también.
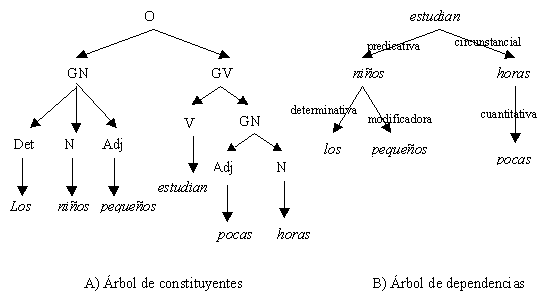
Chomsky y sus seguidores desarrollaron y formalizaron una teoría gramatical basada en la noción de generación [Chomsky, 65]. El trabajo que se realiza en la gramática generativa descansa en la suposición acerca de la estructura de la oración de que está organizada jerárquicamente en frases (y por consiguiente en estructura de frase). Un ejemplo de la segmentación y clasificación que se realiza en este enfoque se presenta en la Figura 1 A en el árbol de constituyentes para la frase los niños pequeños estudian pocas horas, donde O significa oración.
Un árbol de estructura de frase revela la estructura de una expresión en términos de agrupamientos (bloques) de palabras, que consisten de bloques más pequeños, los cuales consisten de bloques aún más pequeños, etc. En un árbol de estructura de frase, la mayoría de los nodos representan agrupamientos sintácticos o frases y no corresponden a las formas de las palabras reales de la oración bajo análisis. Símbolos como GN (grupo nominal), GV (grupo verbal), N (sustantivo), GP (grupo preposicional), etc. aparecen en los árboles de estructura de frase como etiquetas en los nodos, y se supone que estas únicas etiquetas completamente determinan las funciones sintácticas de los nodos correspondientes.
En el enfoque de estructura de frase, la categorización (la membresía de clase sintáctica) de las unidades sintácticas se especifica como una parte integral de la representación sintáctica, pero no se declaran explícitamente las relaciones entre unidades.
|
Figura 1. Estructuras sintácticas
|
Las Gramáticas de Dependencias se basan en la idea de que la sintaxis es casi totalmente una materia de capacidades de combinación, y en el cumplimiento de los requerimientos de las palabras solas. En el trabajo más influyente en este enfoque, el de [Tesnière, 59], el modelo para describir estos fenómenos es semejante a la formación de moléculas, a partir de átomos, en la química. Como átomos, las palabras tienen valencias; están aptas para combinar con un cierto número y clase de otras palabras formando piezas más grandes de material lingüístico.
Las valencias de una palabra se rellenan con otras palabras, las cuales realizan dos tipos de funcionamiento: principales (denominadas actuantes) y auxiliares (denominados circunstanciales o modificadores). Las descripciones de valencias de palabras son el dispositivo principal para describir estructuras sintácticas en las gramáticas de dependencias.
La gramática de dependencias supone que hay comúnmente una asimetría entre las palabras de una frase: una palabra es la rectora, algunas otras son sus dependientes. Cada palabra tiene su rectora, excepto la raíz, pero no todas tienen dependientes. Por ejemplo, una palabra es niños, la modificadora es pequeños. La palabra rectora raíz da origen a la construcción total y la determina. Las dependientes se ajustan a las demandas sobre la construcción, impuestas por la rectora. La diferencia entre rectoras y dependientes se refleja por la jerarquía de nodos en el árbol de dependencias.
Las gramáticas de dependencia, como las gramáticas de estructura de frase, emplean árboles a fin de describir la estructura de una frase u oración completa. Mientras la gramática de estructura de frase asocia los nodos en el árbol con constituyentes mayores o menores y usa los arcos para representar la relación entre una parte y la totalidad, todos los nodos en un árbol de dependencias representan palabras elementales y los arcos denotan las relaciones directas sintagmáticas entre esos elementos (Figura 1 B).
Las teorías de estructura de frase y las gramáticas de dependencias se han desarrollado en paralelo. Ambas han marcado la forma en la que se concibe la sintaxis en el procesamiento lingüístico de textos. A lo largo de casi cuarenta años muchos formalismos se han desarrollado dentro de ambos enfoques de una manera muy diferente. Mientras los constituyentes han sido aplicados a la mayoría de todos los lenguajes naturales con la intención de una cobertura amplia, las dependencias han sido aplicadas en pocos lenguajes con una cobertura restringida. Primero presentamos un panorama del desarrollo de la estructura de frase y a continuación el desarrollo de las gramáticas con dependencias.
Gramática generativa en su primera etapa
Versión inicial
incluyendo la componente transformacional
[Chomsky, 57], en su libro Estructuras Sintácticas, presentó una versión inicial de la Gramática Generativa Transformacional (GGT), gramática en la cuál, la sintaxis se conoce como sintaxis generativa. Una de las características del análisis presentado ahí y en subsecuentes trabajos transformacionales es la inclusión de postulados explícitos formales en las reglas de producción, cuyo único propósito era generar todas las oraciones gramaticales del lenguaje bajo estudio, es decir, del inglés.
La gramática transformacional inicial influyó, a las teorías posteriores, en el énfasis en la formulación precisa de las hipótesis, característica primordial en el enfoque de constituyentes. Ejemplos de las reglas de producción que se emplean para esa formulación precisa son las siguientes, con las cuales se construyó el árbol de la Figura 1 A:
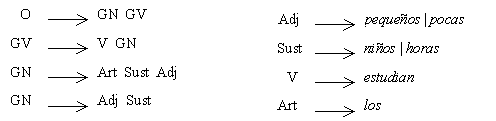
La flecha significa que se reescribe como, es decir, el elemento de la izquierda se puede sustituir con el agrupamiento completo de la derecha. Por ejemplo, una oración (O) se puede reescribir como un grupo nominal (GN) seguido de un grupo verbal (GV). Un GN puede reescribirse como un artículo (Art) seguido de un sustantivo (Sust) y un adjetivo (Adj). Un grupo verbal puede sustituirse con un verbo (V) seguido de un grupo nominal. Todos los elementos que no han sido sustituidos por palabras específicas se denominan no-terminales (GV, O, etc.), los elementos del lenguaje específico se denominan terminales (estudian, los, etc.).
Este tipo de reglas corresponde a una gramática independiente del contexto. Esto se debe a que los elementos izquierdos de las reglas solamente contienen un elemento no terminal y por lo tanto no se establece el contexto en el que deben aparecer. Este tipo de gramáticas es el segundo tipo de gramáticas menos restrictivas en la clasificación de Chomsky, que pueden analizarse con un autómata de pila, y para las cuales existen algoritmos de análisis eficientes [Aho et al, 86].
Chomsky [57] dio varios argumentos para mostrar que se requería algo más que las solas reglas de estructura de frase para dar una descripción razonable del inglés, y por extensión de cualquier lenguaje natural, por lo que se requerían las transformaciones, es decir, reglas de tipos más poderosos. Las relaciones como sujeto y objeto[4], fueron un ejemplo de la necesidad del desarrollo de la gramática transformacional ya que su representación no era posible con las reglas independientes del contexto.
La GGT define oraciones gramaticales de una manera indirecta. Las estructuras aquí denominadas subyacentes o base se generan mediante un sistema de reglas de estructura de frase y después se aplican sucesivamente las reglas transformacionales para mapear esas estructuras de frase a otras estructuras de frase. Esta sucesión se llama derivación transformacional e involucra una secuencia de estructuras de frase, de una estructura base a una estructura de frase denominada estructura superficial, cuya cadena de palabras corresponde a una oración del lenguaje. Desde este punto de vista, las oraciones del lenguaje son aquellas que pueden derivarse de esta manera.
Una propuesta clave en las gramáticas transformacionales, en todas sus versiones, es que una gramática empíricamente adecuada requiere que las oraciones estén asociadas no con una sola estructura de árbol sino con una secuencia de árboles, cada una relacionada a la siguiente por una transformación. Las transformaciones se aplican de acuerdo a reglas particulares en forma ordenada; en algunos casos las transformaciones son obligatorias. Ejemplos de transformaciones son el cambio de forma afirmativa a forma interrogativa, y de forma activa a pasiva.
La hipótesis de la gramática transformacional, es que por ejemplo[5], la frase (b) se deriva mediante reglas y el diccionario, de (a), con una transformación, alterando la estructura de tal forma, que la frase-wh es inicial dentro de S.
(a) Max wonders [the child wants to get which candy every day]
(b) Max wonders [which candy the child wants to get every day]
Este tipo de transformación opera sobre cualquier frase que pueda analizarse con una estructura como
![]()
donde S indica una oración, X y Y secuencias de palabras. NP es el grupo nominal y wh abarca las palabras inglesas interrogativas: which, where, who, etc.
En el ejemplo anterior the child wants to get correspondería a Xy every day correspondería a Y, aunque podría ser incluso nulo. La frase anterior entonces puede transformarse mediante la transformación que incluye el “movimiento” del constituyente X a la posición entre NP y Y, denotada como:
![]()
que corresponde a (b). Otra transformación es la que se realiza a partir de la estructura subyacente The man is running (El hombre está corriendo) para obtener la correspondiente forma interrogativa Is the man running? (¿Está corriendo el hombre?).
Entre las transformaciones más importantes se encuentra la relacionada a las oraciones pasivas. Por ejemplo: that dog was chased by the police, que se deriva de las mismas estructuras subyacentes de sus contrapartes activas, the police chased that dog, por medio de una transformación a pasiva que permuta el orden de los dos grupos nominales e inserta las palabras was y by en los lugares adecuados.
Otro punto muy importante de la GGT fue el tratamiento del sistema de verbos auxiliares del inglés, el análisis más importante en esta teoría. Chomsky propuso que el tiempo, en las formas verbales, estuviera en la estructura sintáctica subyacente, como un formante separado del verbo del cual formaba parte. Propuso dos transformaciones, una de movimiento para considerar la inversión del auxiliar en las preguntas y una de inserción que situaba not en el lugar apropiado para las oraciones de negación.
Ambas transformaciones, en algunos casos, tienen el efecto de un tiempo separado, es decir, lo dejan en una posición que no está adyacente al verbo. Para estos casos, Chomsky propuso una transformación para insertar el auxiliar do como un portador de tiempo. De esta misma forma se trataron, otros usos diversos del verbo auxiliar do, como la elipsis. Esta consideración unificada de aparentes usos diferentes de do, junto con la claridad formal de la presentación hicieron que muchos investigadores de la época se adhirieran a la GGT.
La GGT dominó el campo de la teoría sintáctica de los años sesenta a los ochenta. La GGT cambió significativamente desde su aparición pero a pesar de su evolución, la noción de derivación transformacional ha estado presente de una u otra manera en prácticamente cada una de sus formulaciones.
Teoría estándar
La GGT inicial se transformó en base a los cambios propuestos en los trabajos de [Katz & Postal, 64] y de [Chomsky, 65]. La teoría resultante fue La Teoría Estándar (Standard Theory, en inglés, ST). Entre esos cambios, la ST introdujo el uso de reglas recursivas de estructura de frase para eliminar las transformaciones que combinaban múltiples árboles en uno solo, y la inclusión de características sintácticas, para considerar la subcategorización (tema de la sección 1.1.2). Otra aportación fue la adición de una componente semántica interpretativa a la teoría de la gramática transformacional.
Las reglas de estructura de frase permiten la recursividad, por ejemplo, en verbos como decir que además de tener un complemento tipo grupo nominal (dijo una mentira) aceptan complementos tipo oración (dijo que María decía mentiras). Un ejemplo de reglas recursivas es:
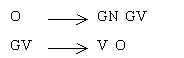
En la primera regla, O puede reescribirse con GN GV, y a su vez GV tiene sustitución de O, y así sucesivamente (Juan dijo que María dijo que Pedro dijo …).
En la ST se presenta el concepto de estructura profunda, es decir, el árbol inicial en cada derivación de la oración. Esta estructura profunda representaba de una forma transparente toda la información necesaria para la interpretación semántica. Se sostenía que había un mapeo simple entre los roles semánticos desempeñados por los argumentos del verbo y las relaciones gramaticales [6] de la estructura profunda (sujeto, objeto, etc.). En el árbol final de la derivación, las palabras y las frases estaban ordenadas en la forma en que la oración sería realmente pronunciada, es decir, en su estructura superficial.
En esta teoría, las transformaciones se propusieron para ser el enlace primario entre voz y sentido, en el lenguaje. Los experimentos iniciales que mostraban una correlación entre la complejidad de una oración y el número de transformaciones propuestas en su derivación dieron credibilidad a esta idea pero investigaciones posteriores mostraron que no se podía sustentar. Ninguna teoría generativa actual mantiene esta idea central de las transformaciones.
Uno de los problemas fundamentales planteados por la ST es que el sentido está determinado a partir de la estructura profunda, antes de la aplicación de las transformaciones, pero entonces la influencia de las transformaciones sobre los sentidos no es nada clara.
La mayoría de las teorías gramaticales contemporáneas han mantenido las innovaciones más importantes de la ST, es decir, las características sintácticas, la estructura de frase recursiva y alguna clase de componente semántica.
Teoría estándar ampliada
Chomsky y algunos otros abandonaron poco después de la ST la idea de que debían ser sinónimas las oraciones con estructuras profundas idénticas. En particular, demostraron que las transformaciones que reordenan grupos nominales cuantificados pueden cambiar el alcance de los cuantificadores. Un ejemplo muy conocido es el de Many people read few books (mucha gente lee pocos libros) que tiene interpretaciones diferentes de Few books are read by many people (pocos libros son leídos por mucha gente). En consecuencia, propusieron que estructuras diferentes, de las estructuras profundas, debían desempeñar un papel en la interpretación semántica.
El marco teórico que Chomsky denominó Teoría Estándar Ampliada (The Extended Standard Theory en inglés, EST), propuso una teoría muy reducida en transformaciones, y en su lugar se mejoraron otras componentes de la teoría para mantener la capacidad descriptiva. Además de nuevos tipos de reglas semánticas, introdujeron la esquematización de reglas de estructura de frase, y una concepción mejorada del diccionario, incluyendo reglas léxicas. Estas modificaciones se han trasladado a muchos trabajos contemporáneos.
La EST presentó dos modificaciones esenciales:
· El modelo de interpretación semántica debe considerar el conjunto de árboles engendrados por las transformaciones a partir de la estructura profunda
· El modelo incluye una etapa de inserción léxica antes de la aplicación de las transformaciones. Así que sólo existen dos tipos de reglas: las gramaticales y las de inserción léxica.
La gramática produce un conjunto de “pre-terminales” que no contienen más que marcadores gramaticales, marcadores de transformaciones (que indican cuales son las transformaciones que se efectuarán) y las categorías léxicas. Las reglas de inserción léxica reemplazan estas últimas por las palabras, produciendo así el conjunto de terminales.
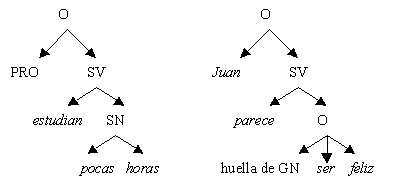
La EST consideró la introducción de categorías vacías, que son elementos que ocupan posiciones en un árbol pero que no tienen una realización fonética. Incluyen un tipo de pronombre nulo usado en construcciones de control[7], y huellas[8] de elementos que han sido trasladados. Por ejemplo, ver Figura 2[9], un sujeto nulo (anáfora pronominal pro) en la frase española Estudian pocas horas; una huella de grupo nominal en la frase Juan parece ser feliz (la huella GN corresponde a Juan, el sujeto semántico de ser.
|
Figura 2. Categorías vacías
|
Uno de los intereses centrales de la EST y de trabajo posterior ha sido restringir la potencia de la teoría, es decir, restringir la clase de gramáticas que la teoría hace disponibles. La explicación principal para buscar esas restricciones ha sido considerar la posibilidad de la adquisición del lenguaje, la cuál fue considerada por Chomsky como la cuestión central de sus estudios lingüísticos.
Los sucesores y la paliación de los defectos del modelo transformacional
Las teorías siguientes a partir de la EST buscaron sobre todo resolver las cuestiones metodológicas debidas a la sobrecapacidad del modelo. [Salomaa, 71] y [Peters & Ritchie, 73] demostraron que el modelo transformacional era equivalente a una gramática sin restricciones, es decir, del tipo 0 en la jerarquía de Chomsky.
De hecho, después de varios años de trabajo, estaba claro que las reglas transformacionales eran muy poderosas y se permitían para toda clase de operaciones que realmente nunca habían sido necesarias en las gramáticas de lenguajes naturales. Por lo que el objetivo de restringir las transformaciones se volvió un tema de investigación muy importante.
[Bresnan, 78] presenta la Gramática Transformacional Realista que por primera vez proveía un tratamiento convincente de numerosos fenómenos, como la posibilidad de tener forma pasiva en términos léxicos y no en términos transformacionales. Este paso de Bresnan fue seguido por otros investigadores para tratar de eliminar totalmente las transformaciones en la teoría sintáctica.
Otra circunstancia en favor de la eliminación de las transformaciones fue la introducción de la Gramática de Montague [Montague, 70, 74], ya que al proveer nuevas técnicas para la caracterización de los sentidos, directamente en términos de la estructura superficial, eliminaba la motivación semántica para las transformaciones sintácticas.
En muchas versiones de la gramática transformacional, las oraciones pasivas y activas se derivaban de una estructura común subyacente, llevando a la sugerencia controversial, de que las derivaciones transformacionales preservaban muchos aspectos del sentido. Con el empleo de métodos de análisis semántico como el de Montague, se podían asignar formalmente distintas estructuras superficiales a distintas pero equivalentes interpretaciones semánticas; de esta manera, se consideraba la semántica sin necesidad de las transformaciones.
Es así como a fines de la década de los setenta y principios de los ochenta surgen los formalismos generativos donde las transformaciones, si existen, tienen un papel menor. Los más notables entre éstos son: Government and Binding (GB), Generalized Phrase Structure Grammar (GPSG), Lexical-Functional Grammar (LFG) y Head-Driven Phrase Structure Grammar (HPSG), que indican los caminos que han llevado al estado actual en el enfoque de constituyentes.
Teoría de la rección y Ligamento (GB)
La teoría de la Rección y Ligamento conocida como GB apareció por primera vez en el libro Lectures on Government and Binding de 81 [Chomsky, 82]. El objetivo primordial de la GB, como mucho del trabajo de Chomsky, fue el desarrollo de una teoría de la gramática universal. La GB afirma que muchos de los principios que integran esta teoría están parametrizados, en el sentido de que los valores varían dentro de un rango limitado. La GB afirma que todos los lenguajes son esencialmente semejantes y que el conocimiento experimental con un lenguaje particular o con otro es una clase de fina sintonización dentro de un rango determinado, es decir, con unos pocos parámetros restringidos de posible variación.
La noción que adquiere un papel preponderante en el enfoque de constituyentes es una noción muy importante de la Gramatical Universal, la restricción. La suposición en que se basa esta teoría y que es compartida por muchas otras, es que cualquier cosa es posible y que los datos faltantes en la oración reflejan la operación de alguna restricción. El área más activa de investigación sintáctica desde los inicios de los ochenta ha sido precisamente resolver los detalles de este programa ambicioso.
En la GB se sigue el desarrollo del estilo modular de la EST, dividiendo la teoría de la gramática en un conjunto de subteorías, cada una con su propio conjunto universal de principios. Aunque la GB aún utiliza las derivaciones transformacionales para analizar oraciones, reduce la componente transformacional a una sola regla (Move a), que puede mover cualquier elemento a cualquier lugar. La idea es que los principios generales filtren la mayoría de las derivaciones, previniendo la sobregeneración masiva que pudiera ocurrir.
|
Figura 3. Organización de la GB
|
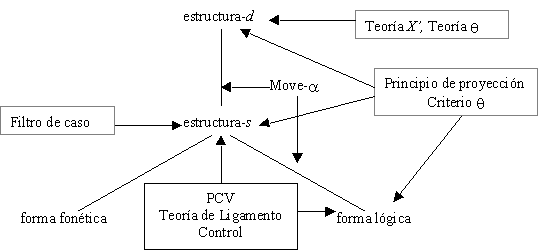
La organización general de la GB con todos sus componentes[10], presentado por [Sells, 85] se muestra en la Figura 3.
Las estructuras -d y -s desempeñan una función similar pero no idéntica que las nociones de estructura profunda y superficial respectivamente de la ST. Estos niveles están relacionados por la operación Move-a, donde a se entiende que sea una variable sobre las categorías sintácticas. Puede considerarse que muchas de las transformaciones de las teorías precedentes se factorizaron en operaciones elementales donde ya no existen reglas específicas (transformaciones) como la de la pasiva sino que existe el movimiento de cualquier elemento a cualquier posición, y los principios y las restricciones regulan las operaciones de Move-a.
La Teoría q (o de relaciones temáticas) provee información semántica. Los q-roles se refieren a los participantes en la acción del verbo. En la GB se presupone que hay un número relativamente pequeño y por supuesto finito de estos roles, y emplea el criterio q para establecer exactamente el número de argumentos que léxicamente especifica cada h-núcleo[11].
El filtro de caso se emplea para la buena formación de la estructura y la distribución de grupos nominales. Se basa en la tradicional noción de caso gramatical (nominativo, acusativo, dativo), que varía con el tipo de lenguaje.
La Teoría del Ligamento (Binding Theory, en inglés, BT) ha sido el mayor tópico de investigación dentro de la GB, caracteriza las relaciones interpretativas entre grupos nominales. La BT reúne principios como el Principio de la Categoría Vacía (PCV). El análisis en la GB propone diferentes tipos que podrían clasificarse de acuerdo a las características anafórica y pronominal, en abiertos o vacíos. Los de tipo abierto son explícitos y reflexivos; los vacíos son: desplazamiento wh[12] en formas interrogativas, pronombres tácitos del español (pro), pronombres para infinitivos (PRO), huellas de GN en verbos de control.
El movimiento va dejando huellas (una clase de categoría vacía), las cuales están limitadas por el elemento que se ha movido. La BT relaciona así las restricciones en el movimiento, con posibles relaciones de pronombres con antecedentes. La GB considera que, intuitivamente, las anáforas son aquellas que deben tener un antecedente (como los pronombres reflexivos) y los pronominales (como los pronombres personales) pueden tener un antecedente; todo esto se considera dentro de la misma cláusula. Puesto que el movimiento se usa para tratar con un rango amplio de fenómenos; entre ellos la relación activa - pasiva, la extraposición[13], y la inversión de auxiliares, se produce un sistema abundantemente interconectado al ligar todos éstos a los principios de la BT.
En la GB hay un cambio importante en la descripción estructural. Las estructuras de frase están altamente articuladas, es decir, combinadas y relacionadas según ciertas normas de distribución, orden y dependencias. Distinciones y relaciones, lingüísticamente significantes, están codificadas dentro de las configuraciones del árbol tipo GB. Por ejemplo la categoría abstracta INFL, que contiene información de tiempo y concordancia, aparece en el árbol.
La literatura dentro de este formalismo es vasta, y representa un rango mucho más amplio de análisis que cualquiera de las otras teorías consideradas. Estudios lingüísticos del español se basan en este formalismo para sus descripciones [Lamiroy, 94], [Wilkins, 97].
El descendiente más reciente de la GB es el Programa Minimalista (PM) [Chomsky, 95]. Como su nombre lo implica, PM es más un programa de investigación que una teoría de sintaxis ya realizada. El PM explora la idea de que en lugar de generar oraciones directamente, lo que las gramáticas deberían hacer es seleccionar las mejores expresiones a partir de un conjunto de candidatas. El trabajo de elaborar los detalles del PM está aún en etapas iniciales.
Una diferencia conceptual mayor entre la GB y el PM es que en el PM los elementos léxicos portan sus características junto con ellos en lugar de asignárseles sus características basándose en los nodos en los que ellos rematan. Por ejemplo, los sustantivos llevan las características de caso con ellos y ese caso se revisa cuando los sustantivos están en una posición de especificación de concordancia.
El PM se origina a partir de la GB pero representa una considerable desviación del trabajo inicial en ese formalismo. Su meta es explicar la estructura lingüística en términos de condiciones de ahorro que son intuitivamente naturales en las gramáticas y en sus operaciones. Por ejemplo, los análisis tienen un mejor valor si minimizan la cantidad de estructura y la longitud de las derivaciones propuestas.
Gramática de estructura de frase generalizada (GPSG)
La Gramática de Estructura de Frase Generalizada (Generalized Phrase Structure Grammar, en inglés, GPSG) fue iniciada por Gerald Gazdar en 1981, y desarrollada por él y un grupo de investigadores, integrando ideas de otros formalismos; la teoría se expone detalladamente en [Gazdar et al, 85].
La idea central de la GPSG es que las gramáticas usuales de estructura de frase independientes del contexto pueden mejorarse en formas que no enriquecen su capacidad generativa pero que las hacen adecuadas para la descripción de la sintaxis de lenguajes naturales. Al situar la estructura de frase, otra vez, en un lugar principal consideraban que los argumentos que se habían aducido contra las CFG, como una teoría de sintaxis, eran argumentos relacionados con la eficiencia o la elegancia de la notación y no realmente en cuanto a la cobertura del lenguaje.
La GPSG propone sólo un nivel sintáctico de representación que corresponde a la estructura superficial, y reglas que no son de estructura de frase en el sentido en que no están en una correspondencia directa con partes del árbol. Entre otras ideas importantes originadas en la teoría está la separación de las reglas en reglas de dominancia inmediata (reglas ID, Immediate dominance en inglés) que especifican solamente las frases que pueden aparecer como nodos en un árbol sintáctico, y las reglas de precedencia lineal (reglas LP, Linear precedence en inglés) que especifican restricciones generales que determinan el orden de los nodos en cualquier árbol.
Una consideración importante en las reglas, es que puede describirse información gramatical. Esta información gramatical codificada se toma como restricción en la admisibilidad en los nodos. Por ejemplo:

Las dos últimas reglas son reglas sensitivas al contexto, no generan nada porque la primera establece la reescritura de O por GN GV, pero ellas dos, interpretadas como la posibilidad de admisión, se refieren a que se admite Juan duerme como una oración a la que se le generaron árboles, enseguida se le revisaron los nodos y se verificó la cadena.
Así que aunque la GPSG excluye las transformaciones, la gramática se vuelve gramatical-léxica, pero realmente poco o nada se dice acerca del diccionario. Especialmente la información de subcategorías del verbo se encuentra en las reglas ID léxicas y no como entradas léxicas en el diccionario.
Esta teoría incluye la consideración del h-núcleo en las reglas, y de categorías. Las categorías son un conjunto de pares característica - valor. Las características tienen dos propiedades: tipos de valores y regularidades distribucionales (compartidos con otras características). La GPSG es de hecho una teoría de cómo la información sintáctica fluye dentro de la estructura. Esta información está codificada mediante características sintácticas. Todas la teorías sintácticas emplean características en diferentes grados, pero en la GPSG se emplean principios para el uso de características. Los principios determinan cómo se distribuyen las características en el árbol, o restringen la clase de categorías posibles.
Otra idea importante en la GPSG es el tratamiento de las construcciones de dependencia a largas distancias, incluyendo las construcciones de llenado de faltantes (filling gap en inglés) como: topicalización[14], preguntas con Wh y cláusulas relativas. Este fenómeno estaba considerado como totalmente fuera del alcance de las gramáticas sin transformaciones. En las dependencias a larga distancia, sin límite, existe una relación entre dos posiciones en la estructura sintáctica, relación que puede alargarse. Por ejemplo, en la frase:
Which woman did Max say _ has declared herself President?
(¿Qué mujer dijo Max que se había declarado Presidenta?)
El guión bajo indica la posición de la frase desplazada which woman, que puede alejarse a una posición potencialmente sin límite en el árbol sintáctico. Mientras en la GB se dejaba una huella, en la GPSG el trato de este fenómeno involucra una codificación local de la ausencia del constituyente dado mediante una especificación de características.
Por ejemplo, a partir de la regla:
![]()
que introduce una oración finita como un nodo, se puede obtener, mediante una metaregla, la siguiente regla:
![]()
|
Figura 4. Fragmento de cláusula relativa
|
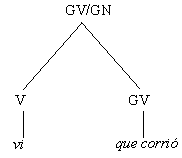
con un GV finito en lugar de la oración, y con la indicación del GN faltante mediante la diagonal. La GPSG incluye la introducción de head en las reglas, que se marca con H en los ejemplos anteriores. La regla última permite el árbol sintáctico de la Figura 4, para un fragmento de la cláusula relativa la niña que vi que corrió, que correspondería al desplazamiento al inicio, de la cadena la niña en la frase vi la niña que corrió.
El resultado más importante del análisis en la GPSG es que pudo manejar construcciones que se pensaba sólo podían describirse con la ayuda de las transformaciones. En este formalismo las transformaciones no figuran en ningún sentido en la teoría; es más, sin transformaciones de las dependencias de llenado de faltantes tuvo éxito en estos fenómenos donde la teoría transformacional había fallado.
Gramática léxica funcional (LFG)
La teoría de la Gramática Léxica Funcional (Lexical Functional Grammar en inglés, LFG) desarrollada por [Bresnan, 82] y [Dalrymple et al, 95] comparte con otros formalismos la idea de que conceptos relacionales, como sujeto y objeto, son de importancia central y no pueden definirse en términos de estructuras de árboles. La LFG considera que hay más en la sintaxis de lo que se puede expresar con árboles de estructura de frase, pero también considera la estructura de frase como una parte esencial de la descripción gramatical.
La teoría se ha centrado en el desarrollo de una teoría universal de cómo las estructuras de constituyentes se asocian con los objetos sintácticos. La LFG toma esos objetos sintácticos como primitivas de la teoría, en términos de las cuales se establecen una gran cantidad de reglas y condiciones.
En la LFG, hay dos niveles paralelos de representación sintáctica: la estructura de constituyentes (estructura-c) y la estructura funcional (estructura-f). La primera tiene la forma de árboles de estructura de frase independientes del contexto. La segunda es un conjunto de pares de atributos y valores donde los atributos pueden ser características como tiempo y género, u objetos sintácticos como sujeto y objeto. En la LFG se considera que la estructura-f despliega los objetos sintácticos. Por ejemplo:
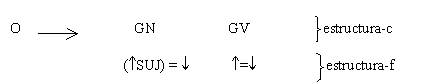
Las flechas ( y ¯) se refieren a la estructura-f correspondiente al nodo de la estructura-c construida por la regla. La flecha hacia arriba se refiere a la estructura-f del nodo madre y la flecha hacia abajo se refiere a la estructura-f del nodo mismo. Estas anotaciones indican que toda la información funcional que lleva el GN (es decir, la estructura-f de GN) va a la parte SUJ (sujeto) de la estructura-f del nodo madre (es decir, la estructura-f de O), y que toda la información funcional que lleva el GV (es decir, la estructura-f de GV) también es información de la estructura-f del nodo madre. De esta manera se establecen las relaciones entre estructuras, la estructura-f para la frase John eats pizza, sería la siguiente:
El valor de PRED (de predicado), indica el contenido semántico del elemento correspondiente. Por ejemplo el contenido semántico del sujeto en esa frase es John. En la entrada del verbo eat (comer) la parte léxica <(SUJ)(OBJ)> indica que el verbo subcategoriza un sujeto y un objeto; mediante las flechas se especifica que la estructura-f del nodo madre tiene un sujeto y un objeto. La inflexión del verbo añade la información del atributo tiempo verbal con el valor PRES (presente).
El nombre de la teoría enfatiza una diferencia importante entre la LFG y la tradición Chomskyana de la cuál se desarrolló: muchos fenómenos se analizan de una forma más natural en términos de objetos sintácticos (como se representan en el diccionario o en la estructura-f) que en el nivel de la estructura de frase. La parte léxica enfatiza la expresión para caracterizar procesos que alteran la relación de los predicados en el diccionario. Por ejemplo, la relación entre construcciones pasivas y activas.
En la LFG cada frase se asocia con estructuras múltiples de distintos tipos, donde cada estructura expresa una clase diferente de información acerca de la frase. Siendo las dos representaciones principales las mencionadas estructura funcional y estructura de constituyentes (similar a la estructura superficial de la ST). Los principios generales y las restricciones de construcción específica definen las posibles parejas de estructuras funcionales y de constituyentes. La LFG reconoce un número más amplio de niveles de representación. Tal vez los más notables entre éstos son las estructuras-s, que representan aspectos lingüísticamente relevantes del sentido, y la estructura-a que sirve para enlazar argumentos sintácticos con aspectos de sus sentidos [Bresnan, 95] y que codifica información léxica acerca del número de argumentos, su tipo sintáctico y su organización jerárquica, necesarios para realizar el mapeo a la estructura sintáctica.
Todos los elementos léxicos se insertan en estructuras-c en forma totalmente flexionada. Debido a que en la LFG no hay transformaciones, mucho del trabajo descriptivo que se hacía con transformaciones se maneja mediante un diccionario enriquecido, una idea importante de la LFG. Por ejemplo, la relación activa-pasiva. se determina solamente por un proceso léxico que relaciona formas pasivas del verbo a formas activas, la cuál en lugar de tratarse como una transformación se maneja en el diccionario como una relación léxica entre dos formas de verbos.
La regla de pasiva es una regla léxica, la cuál esencialmente añade el morfema de pasiva al verbo y cambia sus complementos de tal manera que el argumento asociado con el objeto de la forma activa se convierte en sujeto, y el sujeto se asigna a una función nula o a un Agente Oblicuo.

Por ejemplo, en la frase eaten by pirahnas:

En las LFG iniciales, la relación activa-pasiva fue codificada en términos de reglas léxicas, trabajo subsecuente ha buscado desarrollar una concepción más abstracta de las relaciones léxicas en términos de una teoría de mapeo léxico (TML). La TML provee restricciones en la relación entre estructuras-f y estructuras-a, es decir, restricciones asociadas con argumentos particulares que parcialmente determinan su función gramatical. Contiene también mecanismos con los cuales los argumentos pueden suprimirse en el curso de la derivación léxica. En la LFG la información de las entradas léxicas y las marcas de la frase se unifican para producir las estructuras funcionales de expresiones complejas.
Gramática de estructura de frase
dirigida por el h-núcleo (HSPG)
La Gramática de Estructura de Frase dirigida por el h-núcleo (Head-driven Phrase Structure Grammar en inglés, HPSG) iniciada en [Pollard & Sag, 87] y revisada en [Pollard & Sag, 94] evolucionó directamente de la GPSG, para modificarla incorporando otras ideas y formalismos de los años ochenta. El nombre se modificó para reflejar el hecho de la importancia de la información codificada en los núcleos-h léxicos de las frases sintácticas, es decir, de la preponderancia del empleo de la marca head en el subconstituyente hija principal.
En la HPSG se consideró que no había nada de especial en los sujetos salvo que era el menos oblicuo de los complementos que el h-núcleo selecciona. Para la GB el sujeto difiere de los complementos en la posición que tiene en el árbol de proyecciones. Esta consideración empezó a cambiar en la revisión de 1994 de la HPSG, basándose en los trabajos de [Borsley, 90], donde se considera el sujeto en forma separada.
La HPSG en [Pollard & Sag, 94] amplía el rango de los tipos lingüísticos considerados, los signos consisten no solamente de la forma fonética sino de otros atributos o características, con la finalidad de tratar una mayor cantidad de problemas empíricos. En esta teoría los atributos de la estructura lingüística están relacionados mediante una estructura compartida. De acuerdo a principios especiales introducidos en la teoría, las características principales de los h-núcleos y algunas de las características de los nodos hijas se heredan a través del constituyente abarcador.
|
Figura 5. Estructura para el pronombre she |
El principal tipo de objeto en la HPSG es el signo (correspondiente a la estructura de características clase sign), y lo divide en dos subtipos disjuntos: los signos de frase (tipo frase) y los signos léxicos (tipo palabra). Las palabras poseen como mínimo dos atributos: uno fonético PHON (representación del contenido de sonido del signo) y otro SYNSEM (compuesto de información lingüística tanto sintáctica como semántica). Con los atributos y valores de estos objetos se crea una estructura de características como la de la
Figura 5 para la palabra she, y enseguida mediante diagramas de matrices atributo-valor (MAV) en la Figura 6. En la
Figura 5 las etiquetas de los nodos marcan los
valores y las etiquetas de los arcos los atributos. En la Figura 6 los valores intermedios aparecen en la parte baja.
Los cuadros marca ![]() establecen ligas de
valores.
establecen ligas de
valores.
De acuerdo a principios especiales introducidos en la teoría, las características principales de los h-núcleos y algunas de las características de los nodos hijas se heredan a través del constituyente abarcador.
Las frases tienen un atributo DAUGHTERS (DTRS), además de PHON y SYNSEM, cuyo valor es una estructura de características de tipo estructura de constituyentes (con-struc) que representa la estructura de constituyentes inmediatos de la frase. El tipo con-struc tiene varios subtipos caracterizados por las clases de hijas que aparecen en la frases. El tipo más simple y más empleado es el head-struc que incluye HEAD-DAUGHTERS (HEAD- DTR) y COMPLEMENT-DAUGHTERS (COMP-DTRS), que a su vez tienen atributos PHON y SYNSEM. Por ejemplo para la frase Kim walks se tiene la estructura en la Figura 7.
Un punto importante en la HPSG es que tiene varios principios: de constituencia inmediata de las frases (proyección de los núcleos-h), de subcategorización, de semántica, etc., que realmente son restricciones disyuntivas. En la HPSG se considera que hay dos tipos de restricciones: de la gramática universal y de la gramática particular. Así que las expresiones gramaticales de un lenguaje particular dependen de las interacciones entre un sistema complejo de restricciones universales y particulares.
Para tratar los diversos fenómenos que en la GPSG se consideraron como dependencias sin límite, la HPSG emplea dos principios de la gramática universal (de realización de argumentos y el principio de faltantes) y una restricción del lenguaje particular (la condición sujeto).
En la HPSG, el diccionario, un sistema de entradas léxicas, corresponde a restricciones de la gramática particular. Cada palabra en el diccionario tiene información semántica que permite combinar el sentido de palabras diferentes en una estructura coherente unida.
|
Figura6. Estructura de características mediante MAV
|
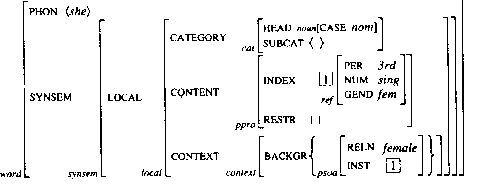
|
phrase Figura 7. Estructura de características mediante MAV
|
Algunas de las ideas clave en la HPSG son entonces:
1) Arquitectura basada en signos lingüísticos.
2) Organización de la información lingüística mediante tipos, jerarquías de tipos y herencia de restricciones.
3) La proyección de frases mediante principios generales a partir de información con abundancia léxica.
4) Organización de esa información léxica mediante un sistema de tipos léxicos.
5) Factorización de propiedades de frases en construcciones específicas y restricciones más generales.
De las reglas a las restricciones
En contraste con la tradición de las gramáticas generativas hay otra aproximación a la teoría generativa, igualmente sometida a la meta original de desarrollo de gramáticas formuladas de manera precisa, las gramáticas basadas en la noción de satisfacción de restricciones en lugar de derivaciones transformacionales. En las gramáticas de restricciones las entradas léxicas incorporan información acerca de las propiedades de combinación de las palabras con la finalidad de que solamente se requieran operaciones generales esquemáticas en la sintaxis.
Gramática categorial (CG)
La Gramática Categorial (Categorial Grammar, en inglés, CG), introducida por [Ajdukiewicz, 35], adquirió importancia para los lingüistas cuando [Montague, 70] la usó como el marco sintáctico de su aproximación para analizar la semántica del lenguaje natural. La idea central de la CG es que una concepción enriquecida de categorías gramaticales puede eliminar la necesidad de muchas de las construcciones que se encuentran en otras teorías gramaticales (por ejemplo, de las transformaciones). Uno de los conceptos básicos de la CG, a partir de los setenta, es que la categoría asignada a una expresión debe expresar su funcionalidad semántica directamente, idea tomada de [Montague, 70].
Una gramática categorial consiste simplemente de un diccionario junto con unas cuantas reglas que describen cómo pueden combinarse las categorías [Wood, 93]. Las categorías gramaticales se definen en términos de sus miembros potenciales para combinarse con otros constituyentes, por lo que algunos autores ven a la CG como una variedad de la Gramática de Dependencias (tema de la sección). Por ejemplo, las frases verbales y los verbos intransitivos pueden caracterizarse como aquellos elementos que cuando combinan con una frase nominal a su izquierda forman oraciones, una notación de esto es GN/O. Un verbo transitivo como obtener pertenece a la categoría de elementos que toman un GN en su lado derecho para formar una oración; esto puede escribirse (GN/O) /GN.
La suposición básica de la CG es que hay un conjunto fijo de categorías básicas, de las cuales se construyen otras categorías. Estas categorías básicas son: sustantivo, grupo nominal y oración; cada una de las categorías básica tiene características morfosintácticas determinadas por el lenguaje específico. Para el inglés, el grupo nominal tiene características de persona, número y caso, el sustantivo sólo tiene número y la oración tiene forma verbal.
La CG no hace una distinción formal entre categorías léxicas y no léxicas, por lo que, por ejemplo, un verbo intransitivo como dormir se trata como perteneciente a la misma categoría que una frase consistiendo de un verbo transitivo más un objeto directo, como obtiene un descanso.
La operación fundamental [Carpenter, 95] es concatenar una expresión asignada a una categoría funcional, con una expresión de su categoría de argumento para formar una expresión de su categoría resultante; el orden de la concatenación está especificado como una categoría funcional. Por ejemplo, un determinante será especificado como una categoría funcional que toma un complemento nominal a su derecha para formar un resultante grupo nominal; la concordancia se maneja mediante la identidad de características simples.
La CG es esencialmente un formalismo de estructura de frase donde hay asignaciones léxicas a expresiones básicas y un conjunto de reglas de estructura de frase que combinan expresiones para producir frases totalmente basadas en categorización sintáctica. La CG difiere de otros formalismos en que postula un conjunto infinito de categorías y de reglas de estructura de frase en lugar de conjuntos finitos como en las CFG.
La atracción principal de la CG fue su simplicidad conceptual y por su adecuación a la formulación de análisis sintácticos y semánticos estrechamente ligados. Esto último debido a que se considera que restringe las asignaciones léxicas a expresiones básicas y a construcciones sintácticas potenciales, de tal forma que solamente se permiten las combinaciones de categorías sintácticas semánticamente significantes. Se asume en esta teoría, que la estructura sintáctica determina una semántica funcional manejada por los tipos de composiciones.
Se considera que por el empleo de las restricciones sintácticas y semánticas, todas las generalizaciones específicas del lenguaje se determinan léxicamente. Una vez definido el diccionario para un lenguaje, las reglas universales de combinación sintáctica y semántica se emplean para determinar el conjunto de expresiones gramaticales y sus sentidos. De lo anterior se observa la responsabilidad que se deja en el diccionario y que implica que deben proveerse mecanismos léxicos que consideren generalizaciones del lenguaje específico dentro del diccionario.
Una de las motivaciones para emplear este formalismo es la facilidad con que puede extenderse para proveer análisis semánticos adecuados de dependencias sin límite y construcciones de coordinación. La CG [Carpenter, 97] está grandemente influenciada por la LFG, la GPSG, la HPSG y otros análisis gramaticales categoriales y de unificación.
Gramática de restricciones (GR)
En la Gramática de Restricciones (GR), Constraint Grammar en inglés [Karlsson et al, 95], toda la estructura relevante se asigna directamente de la morfología (considerada en el diccionario), y de mapeos simples de la morfología a la sintaxis (información de categorías morfológicas y orden de palabras, a etiquetas sintácticas). Las restricciones sirven para eliminar muchas alternativas posibles. Los autores indican que su meta principal es el análisis sintáctico orientado a la superficie y basado en morfología de textos sin restricciones. Se considera sintaxis superficial y no sintaxis profunda porque no se asigna ninguna estructura sintáctica que no esté en correspondencia directa con los componentes léxicos de las formas de palabra que están en la oración.
Ejemplos de esas restricciones para el inglés son:
· Una marca de verbo en presente, pasado, imperativo o subjuntivo, no debe ocurrir después de un artículo.
· La función sintáctica de un sustantivo en inglés es sujeto si va seguido de un verbo en forma activa y no intervienen sustantivos (de tipo sintáctico).
En la GR, la base de los postulados gramaticales son restricciones similares a reglas pero si el postulado gramatical falla se dispone de características probabilísticas opcionales. Para la GR tanto las restricciones (reglas gramaticales) como los postulados probabilísticos se requieren, no se trata de dos aproximaciones contrarias o de selección, aunque la relativa importancia probabilística es menor que en otras aproximaciones ya que aquí se enfatiza que el núcleo de la GR está destinado más a una naturaleza lingüística que a una probabilística.
Una idea relevante de la GR es poner en primer plano la descripción de ambigüedades, por lo que básicamente es un formalismo para escribir reglas de desambiguación. Divide el problema de análisis sintáctico en tres módulos: desambiguación morfológica, asignación de límites de cláusulas dentro de las oraciones y asignación de etiquetas sintácticas superficiales. Las etiquetas indican la función sintáctica superficial de cada palabra y las relaciones de dependencia básica dentro de la cláusula y la oración.
La noción de restricción se basa en hechos cercanos a la morfología superficial de la palabra, a la dependencia sintáctica entre palabras, y al orden de palabras, en lugar de basarse en principios abstractos de estructuramiento. La mayor desventaja es el trabajo necesario para establecer las restricciones, [Voutilainen, 95] postula 35 restricciones para desambiguar la palabra that y [Anttila, 95] emplea 30 restricciones sintácticas para la desambiguación del sujeto gramatical en inglés; los mismos autores postularon alrededor de 2000 restricciones para el inglés. La GR comparte con la LFG el uso de sujeto, objeto, etc. aunque como etiquetas que se toman del repertorio clásico de núcleo y modificadores, por lo que sus autores la consideran funcional.
Gramática de Adjunción de árboles (TAG)
La Gramática de Adjunción de Árboles (Tree Adjoining Grammar, en inglés, TAG) [Joshi, 85] es una gramática definida por los elementos (I, A) donde I y A son conjuntos finitos de árboles elementales. Los árboles elementales están asociados con un elemento léxico, es decir, con una palabra, son una unidad sintáctica y semántica, y tienen operaciones de combinación. Estas operaciones tienen restricciones lingüísticas.
La TAG puede generar lenguajes más generales que las CFG pero no puede generar todos los lenguajes sensitivos al contexto, así que la fuerza de la TAG es ligeramente mayor que las CFG, en cuanto a las gramáticas que genera.
Los árboles iniciales tienen sólo terminales en sus hojas, y los árboles auxiliares se distinguen por tener un elemento X* en la base del árbol, cuya proyección es el nodo raíz X. La idea es que I y A sean mínimos en cierto sentido, que el inicial no tenga recursión en ningún no-terminal y que en los auxiliares, X corresponda a una estructura mínima recursiva que pueda llevar a la derivación si hay recursión en X.
Las operaciones son: adjunción y sustitución. La adjunción es una operación que separa un nodo interior del árbol inicial para adjuntar un árbol auxiliar. Al separar el nodo interior, el subárbol bajo éste, se transfiere a partir del elemento X*. La operación de sustitución simplemente sustituye un nodo hoja del árbol inicial por el árbol del auxiliar que se sustituye.
Operación de adjunción
En la TAG, cada elemento léxico se llama ancla de la estructura correspondiente sobre la cuál especifica restricciones lingüísticas. Así que las restricciones son locales a la estructura anclada. Cada nodo interno de un árbol elemental se asocia con dos estructuras de rasgos: tope y bajo. La estructura-bajo contiene información relacionada al subárbol con raíz en el nodo (es decir, relación con sus descendientes), y la estructura-tope contiene información relacionada con al superárbol en ese nodo. Los nodos de sustitución tienen solamente una estructura-tope, mientras que los otros nodos tienen ambas estructuras: tope y bajo. En las dos operaciones definidas se unifican las estructuras de rasgos.
Gramáticas de dependencias.
[Mel’cuk, 79] explicó que un lenguaje de estructura de frase describe muy bien cómo los elementos de una expresión en lenguaje natural combinan con otros elementos para formar unidades más amplias de un orden mayor, y así sucesivamente. Un lenguaje de dependencias, por el contrario, describe cómo los elementos se relacionan con otros elementos, y se concentra en las relaciones entre unidades últimas sintácticas, es decir, entre palabras.
La estructura de un lenguaje también se puede describir mediante árboles de dependencias, los cuales presentan las siguientes características:
· Muestra cuáles elementos se relacionan con cuáles otros y en que forma.
· Revela la estructura de una expresión en términos de ligas jerárquicas entre sus elementos reales, es decir, entre palabras.
· Se indican explícitamente los roles sintácticos, mediante etiquetas especiales.
· Contiene solamente nodos terminales, no se requiere una representación abstracta de agrupamientos[15].
Con las dependencias se especifican fácilmente los tipos de relaciones sintácticas. Pero la membresía de clase sintáctica (categorización) de unidades de orden más alto (GN, GP, etc.) no se establece directamente dentro de la representación sintáctica misma, así que no hay símbolos no-terminales en representaciones de dependencias.
Una gramática cercana a este enfoque de dependencias es la Gramática Relacional (Relational Grammar en inglés, RG) [Perlmutter, 83] que adopta primitivas que son conceptualmente muy cercanas a las nociones relacionales tradicionales de sujeto, objeto directo, y objeto indirecto. Las reglas gramaticales de la RG se formularon en términos relacionales, reemplazando las formulaciones iniciales, basadas en configuraciones de árboles. Por ejemplo, la regla pasiva se establece más en términos de promover el objeto directo al sujeto, que como un rearreglo estructural de grupos nominales.
Muy pocas Gramáticas de Dependencia han sido desarrolladas recientemente (ver [Fraser, 94], [Lombardi & Lesmo, 98]). A continuación, describimos los formalismos más representativos: Dependency Unification Grammar (DUG), Word Grammar (WG) y MeaningÛText Theory (MTT).
Selección semántica y contexto local (DUG)
La historia de la Gramática de Unificación de Dependencias (Dependency Unification Grammar en inglés) [Hellwig, 86] comienza al inicio de los años setenta con el desarrollo del sistema llamado PLAIN [Hellwig, 80] aplicando diferentes métodos para la sintaxis y la semántica, y combinando una descripción sintáctica basada en dependencias llamada Gramática de Valencias con Transformaciones para simular relaciones lógico semánticas. Desde los inicios empleó categorías complejas con atributos y valores, y un mecanismo de subsumisión para establecer la concordancia. En los años ochenta enfatizó su filiación a las gramáticas de unificación resultando en la DUG. Desde entonces tanto PLAIN como DUG se han aplicado en diversos proyectos [Hellwig, 95] y se han ido modificando.
La noción de unificación corresponde a la idea de unión de conjuntos, para la mayoría de los propósitos. La unificación es una operación para combinar o mezclar dos elementos en uno solo que concuerde con ambos. Esta operación tiene gran importancia en estructuras de rasgos (género, etc.). La unificación difiere en que falla si algún atributo está especificado con valores en conflicto, por ejemplo: al unificar dos atributos de número dónde uno es plural y otro es singular, ver como ejemplo [Briscoe & Carroll, 93].
La DUG ha sido implementada en el Instituto de Lingüística Computacional de la Universidad de Heidelberg como un marco de trabajo para análisis sintáctico de lenguajes naturales [Hellwig, 83]. Las DUG para el alemán, el francés y el inglés han sido elaboradas para los proyectos ESPRIT y LRE Translator's Work Bench (TWB) y Selecting Information from Text (SIFT).
Tres conceptos son los más importantes en esta teoría como gramática de dependencias: el lexicalismo, los complementos y las funciones. Por lexicalismo considera la suposición de que la mayoría de los fenómenos en un lenguaje dependen de los elementos léxicos individuales, suposición que es válida para la sintaxis (igualando los elementos léxicos con las palabras). Los complementos son importantes para establecer todas las clases de propiedades y relaciones entre objetos en el mundo verdadero. La importancia de las funciones entre otras categorías sintácticas está relacionada con que cada complemento tiene una función específica en la relación semántica establecida por el h-núcleo. La función concreta de cada complemento establece su identidad y se hace explícita por una explicación léxica, por ejemplo: el verbo persuadir requiere un complemento que denote al persuasor, otro complemento que denote la persona persuadida y aún otro que denote el contenido de la persuasión.
En la DUG, una construcción sintáctica estándar consiste de un elemento h-núcleo y un número de constituyentes que completan a ese elemento h-núcleo. Para este propósito se necesitan palabras que denoten la propiedad o relación, y expresiones que denoten las entidades cualificadas o relacionadas. La morfología y el orden de palabras marcan los roles de los constituyentes respectivos en una oración. En ausencia de complementos, el rector, es decir el verbo, está insaturado. Sin embargo, es posible predecir el número y la clase de construcciones sintácticas que son adecuadas para complementar cada palabra rectora particular.
Como la DUG se ha aplicado principalmente al alemán considera el orden de palabras en el árbol de dependencias. Este árbol difiere de los árboles usuales de gramáticas de dependencias en que los nodos tienen etiquetas múltiples. El orden de palabras es entonces otro atributo Se examina el orden lineal de los segmentos que se asocian a los nodos del árbol de dependencias. DUG considera características de posición con valores concretos que se calculan y se sujetan a la unificación.
Descripción del conjunto de objetos
sintácticos
(WG, MTT)
Consideramos el conjunto de objetos sintácticos de los verbos como la variedad de marcos de subcategorización que pueden estar relacionados unos a otros a través de alternaciones de valencias. Pocos formalismos consideran todas las posibilidades de estas alternaciones como punto focal de su descripción sintáctica, entre ellos la Gramática de Palabra (Word Grammar en inglés, WG), y la Teoría Texto Û Significado (Meaning Û Text Theory en inglés, MTT).
Gramática de palabra
La Gramática de Palabra (en inglés, Word Grammar, WG), para su autor [Hudson 84], es una teoría general de la estructura del lenguaje y aunque sus bases son lingüísticas y más específicamente gramaticales, considera que su mayor intención es contribuir a la sicología cognitiva ya que ha desarrollado la teoría desde el inicio con el propósito de integrar todos los aspectos del lenguaje en una teoría que sea compatible con lo que se conoce acerca de la cognición general, aunque este objetivo no se ha logrado todavía.
Hudson ve la WG como una teoría del lenguaje en forma cognitiva, como una red que contiene tanto la gramática como el diccionario y que integra el lenguaje con el resto de la cognición. La semántica en WG sigue a [Lyons, 77], [Halliday, 67, 68] y [Fillmore, 76] en lugar de seguir la lógica formal.
La suposición de la WG es que el lenguaje puede analizarse y explicarse en la misma forma que otras clases de conocimiento o comportamiento. Como su nombre lo sugiere, la unidad central de análisis es la palabra. Las palabras son las únicas unidades de la sintaxis, y la estructura de la oración consiste totalmente de las dependencias entre palabras individuales. Por lo que la WG es claramente parte de la tradición de gramáticas de dependencias.
Una segunda versión, la English Word Grammar (EWG) [Hudson, 90] introduce cambios importantes para detallar el análisis, la terminología y la notación, en lo que concierne a la teoría sintáctica, con la adición de estructura superficial y la virtual abolición de características.
La mayor parte del trabajo en la WG trata de la sintaxis aunque también se ha desarrollado cierto trabajo en la semántica y algo más tentativo en la morfología [Hudson, 98]. Para la WG las palabras no nada más son las unidades más grandes de la sintaxis sino que también son las unidades más pequeñas por lo que las estructuras sintácticas no pueden separar bases e inflexiones, esto hace que la WG sea un ejemplo de sintaxis independiente de la morfología[16].
Teoría texto Û significado
La Teoría Texto Û Significado (en inglés, Meaning Û Text Theory, MTT), desde el ensayo en la publicación [Mel’cuk & Zholkovsky, 70] ha sido elaborada y refinada en diversos artículos y libros. La concepción de cómo los significados léxicos interactúan con las reglas sintácticas es de las mejor desarrolladas y con más principio en la literatura.
La meta de la teoría es modelar la comprensión del lenguaje como un mecanismo que convierta los significados en los textos correspondientes y los textos en los significados correspondientes. Aunque no hay una correspondencia de uno a uno, ya que el mismo significado puede expresarse mediante diferentes textos, y un mismo texto puede tener diferentes significados.
La MTT emplea un mayor número de niveles de representación, tanto la sintaxis como la morfología y la fonología se dividen en dos niveles: profundo (D) y superficial (S). Bajo estos términos, la morfología profunda (DMorR) es más superficial que la sintaxis superficial (SSintR). Las nociones de profundo y más superficial significan que conforme progresa la representación de la semántica a la fonología superficial (SFonR) se vuelve más y más, detallada y específica del lenguaje.
La MTT es un sistema estratificado. Cada oración se caracteriza simultáneamente por siete diferentes representaciones, cada una especifica la oración desde la perspectiva del nivel correspondiente. Cada nivel de representación se mapea al adyacente mediante una de las seis componentes de la MTT. En la Figura 8 se muestran estos siete niveles como en [Mel’cuk, 88].
En la Figura 9, se presenta un ejemplo del árbol de dependencias de acuerdo a la MTT de [Mel’cuk, 88] para la frase She lov’d me for the dangers I had pass’d, and I lov’d her that she did pity them (en español, Ella me ama por los peligros que yo he pasado y yo la amo por la lástima que ella les tiene), donde se hace una comparación con un árbol de constituyentes. Este árbol de dependencias presenta dos ventajas: requiere exactamente dieciocho nodos (el número de palabras), el orden lineal de los nodos es absolutamente irrelevante ya que la información se preserva a través de las dependencias etiquetadas.
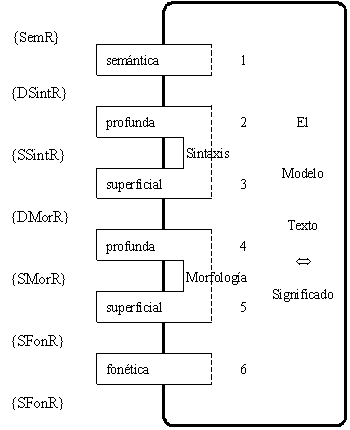
Cada nivel de representación se considera como un lenguaje separado en el sentido de que tiene su propio vocabulario diferente y reglas distintas de combinación. La transición de un nivel a otro es un proceso de tipo traducción que involucra el cambio tanto de los elementos como de las relaciones entre ellos, pero que no cambia el contenido informativo de la representación.
Tres conjuntos de conceptos y términos son esenciales en la MTT en su aproximación a la sintaxis:
· Una situación y sus participantes (actuantes).
· Una palabra y sus actuantes semánticos que forman la valencia semántica de la palabra.
· Una palabra y sus actuantes sintácticos que forman la valencia sintáctica de la palabra.
|
Figura 9. Ejemplo de estructura de dependencias en la MTT
|
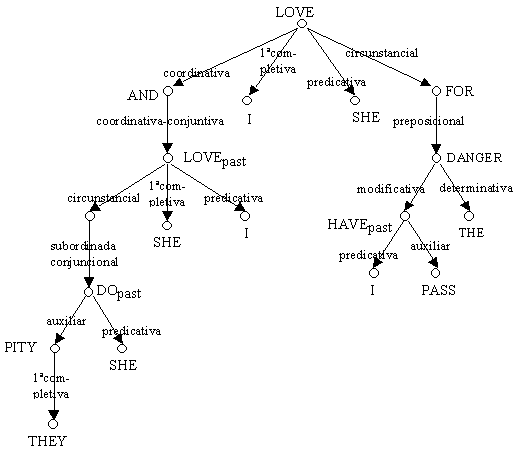
La situación, en esta teoría, significa un bloque de la realidad reflejada por la lexis de un lenguaje dado. Los actuantes semánticos de una situación deben y pueden determinarse sin ningún recurso de la sintaxis y corresponden a esas entidades cuya existencia está implicada por su significado léxico. Por ejemplo, para [Mel’cuk, 88] la diátesis es la correspondencia entre los actuantes: semánticos, de la sintaxis profunda, y de la sintaxis superficial.
Los actuantes semánticos y los roles temáticos son similares aunque los roles temáticos siguiendo la tradición de los constituyentes tratan de generalizar los participantes y la MTT los particulariza, describiéndolos para cada verbo específico.
La MTT usa la noción de valencia sintáctica, es decir, la totalidad de los actuantes sintácticos de la palabra, esta noción es similar a la característica de subcategorización de la vieja gramática transformacional y a los argumentos de la teoría X-barra. La diferencia es que la valencia sintáctica se define independientemente de, y en yuxtaposición a, la valencia semántica. Esto hace posible usar claramente consideraciones semánticamente especificadas en la definición de la valencia sintáctica y marcar una diferencia entre ellas y las consideraciones sintácticas.
Métodos sin estructura sintáctica
Existen otros métodos en el procesamiento lingüístico de textos, considerados propiamente sin estructura sintáctica que están más orientados a los aspectos léxico y semántico, es decir, a los niveles morfológico y semántico. Si bien el interés de presentarlos aquí no se basa en información sintáctica, si se basa en presentar conceptos que dichos métodos aislaron de la sintaxis y que ahora se incorporan en los formalismos gramaticales más avanzados.
Análisis mediante expertos de palabras.
En [Small, 87], el autor presenta la teoría computacional Análisis Sintáctico mediante Experto de Palabra (Word Expert Parsing en inglés, WEP), una aproximación para entender el lenguaje natural como un proceso, de interacción de las palabras, distribuido y no uniforme.
La organización del WEP se basa en la creencia de que el agrupamiento de palabras para formar secuencias con sentido es un proceso activo que tiene éxito solamente gracias a la aplicación altamente idiosincrásica del conocimiento léxico, es decir, se fragmenta el texto y se comprende el significado de las piezas porque se conoce cómo las palabras particulares involucradas interactúan unas con otras.
Una excepción ocurre con las palabras que se ven por primera vez y entonces se aplica un proceso dirigido por la hipótesis, controlado por las palabras a su alrededor. Los autores insisten en el hecho de que las palabras son claramente la base de todos los fenómenos encontrados dentro del lenguaje.
Small basó su proposición en el hecho de que la estructura construida para la mayoría de los lenguajes naturales no había llevado de una forma directa a una interpretación semántica simple de las oraciones, basándose en su sintaxis.
La mayoría de las teorías de comprensión del lenguaje humano suponen que los lenguajes se basan en las regularidades (sintácticas, semánticas y conceptuales), en cambio [Small, 87] y [Rieger & Small, 82] parten de una vista totalmente opuesta. Para ellos los sistemas de comprensión del lenguaje deben ser capaces de representar de forma más correcta las irregularidades que las regularidades.
En el WEP se considera a cada palabra como la fuente esencial del conocimiento necesario para la comprensión, de los conocimientos adecuados de sí misma y de sus relaciones con las otras palabras y conceptos. Para realizar esta tarea se liga un experto a cada palabra. El experto de cada palabra trata de determinar el rol significante de la palabra en el contexto, es decir, interactúa con otros expertos de palabras y con un modelo de proceso para adquirir el conocimiento conceptual apropiado para hacer las inferencias correctas.
Finalmente, los expertos para un fragmento de texto llegan a un acuerdo mutuo del significado del fragmento. Entre las funciones que realiza cada experto se encuentran las interacciones léxicas. En [Small, 87] los autores presentan un ejemplo de análisis para la frase The man throws in the towel, ejemplo en el cual el experto más importante es el experto throws que construye un concepto de acción y refina su significado basándose en el contexto y en las restricciones léxicas circundantes.
La mayor desventaja es que el modelo representa el conocimiento lingüístico y por lo tanto debe especificarse totalmente para cada una de las palabras. Aunque fue muy reducida su aplicación, comparte conceptos con las gramáticas de dependencias, en ambas se considera que las palabras definen una información primordial que establece los enlaces con otras palabras. También comparte conceptos con las gramáticas de restricciones ya que cada experto de palabra especifica sus reglas de desambiguación.
Gramáticas de caso.
En las gramáticas de caso se considera que la estructura sintáctica es accesoria y sólo es importante si puede ayudar a la construcción de una representación en la cuál se especifiquen las diferencias de los roles semánticos. En estas gramáticas son primordiales los papeles o roles temáticos, por ejemplo, en las frases siguientes:
Paco adora el triciclo.
Paco comió un helado.
Paco pescó un resfriado.
La estructura sintáctica de las tres frases es similar, se componen de un grupo nominal (Paco), un verbo y un grupo nominal formado por un determinante y un sustantivo; sin embargo, en esta teoría, lo más importante es que hay un sentido muy diferente en las tres que no está relacionado con la estructura sintáctica. En la primera frase se expresa una edad, en la segunda una acción, y en la última frase se expresa un cambio.
Otra diferencia más puede notarse en las frases siguientes dónde se utiliza la preposición con de maneras muy diversas, para introducir una herramienta, un material, una manera en que se realiza la acción y el motivo.
Paco lo construyó con madera de cedro.
Paco lo construyó con un propósito específico.
Paco lo construyó con precaución.
Paco lo construyó con una herramienta de carpintería.
Entre las gramáticas de caso, Fillmore considera los diferentes roles semánticos [Fillmore 68, 77], Grimes considera los roles específicos [Grimes, 75] y Schank estudia las dependencias conceptuales [Schank et al, 72].
[Fillmore, 68] sostiene que se puede identificar un conjunto de casos semánticos que permiten mostrar las relaciones de sentido que existen entre los sustantivos o grupos nominales y el verbo en frases simples. Su argumentación se funda en ejemplos como el siguiente:
John broke the window with the hammer. (Javier rompió la ventana con un martillo.)
The hammer broke the window.(El martillo rompió la ventana.)
The window broke. (La ventana se rompió.)
En estas tres frases se describe la misma acción romper, y muestran que la misma función gramatical (sujeto) puede rellenarse con tres diferentes participantes. Así que tanto John como the hammer y the window son roles sintácticos iguales pero roles semánticos diferentes. Este fenómeno tiene una consecuencia importante, al establecer que las nociones de sujeto y objeto no son lo profundas que se requerirían para hacer esas diferencias. Por lo que la posición de la semántica se vuelve más importante que la sintáctica en esta teoría.
[Fillmore, 68] propuso el siguiente conjunto de roles semánticos: agente, instrumento, dativo, factitivo, lugar y objeto. [Fillmore, 71] modificó el conjunto a: agente, contra-agente, objeto, resultado, instrumento, fuente, meta y paciente. Aunque sus pretensiones fueron reducidas, su teoría tuvo una gran influencia en los formalismos gramaticales.
Otras teorías de casos buscaron un grado de abstracción mayor y trataron de identificar conceptos generales aclarando las relaciones que los diferentes casos tienen entre ellos. Por ejemplo, [Grimes, 72] tuvo la meta de encontrar un conjunto de casos más abstractos. Divide los casos en diferentes grupos: los roles de orientación (relativas al movimiento y a la posición), los roles de proceso (cambios de edad) y roles específicos. Una de las diferencias esenciales con la teoría de Fillmore es que un grupo nominal específico puede tener distintos roles semánticos.
[Schank et al, 72] intentó identificar nociones primitivas independientes del lenguaje, desarrolló un sistema de representación de sentidos denominadas dependencias conceptuales, fundadas sobre las relaciones conceptuales entre los objetos y las acciones. Definió once primitivas en función de las cuales describió todas las acciones y precisó los roles conceptuales que pueden unir esas primitivas a los conceptos. Las diferencias fundamentales con las otras teorías son las siguientes:
· Un solo caso semántico puede unir entidades diferentes (por ejemplo, el caso beneficiario hace intervenir el donador y el receptor).
· Los casos ligados a una acción conceptual de base son todos obligatorios (si no son realizados en la frase, se pueden hacer inferencias para encontrarlos).
· Los casos semánticos unen las entidades conceptuales (y no los elementos sintácticos como GN, GP) a una de las once acciones conceptuales de base (y no a verbos auxiliares de superficie).
Las gramáticas de caso se han empleado con utilidad en muchas representaciones semánticas de lenguajes. Estas gramáticas tienen la ventaja única de permitir el análisis de frases no normalizadas o que no respetan la sintaxis correcta, sin embargo el problema principal es identificar un conjunto universal de casos. Aún con la representación más ambiciosa, de Schank, de identificar nociones primitivas independientes del lenguaje solamente se han empleado en dominios muy precisos [Schank et al, 72], [Schank, 80].
Esta noción de roles semánticos generalizados es compartida por los formalismos más recientes en el enfoque de constituyentes y con la misma dificultad de identificar un conjunto universal de roles.
Convergencia de los dos enfoques
Antes de presentar la convergencia de los dos enfoques presentados, exponemos una comparación de los formalismos presentados en cuanto a implementación y descripción de dependencias lejanas. Aunque aquí presentamos los formalismos más representativos en cada uno de ellos, existen otras variantes de los mismos por lo que generalizamos los nombres de los formalismos.
Desde el punto de vista de implementación, los formalismos gramaticales tienen una importante influencia sobre la forma de representación de las frases, representaciones que son la base de todo el razonamiento posterior en los programas informáticos. Las gramáticas generativas son inadecuadas relativamente para este fin y no tuvieron aplicación real en informática. De entre ellas, la GPSG es la extensión más interesante por su ambición de tratar los aspectos semánticos.
En la evolución de las gramáticas generativas, éstas se tuvieron que aumentar para incluir la concordancia y en algunas versiones se consideró la unificación de los rasgos. Una característica fundamental de las gramáticas funcionales, como la LFG es que permiten integrar aspectos semánticos, en este sentido constituyeron uno de los ejes de investigación más importantes. Pusieron de relieve también la importancia primordial del léxico dentro de las descripciones lingüísticas.
Ninguno de los formalismos hasta ahora desarrollados abarca todos los fenómenos lingüísticos, es decir, no tiene una cobertura amplia del lenguaje. El fenómeno de dependencias lejanas motivó una cantidad significante de investigación en los formalismos gramaticales. En la gramática generativa en su primera etapa, se manejaron fuera de la CFG. La LFG y la GPSG propusieron métodos de capturar las dependencias con el formalismo de CFG, empleando rasgos o características. Otra línea ha sido tratar de definir nuevos formalismos que sean más poderosos que la CFG y que puedan manejar dependencias lejanas, como las TAG.
La última tendencia es en formalismos más orientados hacia los mecanismos computacionales, como la HPSG, la CG, la DUG. Las dos primeras emplean información de subcategorización (tema de la siguiente sección) extensivamente y haciéndolo simplifican de manera significativa la CFG a expensas de un diccionario más complicado. En la DUG, como en las gramáticas de dependencias, se definen todos los objetos de las palabras por lo que los diccionarios son el elemento central ya que no se emplean reglas.
En la siguiente tabla presentamos cómo se ha ido disminuyendo el número de reglas y transformaciones a expensas de la riqueza de información en el diccionario, y la aparición de restricciones e integración semántica. La marca X denota existencia, la marca — denota ausencia, y las otras marcas indican movimientos de incremento y reducción.
|
|
Reglas |
Transf. |
Diccio- |
Restric- |
Integra |
Estructura |
Estructura |
|
GGT |
X |
X |
— |
— |
— |
— |
— |
|
ST |
X |
X |
— |
— |
— |
— |
— |
|
EST |
X |
X |
X |
— |
— |
— |
— |
|
GB |
X |
1 |
X |
— |
— |
— |
— |
|
GPSG |
X- |
— |
X |
— |
— |
— |
— |
|
LFG |
X-- |
— |
X+ |
X |
X |
X |
X |
|
CG |
X-- |
— |
X++ |
X |
X |
— |
— |
|
HPSG |
X--- |
— |
X+++ |
X |
X |
X |
— |
|
— |
— |
X+++ |
X |
X |
— |
— |
|
|
MTT |
— |
— |
X+++ |
X |
X |
X |
X |
- inicio de reducción + concepción mejorada
-- reducción ++ importante
--- casi eliminación +++ mayoría de la información
En los años setenta los términos lexicismo y lexicalismo se utilizaron para describir la idea de emplear reglas léxicas para capturar fenómenos que eran analizados previamente por medio de transformaciones. Por ejemplo, mediante una regla léxica se podía obtener a partir de un verbo una forma de adjetivo, de pelear obtener peleonero. Por lo que se establecía que las reglas sintácticas no debían hacer referencia a la composición interna morfológica. El lexicalismo ahora, en forma muy burda, puede considerarse como una aproximación para describir el lenguaje, que enfatiza el diccionario a expensas de las reglas gramaticales.
Resulta engañosa esta caracterización inicial porque el lexicalismo cubre un rango amplio de aproximaciones y teorías que capturan este énfasis léxico en formas muy diferentes. Por ejemplo, dos enfoques principales son: que tanta información como sea posible acerca de la buena formación sintáctica esté establecida en el diccionario, y que las reglas sintácticas no deben manipular la estructura interna de las palabras.
El lexicalismo estricto para [Sag & Wasow, 99] es que las palabras, formadas de acuerdo a una teoría léxica independiente, son los átomos de la sintaxis. Su estructura interna es invisible a las restricciones sintácticas. Para él, el lexicalismo radical define que todas las reglas gramaticales se ven como generalizaciones sobre el diccionario. El principio de lexicalismo estricto, para este autor, tiene su origen en el trabajo de [Chomsky, 70], quien desafió los intentos previos para derivar nominalizaciones (por ejemplo, la compra de una pelota por el niño) a partir de cláusulas (por ejemplo, el niño compró una pelota) vía transformaciones sintácticas.
Aunque el lexicalismo originalmente se vio relacionado con la reducción de potencia y capacidad de las reglas transformacionales, actualmente se ve de una forma más general relacionada a la reducción de la potencia y capacidad de las reglas sintácticas de cualquier clase, y por lo tanto con un énfasis mayor en los diccionarios.
Los formalismos de constituyentes en su evolución han ido modificando conceptos que los aproximan a las dependencias. La LFG mantuvo la representación de estructura de frase para representar la estructura sintáctica de superficie de una oración, pero tuvo que introducir la estructura funcional para explicar explícitamente los objetos sintácticos, la cuál es esencialmente una especificación de relaciones de dependencia sobre el conjunto de lexemas de la oración que se describe.
La RG constituye una desviación decisiva de la estructura de frase hacia las dependencias, al establecer que los objetos sintácticos deben considerarse como nociones primitivas y deben figurar en las representaciones sintácticas. La relación gramatical como ser el sujeto de, o ser el objeto directo de es una clase de dependencia sintáctica.
La HPSG, en su última versión [Sag & Wasow, 99] está formulada en términos de restricciones independientes del orden. Como heredera del enfoque de constituyentes incluye restricciones en sustitución de las transformaciones, pero se basa en la observación de la reciente literatura sicolingüística de que el procesamiento lingüístico humano de la oración tiene una base léxica poderosa: las palabras tienen una información enorme, por lo que ciertas palabras clave tienen un papel de pivotes[17] en el procesamiento de las oraciones que las contienen, esta noción está presente en la MTT desde sus inicios. También la Word Grammar [Hudson 84] y el Word Experter Parser [Small, 87] proclaman esta base sicolingüista.
Esta observación, modifica el concepto de estructura de frase en la HPSG, donde la noción de estructura de frase se construye alrededor del concepto h-núcleo léxico, una sola palabra cuya entrada en el diccionario especifica información que determina propiedades gramaticales cruciales de la frase que proyecta. Entre esas propiedades se incluye la información de POS (los sustantivos proyectan grupos nominales, los verbos proyectan oraciones, etc.) y relaciones de dependencias (todos los verbos requieren sujeto en el inglés, pero los verbos difieren sistemáticamente en la forma en que seleccionan complementos de objeto directo, complementos de cláusula, etc.), esta noción y su similitud con la MTT quedará de manifiesto en la siguiente sección dedicada a las valencias sintácticas.
El lexicalismo, a nuestro entender, representa la convergencia en los enfoques de constituyentes y de dependencias. Aunque las dependencias, desde su origen le han dado una importancia primordial a las palabras y a las relaciones léxicas entre ellas, el enfoque de constituyentes vía el lexicalismo considera, en su versiones más recientes (por ejemplo la última revisión a la HPSG), muchos de los conceptos de aquellas.
Las entradas léxicas en diccionarios manuales llevan una gran cantidad de información diferente acerca de los lexemas. Una pieza muy importante de información que algunos de los lexemas llevan es la información que algunos lingüistas llaman subcategorización. La información de subcategorización especifica la categoría del lexema, su número de argumentos, la categoría de cada argumento y usualmente la posición respecto al lexema, adicionalmente a veces se incluye también la información de las características como género, número, etc.
El ejemplo más simple de subcategorización es la diferencia entre un verbo transitivo y uno intransitivo; un verbo transitivo debe tener un objeto a fin de ser gramatical, por ejemplo:
María ablanda la carne.
*María ablanda.
Y un verbo intransitivo no puede tener un objeto, por ejemplo:
María cojea.
*María cojea una pierna.
En el ejemplo previo, ablandar es un verbo y debe aparecer inmediatamente precediendo un grupo nominal GN (la carne). Se dice que ese verbo subcategoriza un GN. A partir de esta clasificación simple, transitivos e intransitivos, se amplía la información para considerar todos los casos posibles, por ejemplo la doble transitividad [Cano, 87] considera que el verbo subcategoriza dos complementos.
En el procesamiento lingüístico de textos por computadora, básicamente la subcategorización se refiere al número de argumentos y la categoría de cada argumento pero la forma de definir cuáles son y cómo se representan los argumentos subcategorizados por un lexema dado ha diferido en los diversos formalismos en los dos enfoques considerados en el análisis sintáctico. En el enfoque de dependencias, donde se emplean muchos de los términos de la gramática tradicional, para nombrar esta información se emplea el término valencia sintáctica que nosotros seguimos en el título y en algunos subtítulos de esta sección.
En el enfoque de constituyentes, la subcategorización se representa en términos sintácticos, es decir, por su estructura y parte del habla. Los verbos pueden subcategorizar diferentes tipos, no solamente GNs, por ejemplo, el verbo dar subcategoriza un grupo nominal (GN) y un grupo preposicional (GP), en ese orden: Juan da un libro a María.
Aunque, desde el punto de vista de este enfoque, la subcategorización se describe de una manera más fija, contrasta con las colocaciones. Las colocaciones describen los contextos locales, que son importantes ya de una manera preferencial o estadística, en la frase. Por ejemplo, en el proyecto DECIDE para construcción de recursos: diccionarios y corpus principalmente, [DECIDE, 96], se considera la información de subcategorización (subcat) como una lista con frecuencias de aparición de diferentes palabras unidas a la palabra seleccionada, en un corpus. En este diccionario, una entrada para answer (responder) es:
(1) answer + whatever
Lo que significa una ocurrencia de whatever después del verbo answer. Este ejemplo muestra una ocurrencia del verbo precediendo inmediatamente a la palabra whatever, que solamente tiene un significado estadístico y que no representa la realización de un complemento.
En el enfoque de constituyentes o gramáticas de frase, la selección semántica no es una condición ni suficiente ni necesaria para la subcategorización. Así que la mayoría de estas teorías lingüísticas incluyen en el marco de subcategorización predicados[18] o frases cuya ocurrencia es obligatoria en el contexto local de la frase del predicado aunque no sean seleccionados semánticamente por él.
Dentro del enfoque de constituyentes presentamos, en esta sección, la descripción de las valencias sintácticas para los formalismos GB, GPSG, LFG, CG y HPSG.
Las teorías lingüísticas basadas en dependencias incluyen, en la información de las valencias sintácticas, las frases cuya ocurrencia es obligatoria en el contexto semántico del verbo. Adicionalmente, algunos formalismos, consideran los complementos circunstanciales, con una clara distinción entre ellos y los especificados semánticamente. Este razonamiento se basa en separar las alternaciones de valencias, específicas de cada lexema, y los complementos circunstanciales, comunes a distintos lexemas.
Tanto en la WG como en la MTT las valencias sintácticas describen únicamente las frases cuya ocurrencia es obligatoria en el contexto semántico del verbo. En cambio, la DUG y la Gramática Funcional de Dependencias (FDG, Functional Dependency Grammar, en inglés) [Tapanainen et al, 97] adicionalmente describen los predicados circunstanciales. Dentro del enfoque de dependencias, presentamos la descripción de las valencias sintácticas para los formalismos DUG y MTT.
Así que, en general, la valencia sintáctica o subcategorización concierne con la especificación de frases que son preponderantes al contexto del verbo porque son seleccionadas por el lexema, sintácticamente o semánticamente o ambas. Aunque todas las teorías lingüísticas tienen medios para expresar los aspectos sintácticos, y morfosintácticos, de subcategorización, la referencia directa a la selección semántica puede expresarse únicamente en aquellos formalismos que incluyen un nivel de representación semántica.
Desde el punto de vista del procesamiento lingüístico de textos, la especificación de la estructura de las valencias sintácticas es necesaria para codificar la información concerniente al contexto y al orden de palabras a fin de limitar el análisis y la generación del lenguaje natural, este argumento se explicará más adelante. La complejidad resulta por el aspecto multidimensional de la estructura de las valencias sintácticas, porque la subcategorización involucra referencia a diversos niveles de descripción gramatical, aspectos morfológicos, sintácticos y semánticos de la especificación de las palabras, y también por la interfase entre estos niveles de descripción gramatical.
Se ha puesto una gran atención a esta información en los diccionarios computacionales como COMLEX [Grishman et al, 94] no solamente para verbos sino para adjetivos y sustantivos que llevan complementos. En el procesamiento lingüístico de textos, esta información ayuda a establecer las combinaciones posibles de los complementos en la oración. Pero también tienen importancia relevante para la traducción automática, por ejemplo [Fabre, 96] estudió las relaciones predicativas de sustantivos para interpretar compuestos nominales en francés e inglés.
Las teorías lingüísticas difieren en la cantidad de información que proveen en la valencia sintáctica de un verbo. Esto se debe, en su mayoría, a las diferentes tendencias al usar principios y reglas sintácticas para expresar generalizaciones lingüísticas, con el consecuente cambio de énfasis más lejano o más próximo a la especificación léxica. En esta sección presentamos una revisión de diversos enfoques adoptados en las teorías lingüísticas y a continuación un análisis de ellos.
Subcategorización en GB
En el desarrollo de la GB se percataron de la gran redundancia de información en las reglas de estructura de frase y en los marcos de subcategorización. Por ejemplo, la información de que un verbo transitivo va seguido de un objeto tipo GN estaba codificada tanto en la regla que expande el GV como en el marco de subcategorización del verbo. La GB movió esta información a los marcos de subcategorización de los núcleos-h. La razón para hacer esto es que cada verbo selecciona-c (c por categoría) un cierto subconjunto del rango de proyecciones máximas.
La teoría de la X-barra presenta la idea de que se encuentran patrones similares dentro de cada una de las estructuras internas de diferentes frases en un lenguaje. Por ejemplo, tanto el verbo como las preposiciones preceden a su objeto. El h-núcleo de una unidad lingüística es esa parte de la unidad que da su carácter esencial. Así, el h-núcleo de un GN es el sustantivo, similarmente, un verbo es el h-núcleo de un GV, y así sucesivamente.
En este formalismo, la frase es una proyección
del núcleo. Se consideran dos niveles de proyección. Por ejemplo, en el nivel
más bajo el núcleo léxico y los argumentos (constituyentes a los cuales
subcategoriza el núcleo) denotados con una barra o un apóstrofo (![]() , N’), y en el siguiente nivel esa misma estructura
con modificadores y especificadores, denotados con dos barras o dos apóstrofos
(
, N’), y en el siguiente nivel esa misma estructura
con modificadores y especificadores, denotados con dos barras o dos apóstrofos
(![]() , N’’). Esta última es la máxima proyección, donde N’’
es igual que GN, V’’ igual a GV, etc.
, N’’). Esta última es la máxima proyección, donde N’’
es igual que GN, V’’ igual a GV, etc.
Un ejemplo de modificadores y especificadores son los adjetivos y artículos para N’. No hay duda de que cualquier proyección máxima (es decir, GA, GN, GP, O', o GV) puede ser el argumento de un h-núcleo, en principio, aunque típicamente, núcleos-h diferentes seleccionan elementos diferentes del conjunto de proyecciones máximas como sus argumentos. El verbo ablandar selecciona GN, decir selecciona O' (como en dijo que la carne estaba lista), etc.
De estas nociones se ve como la información de subcategorización limita el análisis y la generación de lenguaje natural. La subcategorización se usa como un filtro en el análisis y en la generación de estructuras de frase, en el sentido siguiente: si tratamos, por ejemplo, de hacer la inserción léxica de ablandar en una estructura donde es hermana izquierda de una O', esa estructura con ese h-núcleo se descartará, porque su subcategorización requiere un GN.
En la GB la relación indirecta entre el verbo y su sujeto es un aspecto crucial de la teoría total y está presente en todos los análisis. El sujeto, en inglés, no aparece como hermano del h-núcleo del GV y por lo tanto no puede ser subcategorizado por ese h-núcleo. El dominio de subcategorización está limitado al dominio de la proyección máxima que contiene el h-núcleo, y es realmente esta noción de dominio dentro de la proyección máxima, en lugar de la noción de ser hermana, la que es importante en esta teoría. El sujeto no está dentro del dominio del verbo ya que la proyección máxima del verbo es GV. Esto resulta en las diferencias tanto del comportamiento sintáctico del sujeto y de los complementos (que no son sujetos) como en el hecho de que el sujeto es externo al GV (ver Figura 10). Así, los complementos que no son sujetos son los únicos que pueden subcategorizarse en este formalismo.
El sujeto es el GN inmediatamente dominado por O, y el objeto es el GN inmediatamente dominado por el GV. En la GB, esto se representa comúnmente por las notaciones [GN, S] y [GN, GV] respectivamente. El uso de los términos sujeto y objeto en este formalismo son las abreviaturas de esas definiciones estructurales. Desde este punto de vista, el objeto de la estructura-d puede volverse en el sujeto de la estructura-s en la construcción pasiva.
La subcategorización en la GB se describe en un nivel de descripción sintáctica donde los argumentos de un predicado se juntan en un conjunto donde cada elemento corresponde a un papel temático indexado [Williams, 80]. Dentro de la estructura de argumentos de un predicado puede haber una posición distinguida que funciona como el papel temático del h-núcleo de la estructura de argumentos como una totalidad. Este papel temático se denota como el argumento externo ya que puede ser asignado solamente afuera de la proyección máxima de su predicado.
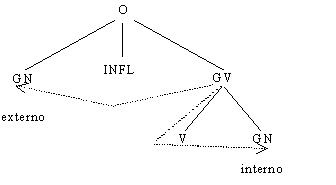
Figura 10. Relación indirecta entre sujeto y verbo
En versiones posteriores de la GB [Chomsky, 86], a diferencia de la mayoría de las otras teorías gramaticales, las frases se asumen como las proyecciones máximas de la frase con inflexión, la que introduce la morfología verbal (por ejemplo, tiempo y aspecto). En la Figura 10, INFL es la inflexión.
La descripción en la Figura 11, corresponde a [Sells, 85], la subcategorización (selección categorial) en paréntesis angulares y la estructura de argumentos (selección semántica) en paréntesis, donde el argumento externo está subrayado siguiendo la notación de [Williams, 81]. La información de los papeles temáticos restantes, es decir, de los argumentos internos, está disponible únicamente dentro de la primera proyección del predicado.
La realización sintáctica de los papeles temáticos en la estructura del argumento se limita y asegura por el Principio de Proyección y por el Criterio-Theta, que a continuación se presentan.
· Principio de Proyección. Las representaciones en cada nivel sintáctico (es decir la forma lógica y las estructuras -d y -s) se proyectan desde el diccionario, siguiendo las propiedades de subcategorización de los elementos léxicos.
|
ablandar, V, <GN> (Agente, Tema) dar, V, <GN, GP> (Agente, Tema, Meta)
Figura 11. Relación indirecta entre sujeto y verbo
|
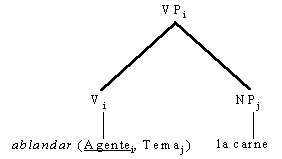
· Criterio-_. Cada argumento sostiene uno y sólo un papel-_, y cada papel-_ está asignado a uno y solamente un argumento.
El criterio-q dice en forma simple que el significado de un predicado determina qué argumentos gramaticales tendrá. El principio de proyección garantiza que la estructura determinada por el significado léxico del h-núcleo no sea alterado en forma esencial.
También hay un principio que relaciona la subcategorización y la asignación de papeles-T o papeles temáticos (comúnmente llamado marcado-T). La subcategorización se relaciona a posiciones en un arreglo y el marcado-T al contenido léxico dominado por esa posición. Si _subcategoriza la posición ocupada por _, entonces _marca-T a _.
Como la subcategorización está relacionada a posiciones, debe codificarse algún tipo de posición de argumento temático para el sujeto, en la entrada léxica del verbo. En [Chomsky, 86] se asume que la selección categorial (selección-c) puede derivarse como la Realización Estructural Canónica (CSR) de su categoría semántica. Por ejemplo, la CSR (rol paciente) es un grupo nominal. Consecuentemente, solamente la selección semántica (selección-s) necesita expresarse en el diccionario.
En el enfoque de constituyentes, la GB dentro de ella, también se consideran los predicados no seleccionados semánticamente, como los casos de complementos de verbos cuyo sujeto es pleonástico (extraposition, en inglés), verbos que se denominan raising verbs[19], en inglés, por ejemplo seem, y verbos que contrastan con estos últimos, los denominados control verbs[20] o equi[21] verbs, en inglés. Por ejemplo:
· Sujeto pleonástico: It annoys people that dogs bark. (Molesta a la gente que los perros ladren). El pronombre it representa dogs bark, el sujeto del verbo annoy. Sintácticamente existen dos argumentos correspondientes al mismo argumento semántico.
· Verbos raising: Mary seems to be happy. (María parece ser feliz.). El verbo seem (subject raising, en inglés) es transparente en cuanto a que María también es sujeto de ser. En la frase I expected Mary to be happy (Yo espero que María sea feliz.), el objeto del verbo expect (object raising, en inglés) es el sujeto del verbo ser.
La teoría de control en la GB maneja sintácticamente los verbos equi. En estos verbos, el sujeto de verbos no finitos, es decir, de grupos verbales en infinitivo, se representa estructuralmente como la categoría vacía PRO cuya relación a su controlador está regulada por la Teoría del Ligamento en términos del comando-c, que expresa algo así como la noción de esa subparte de un árbol para la cual una categoría determinada _no es inferior jerárquicamente.
María i intenta [PRO i dormir]
Esto implica que la subcategorización verbal, de cláusula, se expresa siempre en términos de oraciones en lugar de hacerlo en términos de grupos verbales.
Las dependencias verbales que emergen en las construcciones expletivas[22] y de sujeto raising se manejan también sintácticamente. Por ejemplo, un verbo raising como seem subcategoriza una frase pero no tiene argumento externo. Existen dos casos cuando se subcategoriza una cláusula:
· Si la cláusula subcategorizada no es finita, el sujeto se mueve a una posición de sujeto en el arreglo para satisfacer el Filtro de Caso[23] puesto que solamente un GV con marca de tiempo puede asignar caso nominativo a su sujeto. Por ejemplo: Johni seems [ti to sleep] donde ti es la huella del sujeto i.
· Si la cláusula subcategorizada es finita, por ejemplo en It seems that John sleeps (parece que Juan duerme), el elemento pleonástico it se inserta en la posición sujeto del arreglo para satisfacer el Principio de Proyección Extendida que además del Principio de Proyección anterior requiere que todas las cláusulas tengan sujeto.
Por último, las construcciones con objeto raising también se consideran como si involucraran subcategorización de oraciones. Un verbo como believe subcategoriza una frase de infinitivo a cuyo sujeto se le asigna caso por el verbo en el arreglo, a través de límites de oraciones, como en Mary believes [S John to be intelligent] que es una ocurrencia descrita como marcado de caso excepcional, en [Chomsky, 86].
Subcategorización en GPSG
La GPSG hace uso de características sintácticas, de entre ellas, dos ejemplos son las siguientes: una para mostrar el POS y otra para mostrar el nivel (palabras, grupo de palabras, frase). Además desarrolla una teoría apropiada de características, expresándolas mediante pares de atributos y valores. No solamente se consideran como atributos las categorías como número, caso y persona, sino también el nivel, esto es influencia de la teoría X-barra, y también con la misma interpretación.
En la GPSG se emplea un atributo para la subcategorización, llamado SUBCAT, y se asigna un valor único a cada posible marco en el cual pueda ocurrir una categoría de nivel cero. SUBCAT es una característica del h-núcleo, es decir, de HEAD. Por ejemplo, si la entrada léxica comer sólo dice que es un verbo transitivo, es decir, [SUBCAT TRANS], entonces el hecho de que los verbos transitivos, y sólo ellos, ocurran con un nodo hermano GN puede establecerse mediante una regla ID como:
![]()
donde V0 es el verbo, V1 es el grupo verbal y V2 es la máxima proyección. La GPSG comparte, con la GB, el análisis de que la máxima proyección del verbo es la oración. Una categoría puede dominar un elemento léxico si y sólo si la categoría es consistente con la entrada léxica de ese elemento. Así que sólo un verbo que sea TRANS, como comer, puede ocurrir bajo V0 [TRANS] y uno intransitivo como cojear no podrá.
Realmente los verbos no tienen un marco de subcategorización, sino que tienen una indicación que apunta al tipo de estructura en la que aparece. Para considerar todos los posibles tipos, GPSG utiliza números enteros como valores de SUBCAT, y los incluye en las entradas léxicas y en las reglas ID, correspondiendo a las estructuras posibles. A continuación se presentan unos ejemplos:
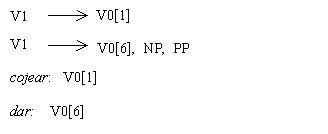
La GPSG considera posible que un verbo tenga múltiples subcategorizaciones. Cada estructura de subcategorización corresponderá con una entrada léxica separada pero relacionada al lexema. En la GPSG existen postulados de sentido que imponen relaciones sistemáticas entre los sentidos de verbos homónimos. Estos postulados de sentido son precisamente postulados semánticos, y es en términos semánticos que la GPSG captura el hecho de múltiples subcategorizaciones.
Un problema evidente de esta teoría es que implica un gran número de reglas ID. Algo de la redundancia en ellas se elimina mediante el uso de postulados LP separados (por ejemplo, para dictar el orden de los nodos hermanos en un subárbol), y otra parte se elimina por los principios de características. Pero la esencia de la objeción permanece.
Los objetos sintácticos como sujeto y objeto no se consideran nociones primitivas en la GPSG, sino que se definen en términos de otras primitivas de la teoría. En la GPSG, siguiendo a [Dowty, 82] esas relaciones se definen en términos de la estructura semántica, es decir, en la estructura función-argumento de la semántica. Por ejemplo, un verbo transitivo como buscar requiere dos argumentos. El sujeto se define, sólo semánticamente, como el último argumento, el objeto es el siguiente del último, etc.
La diferencia entre verbos raising y equi se define en la subcategorización de los verbos, es decir, en las reglas-ID que producen los nodos que los dominan inmediatamente en las estructuras sintácticas. Por ejemplo:

Donde +NORM es la abreviatura de AGR NP[NFORM NORM], que establece la concordancia del grupo nominal. Mientras para el verbo seem se permite cualquier sujeto, para el verbo try es necesario que el sujeto mediante concordancia (NORM) no pueda ser ni it ni there. Una complejidad se presenta al establecer los valores de omisión para seem. VFORM es una característica de HEAD que distingue partes del paradigma verbal: FIN (finito), INF (infinitivo), BSE (forma base), PAS (pasiva), etc.
En la GPSG, el h-núcleo sólo puede subcategorizar sus hermanas, por lo que los sujetos no se subcategorizan. Realmente no hay subcategorización para el sujeto, aunque este hecho a veces es dudoso porque la existencia de la característica AGR para manejar la concordancia entre sujeto y verbo, tiene el efecto como de permitir la subcategorización para los sujetos.
Subcategorización en LFG
La subcategorización en la LFG, como en otras gramáticas de constituyentes, se basa en una representación sintáctica de la estructura de los argumentos del predicado. Pero en la LFG, la noción de función gramatical ocupa un papel central para determinar cuáles argumentos, seleccionados semánticamente por un predicado, están realizados semánticamente y cómo.
En [Bresnan, 82], las funciones gramaticales se definen como primitivas sintácticas universales de la gramática y se clasifican de acuerdo a dos parámetros principales: la habilidad de subcategorizar y la restricción semántica. Las funciones subcategorizables que pueden asignarse a los argumentos de los lexemas son los sujetos, los objetos y los complementos de los grupos verbales de la oración. Las funciones que no son subcategorizables corresponden a frases adjuntas que no pueden asociarse con los argumentos de los lexemas.
Existen otras funciones como Tópico y Foco que se asignan a las frases desplazadas, como en la topicalización, las preguntas y las cláusulas relativas. Se considera que la habilidad de subcategorizar de estas dos funciones está sujeta a variación lingüística, ya que es posible que exista en algunos lenguajes y en otros no.
En la LFG las funciones que se pueden subcategorizar difieren con respecto al rango de tipos de argumentos con los cuales pueden asociarse [Kaplan, 94], y se dividen en restringidas y sin restricción:
· Las funciones gramaticales semánticamente no restringidas no están ligadas de una manera inherente a las restricciones específicas de selección. Por ejemplo, la función sujeto, que puede realizar argumentos no temáticos como el sujeto de seem en la frase It seems that John sleeps; o aunque los sujetos son a menudo agentes, también pueden ser tema, como en la pasiva.
· Las funciones gramaticales restringidas semánticamente son las que están más intimamente ligadas a la semántica, es decir, solamente pueden ponerse por pares con argumentos de tipos semánticos específicos. Por ejemplo, las funciones oblicuas (objeto directo, objeto indirecto) [Rappaport, 83], que siempre son temáticas, es decir, que nunca se asocian con elementos pleonásticos.
En la siguiente figura se presenta la clasificación general de las funciones gramaticales y más adelante se describen individualmente.
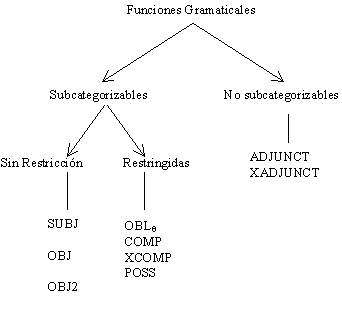
OBLq significa oblicuo; POSS es genitivo prenominal, como en professor’s knowledge (conocimiento del profesor).
También los complementos y los adjuntos se clasifican, en funciones cerradas o abiertas. Cerradas significa que están completas, tienen sus propios controladores, y abiertos lo opuesto, requieren antecedentes. En los ejemplos de complemento cerrado y de función adjunta cerrada (COMP, ADJ) los GN subrayados son los controladores.
· Complementos. Los complementos cerrados son los COMP y los abiertos XCOMP.
Beto cree [que María es honesta]COMP
Beto intenta [ser un buen médico]XCOMP
· Adjuntos. Los adjuntos cerrados son los ADJUNCT y los abiertos XADJUNCT.
[Beto empezaba a alegar]ADJ, María salió despavorida.
[Aún estando enojado]XADJ Beto comió tranquilamente.
Los objetos sintácticos son asociaciones de funciones gramaticales con papeles temáticos o con valores que no son temáticos. Estas asociaciones se codifican en el diccionario, donde cada verbo está representado como un lexema que consiste de una estructura de argumentos del predicado y una asignación de función gramatical. Por ejemplo:
Estructura de argumento de predicado break <agente, tema>
Asignación de función gramatical ((SUJ), (OBJ))
Donde la estructura de argumentos del predicado de un lexema es una lista de los argumentos para los cuales existen restricciones de selección. La asignación de función gramatical de una forma léxica es una lista de sus funciones subcategorizadas sintácticamente.
La asignación de funciones gramaticales se sujeta a un número de condiciones universales. Por ejemplo, todos los predicados univalentes se asignan a SUJ, y todos los predicados bivalentes se asignan a un SUJ y a un OBJ. Una condición muy importante sobre la asignación de función gramatical es la Biuniquidad de las Asignaciones Función-Argumento [Bresnan, 82] que establece una relación uno a uno entre argumentos y funciones gramaticales dentro de la estructura predicado-argumento de un lexema.
Esas listas de asignación de función gramatical sirven como marcos de subcategorización. La subcategorización se revisa en la estructura funcional mediante dos condiciones: Completeness y Coherence [Kaplan & Bresnan, 82]:
· La completitud asegura que todos los argumentos subcategorizados estén presentes en la estructura funcional, es decir, que no haya menos argumentos. Por ejemplo, descarta frases como *Juan compra, *seems.
· La coherencia restringe la ocurrencia de funciones gramaticales subcategorizables a las listadas en la forma léxica del verbo, es decir, que no haya argumentos de más. Por ejemplo, descarta frases como *Juan cojea Memo.
Finalmente, el control funcional maneja léxicamente los verbos de control y raising con referencia a funciones gramaticales. Por ejemplo, el control del sujeto con ambos tipos, raising y de control, se establece en el diccionario en las partes relevantes de las entradas léxicas como en seem y try.
seem V (PRED) = ‘seem < (XCOMP) > (SUJ)’
(XCOMP SUJ) = (SUJ)
try V (PRED) = ‘try < (XCOMP) (SUJ)>’
(XCOMP SUJ) = (SUJ)
En la descripción del verbo try se especifica que el sujeto es temático. Ya que el control se trata léxicamente y las categorías no vacías se usan para unir el sujeto complemento, se obtiene que ambos verbos (raising y control) subcategorizan grupos verbales en lugar de oraciones, como se considera en la GB.
En los trabajos de [Bresnan & Kanerva, 88] y [Bresnan & Moshi, 89], entre otros, se revisó la teoría de los objetos sintácticos. Los objetos sintácticos como SUJ, OBL, etc., pasaron de especificaciones atómicas a definiciones en términos de características funcionales más primitivas. La teoría resultante, la Teoría Léxica de Mapeo, consiste de cuatro componentes básicos
· Jerarquía de papeles léxicos. La jerarquía incluye los siguientes papeles en orden descendente: agente, beneficiario y maleficiario, receptor y experimentador, instrumental, paciente y tema, locativo, motivo; se crea una jerarquía temática universal en base a ellos.
· Funciones sintácticas no compuestas. Las funciones sintácticas se descomponen de acuerdo a las características [± r], temáticamente restringidos o sin restricción, y [± o], objetivo o no, por ejemplo:
![]()
Individualmente, cada valor de las dos características define una función gramatical parcialmente especificada, por ejemplo:
![]()
· Principios de mapeo léxico. Los papeles semánticos se asocian con funciones gramaticales especificadas parcialmente de acuerdo a los Principios de Mapeo Léxico: clasificaciones de roles intrínsecos, clasificaciones de roles morfoléxicos y clasificaciones de roles por omisión.
· Condiciones de buena formación. Después de que los principios de mapeo se han aplicado, cualquier función gramatical restante no bien especificada está totalmente instanciada. Esta instanciación es libre tanto como se observen los principios de Biuniquidad y de Condición de sujeto. El primero establece que dentro de la estructura de un predicado-argumento de una forma léxica hay una relación de uno a uno entre funciones gramaticales y argumentos. La condición sujeto establece que cada forma léxica debe tener un sujeto.
Como ejemplo de la aplicación de esta Teoría léxica de mapeo se presenta el tratamiento de la forma pasiva, de [Bresnan & Kanerva, 88]. Para el verbo buscar, antes de la conversión a pasiva, los papeles de agente y tema del verbo están intrínsecamente asociados con funciones gramaticales parcialmente especificadas, como se muestra a continuación:
![]()

La regla pasiva introduce la especificación funcional [+r], es decir, restringida temáticamente, para el papel superior de una forma léxica. Cuando la pasiva se aplica a la estructura de argumentos de predicado para el verbo buscar, el papel del agente adquiere la especificación [+r] que en conjunto con [-o] define una función oblicua. El argumento agente de un verbo pasivo se realiza como un complemento oblicuo, mientras el tema puede ser sujeto u objeto. Las restricciones de buena formación inducidas por la condición de sujeto requieren que se elija la opción sujeto en este caso. A continuación el ejemplo del proceso descrito, con una representación esquemática:
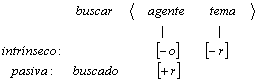
_____________________________________
![]()
Subcategorización en CG
En la aplicación de la Gramática Categorial al estudio de lenguajes naturales se ha supuesto una colección universal de esquemas de estructura de frase, también se ha supuesto que la estructura sintáctica determina la semántica funcional, de tipo composicional. De lo anterior deriva que todas las generalizaciones de lenguaje específico deben determinarse léxicamente, por lo que una vez establecido el diccionario para el lenguaje pueden aplicarse las reglas universales de combinación sintáctica y semántica.
En el proyecto ACQUILEX [Sanfilippo, 93] se aplicó la Gramática Categorial de Unificación y en base a la descripción del marco ahí empleado se presenta a continuación la subcategorización. Una descripción más amplia de las estructuras de grupos verbales para el inglés se encuentra en [Carpenter, 95].
La información de subcategorización en esta aproximación se encuentra dentro de la estructura de signo. Los signos están formados por una conjunción de pares atributo–valor de información ortográfica (ORTH), sintáctica (CAT) y semántica (SEM). Las palabras y las frases se representan como estructuras de características, con tipos, mediante signos.
[ORTH: orth
CAT: cat
SEM: sem]
El atributo categoría de un signo puede ser básico o complejo:
· Las categorías básicas son las estructuras binarias de características que consisten de un tipo categoría, y una serie de pares atributo valor que codifican información morfosintáctica (cuandoes necesaria). Los tipos cat básicos que se emplean son: sustantivo (n), grupo nominal (np) y oración (sent).
[CAT–TYPE: cat–type
M–FEATS: m–feats]
Por simplicidad, se abrevian como: cat–type [m–feats]
· Las categorías complejas se definen recursivamente, dejando que el tipo cat instancie una estructura de características con los siguientes atributos: resultado (RES) que puede tomar como valor una categoría básica o una compleja, activo (ACT) que es de tipo signo, y direccción (DIR) que codifica el orden de combinación, relativo a la parte activa del signo (por ejemplo: hacia adelante o hacia atrás).
[RES: cat
DIR: dir
ACT: sign]
En los verbos, la parte activa de la estructura de categorías codifica las propiedades de subcategorización. Por ejemplo, sujeto (nom) y objeto (acc) en verbos transitivos:
[ORTH: < love>
CAT: [RES: [RES: sent
ACT: [np–signo
CAT: nom] ]
ACT: [np–sign
CAT: np [acc] ] ] ]
La información semántica de un signo es una fórmula. Esta fórmula consiste de:
· Un índice (IND) que es una entidad que provee información referida a un tipo ontológico. El índice “e” indica eventualidades, “o, x, y, z” objetos individuales
· Un predicado (PRED), el argumento de un predicado puede ser una entidad o una fórmula.
· Al menos un argumento (ARG1) que puede ser a su vez una entidad o una fórmula, subsumidas por sem.
[IND: entidad
PRED: pred
ARG1: sem]
Por ejemplo, la estructura de características:
[IND: [1] x
PRED: book
ARG1: [1] ]
donde [1] indica valores reentrantes. Por simplicidad las fórmulas se presentan en forma lineal, pueden abreviarse como <x1> book (x1) donde x1 es una variable con nombre.
La clasificación de tipos de subcategorización involucra la definición de las estructuras semánticas predicado-argumento, de las estructuras de categorías, y de los signos de los verbos. Así que primero presentamos las descripciones de estos tres tipos de estructuras con los ejemplos únicos necesarios para mostrar, al final, la subcategorización completa de verbos de dos y tres argumentos.
Para describir las estructuras semánticas predicado-argumento, siguieron la clasificación de [Dowty, 89]. Así que el contenido semántico de las relaciones temáticas se expresa en términos de conceptos de grupos prototípicos: los roles proto-agente (p-agt) y los roles proto-paciente (p-pat), determinados para cada elección de predicado. [Sanfilippo & Poznanski, 92] además de formalizar los proto-roles como superconjuntos de grupos específicos de componentes significantes que son instrumentos en la identificación de clases semánticas de verbos, introdujeron adicionalmente dos conceptos:
· Un tercer proto-rol, prep, para argumentos preposicionales. Estos prep se consideran semánticamente restringidos, empleando los términos de la LFG.
· Los predicados sin contenido (no-q) para caracterizar la relación entre un GN pleonástico y su verbo rector.
Los verbos se caracterizan como propiedades de eventualidades, y los roles temáticos son relaciones entre eventualidades e individuos, por ejemplo, p-agt(e1, x). Una clasificación semántica primaria de los tipos de verbos se obtiene en términos de la aridad del argumento, es decir, del número de argumentos. Las diferencias adicionales se hacen según qué tipo de argumentos verbales se codifican, por ejemplo: proto-agente, proto-paciente, preposicional oblicuo/indirecto, preposicional de objeto, no - temático, pleonástico, predicativo (como xcomp), oracional (como comp).
A continuación, las principales estructuras semánticas de verbos, con ejemplos:
STRICT–INTRANS–SEM Intransitivos estrictos. Juan (proto-agente) cojea
<e1> and (<e1> pred (e1), <e1> p–agt (e1, x))
STRICT–TRANS–SEM Transitivos estrictos. Juan (p-ag) bebe una cerveza (p-pat)
<e1> and (<e1> pred (e1), <e1> and (<e1>p–agt(e1,x), <e1>p–pat(e1,y)))
OBL–TRANS/DITRANS–SEM Ditransitivos. Mary gave Bill a book.
Transitivos con complemento oblicuo.Mary give a book to Bill
<e1> and (<e1> pred (e1), <e1> and (<e1>p–agt(e1,x),
<e1> and (<e1>p–pat(e1,y), <e1> prep (e1,y) )))
P–AGT–SUJ–INTRANS–XCOMP/COMP–SEM Intransitivos con sujeto temático y complemento tipo cláusula (representada por verb-sem). Juan intentó venir y Juan pensó que María vendría.
<e1> and (<e1> pred(e1), <e1> and (<e1>p–agt(e1,x), verb– sem))
Las estructuras de categoría se distinguen de acuerdo a los valores de las características RES y CAT. Por ejemplo, el CAT de intransitivos estrictos establece que el resultado es una categoría básica de tipo sent y la parte activa es un grupo nominal, es decir, solamente hay selección de sujeto. A partir de tipos básicos se van construyendo tipos más complejos de categoría. Los transitivos estrictos emplean la categoría de intransitivo estricto, dando adicionalmente la categoría acusativo al objeto.
STRICT–INTRANS–CAT STRICT–TRANS–CAT
[RES: sent [RES: strict–intrans–cat
ACT: np–sign] ACT: [np–sign
CAT: np[acc]]]
Las restricciones morfosintácticas se codifican en signos seleccionados (activos). Por ejemplo, en la definición de la categoría ditransitiva el argumento extremo tiene caso acusativo (por ejemplo, Juan da a María un libro) y en la definición de categoría para transitivos que toman un complemento de frase preposicional tiene caso preposicional p-case (por ejemplo Juan dio un libro a María).
DITRANS–CAT OBL–TRANS–CAT
[RES: strict–trans–cat [RES: strict–trans–cat
ACT: [np–sign ACT: [np–sign
CAT: np[acc]]] CAT: np[p–case]]]
Los restantes tipos de categorías están organizados en comp-cat para verbos que toman un complemento oracional y en xcomp-cat para verbos que toman un complemento predicativo, los xcomp-cat además se dividen de acuerdo a si el control está involucrado o no.
Los signos de los verbos se definen enlazando signos activos en la estructura de categorías a las ranuras de argumento en estructuras de argumentos de predicados, es decir, los enlaces se hacen a través de las estructuras semánticas y de categorías. Estos enlaces se realizan mediante enlaces reentrantes, por ejemplo, con la marca [1] en la estructura que se muestra para verbos intransitivos estrictos.
[strict–intrans–sign
CAT: ACT: [np–sign
SEM: [1] <e1>p–agt(e1, x)]
SEM: [strict–intrans–sem
<e1> and (<e1> pred (e1), [1])]]
Solamente consideran patrones para verbos que tienen un máximo de 3 argumentos por lo que solamente necesitan dos patrones adicionales de enlace general.
[dos–argumentos–verbo–signo [tres–argumentos–verbo–signo
CAT: [RES: [RES: sent CAT: [RES: [RES: [RES: sent
ACT: [sign ACT: [sign
SEM: [1]]] SEM: [0]]]
ACT: [sign
SEM: [1]]]
ACT: [sign ACT: [sign
SEM: [2]]] SEM: [2]]]
SEM: <e1> and ( and (pred(e1),[1]),[2])] SEM: <e1> and (and (and (pred (e1),[0]),[1]),[2])]
Finalmente, a continuación se presentan las estructuras completas de dos-argumentos-verbo-signo y de tres-argumentos-verbo-signo. En los primeros se consideran el tipo transitivo estricto y para sujetos de verbos equi que toman un complemento de verbo en infinitivo. En los segundos se consideran los ditransitivos y los transitivos que toman un objeto oblicuo.
DOS–ARGUMENTOS–VERBO–SIGNO
STRICT–TRANS–SIGNO SUJ–EQUI–INTRANS–GVINF–SIGNO
[CAT: strict–trans–cat [CAT: intrans–vpinf–control–cat
SEM: strict–trans–sem] SEM:p–agt–subj–intrans–xcomp/comp–sem]
TRES–ARGUMENTOS–VERBO–SIGNO
DITRANS–SIGNO OBL–TRANS–SIGN
[CAT: ditrans–cat CAT: [RES: strict–intrans–cat
SEM: obl–trans/ditrans–sem ] ACT: [np–sign
CAT: np[p–case]]]
SEM: intrans–obl–sem]
Los argumentos subcategorizados se posicionan en la estructura de categorías de predicados de acuerdo a la jerarquía oblicua. Por ejemplo, el argumento del sentido “meta” de ditransitivos y de transitivos que subcategorizan un grupo preposicional (DITRANS–SIGNO y OBL–TRANS–SIGN) es el signo extremo en la estructura de categorías, aunque solamente en los ditransitivos le precede el objeto “tema”. La diferencia en el orden de palabras se maneja sintácticamente [Sanfilippo, 93].
Este formalismo emplea categorías de control para describir la estructura sintáctica de los verbos equi y raising. Crea un modelo donde la marca de reentrancia dice que el signo activo del complemento (por ejemplo un complemento sujeto) se controla por el signo activo inmediatamente precedente. Todas las categorías de control heredan este modelo. El control se expresa mediante entidades que se igualan y que parcialmente describen la semántica de los signos activos. El argumento controlador puede ser el sujeto o el objeto según si el verbo es transitivo o intransitivo. La transitividad está determinada por la presencia de un signo-np acusativo activo. Las categorías reales de control se construyen agregando más especializaciones a las descripciones de control básicas.
En cuanto al trato del sujeto de verbos de extraposición, la CG emplea adicionalmente una entidad sin contenido, dummy, para la caracterización semántica de grupos nominales pleonásticos.
Subcategorización en HPSG
En la HPSG, existe una característica especial para la información de la subcategorización de los signos, la característica sintáctica local SUBCAT. En la característica SUBCAT se codifican las diversas dependencias entre un h-núcleo y sus complementos. Es de notar que a diferencia de otros formalismos, en la HPSG se incluyen los sujetos como especificadores.
SUBCAT tiene como valor una lista de synsems (parcialmente especificados). Como se mencionó en la sección 1.2-HPSG, los synsems tienen como valor local a CATEGORY y a CONTENT. El atributo CATEGORY de un signo contiene información de su POS, requerimientos de subcategorización y marcadores posibles. El atributo CONTENT provee información de su estructura de argumentos. Así que los signos léxicos pueden ejercer restricciones en la selección y manejo de la categoría tanto como en la asignación de papel y caso.
El Principio de Subcategorización en la HPSG, que es un principio de la gramática universal, maneja el flujo (ascendente en la estructura sintáctica) de la información de subcategorización de las trayectorias de proyección. Este principio se expresa en términos de un valor en forma de lista:
DAUGHTERS | HEAD-DAUGHTER | SYNSEM | LOCAL | CATEGORY | SUBCAT, esta lista se obtiene a su vez, de la concatención de los valores lista de SYNSEM y de DAUGHTERS (ver sección 1.2-HPSG).
El Principio de subcategorización establece, de forma general, que el valor SUBCAT de una frase es el valor SUBCAT del h-núcleo del lexema menos las especificaciones ya satisfechas por algún constituyente en la frase. La versión más reciente de HPSG [Sag & Wasow, 99], separa en dos características, SUJ y COMPLS, la característica inicial SUBCAT [Pollard & Sag, 87, 94] para separar el sujeto de los complementos restantes.
En la HPSG la subcategorización se basa en la definición de la estructura de argumentos y cómo se relacionan los roles con los objetos sintácticos (sujeto, objeto, etc.), en la jerarquía de esos objetos sintácticos, en la selección diferente de las categorías de los argumentos, y en las características morfosintácticas de esas categorías. En la HPSG, la asignación de roles es la conexión entre los constituyentes de una expresión y los constituyentes que están presentes en la situación descrita. Por ejemplo, la entrada léxica para un verbo ditransitivo como give asigna papeles semánticos a sus dependientes subcategorizados.
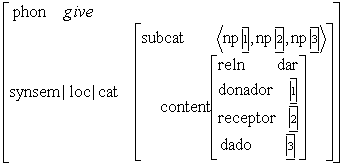
En la lista SUBCAT se numeran las variables asociadas con los objetos sintácticos, éstos unifican con las variables correspondientes de los roles en la descripción CONTENT. La jerarquía de objetos sintácticos se muestra en la lista SUBCAT, donde el sujeto es el primer elemento, el primer objeto es el segundo elemento, y el tercer elemento es el segundo objeto, como en la frase Mary gives Bill a book. Cada uno unifica con su correspondiente papel, el sujeto unifica con el donador, el primer objeto unifica con el donador, y el segundo objeto unifica con el objeto dado. Notar cómo en este ejemplo para el inglés la posición de los constituyentes en SUBCAT es primordial para identificar cada uno con su rol semántico.
Como se observa del ejemplo anterior, la concepción jerárquica de los objetos sintácticos es esencial. A excepción del sujeto, que tiene su propia lista de características, los otros objetos sintácticos se definen en términos del orden de la jerarquía, que corresponde a la noción gramatical tradicional de sesgadura de objetos sintácticos, con elementos más oblicuos que ocurren más a la izquierda. Los razonamientos para la teoría jerárquica de objetos sintácticos se basa en cuatro clases diferentes de generalizaciones lingüísticas:
· En el orden de constituyentes. En muchos, pero no en todos los lenguajes, el orden superficial de constituyentes y sus objetos sintácticos parecen estar sujetas a restricciones mutuas. Como en el inglés, notar que en el ejemplo anterior el sujeto y los dos complementos se describen igual en SUBCAT, con grupos nominales y solamente el orden estricto permite identificar cada uno de ellos.
· Que involucran la teoría de control. Los complementos controlados encuentran su controlador en un argumento simultáneo menos oblicuo.
· Sobre el ligamento de pronombres y reflexivos. Las relaciones comando-o (de oblicuo, para establecer la teoría de ligamento en la HPSG) se expresan en términos de jerarquía oblicua.
· Sobre el funcionamiento de reglas léxicas. Por ejemplo, la conversión a pasiva puede promover un último o un penúltimo grupo nominal a una posición de sujeto.
En la HPSG se consideró el hecho de que las dependencias léxicas inciden de manera crucial en la selección de categoría. Existen restricciones de subcategorización que no pueden reducirse a distinciones semánticas o funcionales. En los ejemplos siguientes, se muestran verbos cuyos sentidos están muy cercanos, pero imponen restricciones específicas diferentes sobre la categoría sintáctica de sus argumentos.
Pat trusts Kim. /*Pat trusts on Kim. (Pat confía en Kim.)
Pat relies on Kim. /*Pat relies Kim. (Pat se fía de Kim.)
Los verbos de tener confianza como trust y rely (confiar y fiarse, en español) tienen estructuras de argumento similares pero muestran una selección diferente de categoría. Puesto que la selección de categoría se realiza en la lista de especificaciones SUBCAT, la descripción SUBCAT para confiar especifica que la categoría de su segundo complemento es un grupo nominal dentro de MAJ (núcleo–h MAJOR):
trust: SUBCAT <... SYNSEM|LOC|CAT|MAJ GN>
En el caso del verbo rely, SUBCAT no solamente especifica la categoría de su complemento como preposicional sino que también exige que la preposición sea on:
rely: SUBCAT <... SYNSEM|LOC|CAT [MAJ P, PFORM on]>
La subcategorización se basa también en ciertas características morfosintácticas, como la forma verbal, el caso, etc. Por ejemplo, algunos verbos como make y force seleccionan diferentes formas verbales, finita e infinitiva.
Pat made Kim throw up. /*Pat made Kim to throw up.
Pat forced Kim to throw up. /*Pat forced Kim throw up.
Esta realización se define también en COMPLS indicando la forma de inflexión requerida, mediante la característica VFORM, ver Figura 12 . La descripción del verbo force, difiere de la anterior en que en lugar de tener VP[base], tiene VP[inf].
Otra característica del núcleo-h como CASE se emplea para lograr una definición similar en lenguajes con inflexiones de caso, donde algunos verbos semánticamente próximos pueden requerir objetos en casos diferentes.
|
Figura 12. Descripción del verbo force
|
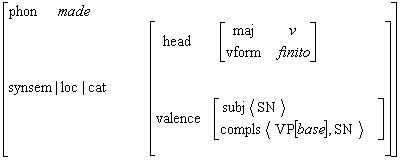
El Principio de Característica del h-núcleo, que filtra las características del h-núcleo de un nodo hija al nodo madre, establece que siempre que una forma léxica selecciona un complemento de frase especificado como SYN | LOC | HEAD | CASE ACC o como SYN | LOC | HEAD | CASE NOM, el h-núcleo léxico de ese complemento se especifica de la misma manera. Una situación análoga es el manejo de la preposición particular que rige una frase preposicional en lenguajes que carecen de inflexión de caso.
Otro punto importante considerado en la subcategorización es el manejo de preposiciones. HPSG enfatiza el hecho de que el empleo de preposiciones particulares no es predecible semánticamente. Por lo que diferentes verbos que requieren complementos realizados con frases preposicionales requieren valores diferentes para la característica del h-núcleo PFORM en ese complemento. Por ejemplo, los verbos destinar, emplear y usar asignan roles correspondientes a complementos introducidos con diferentes preposiciones.
El director destinó un millón de pesos a la biblioteca.
El director empleó un millón de pesos en la biblioteca.
El director usó un millón de pesos para la biblioteca.
Por último, en la HPSG se realiza un trabajo importante para describir los verbos de control y raising. Estos verbos tienen como complemento un grupo verbal y el sujeto de este grupo está identificado con un argumento del verbo. La diferencia entre estas construcciones se describe en las entradas léxicas.
· En los verbos equi todos los dependientes subcategorizados tienen asignado un rol semántico. Por ejemplo, un verbo equi como try subcategoriza un sujeto tipo grupo nominal y un complemento tipo grupo verbal.
· En los verbos raising un dependiente subcategorizado no tiene asignado un rol semántico. La identificación de dependiente no se hace compartiendo la estructura de índices sino compartiendo la estructura del synsem completo del dependiente.
Por ejemplo, el verbo try asigna el rol de “quien intenta” al sujeto, mediante el índice referencial correspondiente, y el valor CONTENT de su complemento VP al argumento psoa (parameterised state of affairs). El índice del sujeto también está en la estructura compartida con el sujeto del complemento de tipo VP, en la lista SUBCAT.
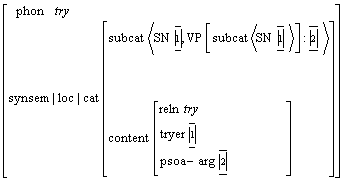
Una frase como John tries to run tendría la siguiente descripción, donde el rol del sujeto del verbo en infinitivo se indica en psoa del verbo try:
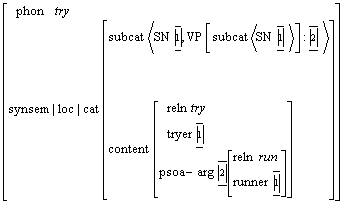
En el verbo tend, (ejemplo, John tends to run), que es un verbo raising, no se comparte la estructura del sujeto por lo que no está asignado a un papel en la matriz psoa. La lista SUBCAT de tend especifica que el synsem completo de su sujeto es la estructura compartida con el synsem de su complemento subcategorizado tipo grupo verbal.
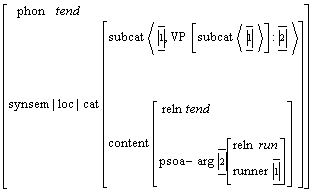
Valencias Sintácticas en DUG
En los árboles de dependencias cada nodo representa un segmento elemental (una categoría terminal) por lo que los nodos están típicamente marcados por lexemas. En la DUG, donde no se consideran etiquetas en los enlaces, se prefiere una representación en línea en lugar del árbol, así que por ejemplo la frase El niño pequeño atrapó una lagartija puede representarse en la siguiente forma:
[atrapar [niño [el] [pequeño] ] [lagartija [una] ] ]
Esta es una forma equivalente a una estructura jerárquica. En este tipo de representación, DUG a diferencia de otras gramáticas dependencias incluye las categorías de POS a las marcas de los nodos, por ejemplo:
[V atrapar [N niño [Det el] [ADJ pequeño] ] [N lagartija [Det una] ] ]
Donde Det significa determinante y ADJ adjetivo. En la misma forma y combinando categorías funcionales y morfosintácticas DUG introduce ambas categorías en la representación, por ejemplo:
[PRED atrapar V
[SUJ niño N [DET el Det] [ATR pequeño Adj] ]
[OBJD lagartija N [DET una Det] ] ]
Donde PRED es predicado, ATR es atributo, DET es determinante y OBJD es objeto directo. El orden de palabras, que es importante para el inglés, se describe en DUG mediante un marcaje adicional. Por el símbolo ‘<’ para denotar a la izquierda del h-núcleo y ‘>’ para denotar a la derecha del h-núcleo, de esta forma se describe que el sujeto está a la izquierda del verbo y el objeto directo a la derecha:
[PRED atrapar V
[< SUJ niño N [DET el Det] [ATR pequeño Adj] ]
[> OBJD lagartija N [DET una Det] ] ]
En la DUG se combina la noción de estructura de frase con la de dependencias ya que considera las dependencias como una relación de palabra a complemento, en lugar de una relación de palabra a palabra, donde un complemento puede consistir de muchas palabras. Es por esta razón que incluye las categorías gramaticales. Por ejemplo, el constituyente el niño pequeño es el sujeto del verbo atrapar en los ejemplos anteriores.
La DUG considera que internamente, cualquier frase se estructura de acuerdo a las relaciones de palabra a complemento y que se representa como tal. Por lo que aunque todos los nodos hoja en un árbol de dependencias corresponden a elementos terminales, en la DUG los nodos interiores pueden ser no-terminales. Sin embargo, una relación de dependencias solamente existe entre una palabra en el nodo dominador y las frases enteras representadas por el subárbol dependiente. Los nodos en el árbol de dependencias tienen las siguientes características:
· Hay un orden de secuencia entre los dependientes del mismo h-núcleo, igual que en la GPSG.
· Los nodos en el árbol representan unidades función-lexema-forma (función sintagmática, significado léxico, características morfosintácticas)
· Los nodos tienen etiquetas múltiples, por ejemplo, numero[singular], género[masculino], no pueden ser estructuras.
· Cada nodo hoja en el árbol corresponde a un terminal y cada subárbol corresponde a un no-terminal.
En [Hellwig, 83] se presenta la frase Arthur attends the Prague meeting. con la siguiente representación del analizador sintáctico:
(ILLOC: statement’: sign
(< PROPOS: attend present’: verb form[finite] person[he, U] s_type[statement] s_position[4,6,17] adjacent[left] margin[left]
(<SUBJECT: Arthur: noun person [he, C] determined [+, U] s_position[4])
(>DIR_OBJ1: meeting: noun person [it] determined [+, U] reference [definite, U] s_position[17] n_position[2,9,10]
(DETER: definit’: determiner determined [+, C] (reference [definite, C] n_position[2])
(<ATTR_NOM: Prague: noun determined [-] (n_position[9]))));
En la representación anterior, sin entrar en detalles, se muestra un árbol de dependencias con seis nodos, un nodo para cada palabra de la frase más el nodo raíz que corresponde a la oración. El punto origina el statement’ inicial, por lo que el nodo raíz corresponde a la oración, como en el enfoque de constituyentes. Cada nodo lleva tres tipos de información:
· Una función sintáctica, como sujeto SUBJECT, primer objeto DIR_OBJ1, determinante DETER, etc.
· Un lexema, como attend present’, Arthur, meeting, definit’, Prague)
· Un conjunto de características morfosintácticas; la primera característica es la categoría gramatical, como noun, determiner, etc.
El árbol de dependencias se construye a partir de la información contenida en tres diccionarios: un diccionario morfosintáctico, un conjunto de patrones de valencias y un diccionario de valencias.
El diccionario morfosintáctico relaciona cada forma de palabra a un lexema y a una categoría morfosintáctica compleja.
Los patrones de valencia contienen los fragmentos de un árbol de dependencia, generalmente correspondientes a un rector y un dependiente. Describen relaciones sintagmáticas específicas, entre el nodo del h-núcleo y su nodo dependiente (denominado ranura[24]), por ejemplo la relación entre un verbo y su sujeto. En estos patrones se describe la capacidad de combinación de las palabras, en las ranuras se acomodan los elementos de su contexto. Cada patrón caracteriza la forma morfosintáctica del h-núcleo, la función sintáctica del dependiente y la forma morfosintáctica del dependiente. También las selecciones léxicas pueden especificarse en una ranura cuando se requiere.
El diccionario de valencias consiste de referencias. Una referencia asigna un patrón o un conjunto de patrones al elemento léxico, de esta forma se implementa la subcategorización, que describe la capacidad de combinación del elemento. Existen tres tipos de referencias de acuerdo a las posibles funciones de los patrones: complementos, adjuntos y conjunciones.
Para el ejemplo anterior, de [Hellwig, 98], se tienen los siguientes patrones:
(ILLOC: +statement: sign
(<PROPOS :=: verb form[finite] s_type[statement] adjacent [left] margin[left]));
(*:+subject: verb form[finite, subjunctive] s_type[statement, relative] s_position[6]
(<SUBJECT:=: noun person[C] determined[+] s_position[4] ));
(*:+dir_obj1:verb obj_number[singular] mood[active] s_position[6]
(>DIR_OBJ1:=: noun person [I, you, he, she, it] determined[+] s_position[17] ));
(*: %dete_count_any: noun count[+] n_position[10]
(<DETER: _ : determiner determined[C] reference[C] n_position[2] ));
(*: %attr_nominal: noun n_position[10]
(<ATTR_NOM: _ : noun determined[-] punct2[hyphen] n_position[9] ));
Las referencias que se emplearon para enlazar los elementos léxicos en la frase del ejemplo con los patrones anteriores son las siguientes:
(:COMPLEMENTS (*:statement': sign) (: +statement));
(:COMPLEMENTS (*:attend: verb) (&(: +subject) (:+dir_obj1)));
(:ADJUNCT (*:definite: determiner) (: %dete_count_any));
(:ADJUNCT (*: Prague: noun) (: %attr_nominal));
En la DUG se separan completamente los complementos y los adjuntos. Los complementos son dependientes de un elemento léxico y son requeridos por la semántica combinatoria inherente de la palabra. Los adjuntos son circunstanciales, por ejemplo los adverbios. Mientras que un término esta incompleto hasta que ha encontrado sus complementos, los adjuntos pueden agregarse al conjunto de dependientes de un término en una forma relativamente arbitraria. Mientras los complementos se especifican en el diccionario bajo el lema del término rector, es decir, en forma descendente, los patrones adjuntos se especifican en la entrada léxica de la palabra adjunta, definiendo el potencial del enlace del elemento léxico como un dependiente, es decir, en una forma ascendente.
Para describir las alternaciones sintácticas del verbo se aceptan más de un patrón con el mismo nombre. Por ejemplo, entre los patrones de sujeto están los siguientes, que describen los sujetos en oraciones interrogativas:
(*:+subject: verb auxiliary[+] form[finite, subjunctive] s_type[question] s_position[6]
(>SUBJECT:=: noun person[C] determined[+] s_position[7]));
(*:+subject: verb forma[finite, subjunctive] s_type[question, relative] s_position[6]
(<SUBJECT:=: pronoun pro_form[interrogative, relative[C] person[C] gender[C] case[subjective] n_position[2]));
El primer patrón del sujeto describe el sujeto de Did Arthur attend the meeting? y el segundo patrón considera la frase Who did attend the meeting?. Ambos patrones están ya cubiertos por la referencia para attend en las referencias anteriores.
En la DUG, las estructuras de control y extraposición se manejan por asignación de patrones específicos a los verbos que dan origen a estas estructuras. DUG describe la estructura de argumento como un nivel de descripción sintáctica. No hay un orden de roles participantes, por lo que el sujeto se considera como un argumento más del verbo.
Valencias Sintácticas en la MTT
En los árboles de dependencias de la MTT [Mel’cuk, 79], los arcos entre los nodos están etiquetados con relaciones sintácticas de superficie. Estas relaciones son dependientes del lenguaje y describen construcciones sintácticas particulares de lenguajes específicos. Entre estas relaciones, existen unas cuantas donde el dependiente se denomina actuante sintáctico de superficie.
Los actuantes sintácticos de superficie de un verbo representan lo que en otros formalismos se conocen como los objetos sintácticos, es decir, su sujeto, sus objetos y sus complementos pero únicamente relacionados al sentido inherente del lexema. Los actuantes corresponderían a los “complementos” de la DUG ya que contrastan con los circunstanciales (o adjuntos en la DUG). La línea divisoria entre ellos se marca de acuerdo a diversos criterios que se expondrán en otras secciones.
La construcción de la estructura sintáctica de superficie se realiza mediante tres tipos de reglas: 1) las reglas que transforman una relación sintáctica profunda en una relación sintáctica de superficie y viceversa, 2) las reglas que transforman una relación sintáctica de superficie en un nodo de la sintaxis profunda y viceversa, y 3) las reglas que transforman una relación sintáctica profunda en un nodo de la sintaxis de superficie y viceversa. En [Mel’cuk, 88] se presentan estas reglas con ejemplos para el inglés y el ruso.
En el primer tipo se expresan las relaciones sintácticas profundas mediante una relación sintáctica de superficie, por ejemplo, las predicativas, posesivas, modificativas, cuantitativas, etc. En el segundo tipo un lexema profundo ficticio se expresa mediante una relación sintáctica de superficie, por ejemplo, la aproximativa-cuantitativa en el ruso. En el tercer tipo, una relación sintáctica profunda se expresa mediante una palabra función, por ejemplo, las preposicionales.
En [Mel’cuk, 88] se presenta el diagrama completo de la representación sintáctica de superficie para la frase en ruso, que corresponde a la traducción en inglés: “According to reports by the press of the USA, the White House has the opinion that the American people should obligatorily give to the countries of Africa its most energetic support concerning the development of their economy” (ver Figura 13).
En la MTT, las valencias sintácticas de los verbos, principalmente, de los sustantivos, y de los adjetivos se describen conforme a lo que se denomina Zona Sintáctica [Steele, 90], con la ayuda de una tabla de Patrones de Manejo sintáctico (PM). La descripción en esta zona corresponde al nivel de la representación sintáctica de superficie de la MTT, a la estructura sintáctica de superficie.
Existen otras tres estructuras en este nivel (la estructura comunicativa, la estructura anafórica y la estructura prosódica) que están más relacionadas con la representación sintáctica profunda. En la Figura 13 se observan la estructura comunicativa, el tema y el rema. Con línea punteada se marcan la correferencias, correspondientes a la estructura anafórica; en este caso la prosodia se considera neutral. Las líneas completas marcan la estructura sintáctica de superficie.
En la tabla de PM de la zona sintáctica, que expresa la diatesis, se presenta la siguiente información:
· Correspondencia entre las valencias semánticas y sintácticas de la palabra encabezado.
· Todas las formas en que se realizan las valencias sintácticas.
· La indicación de obligatoriedad de la presencia de cada actuante, si es necesario.
|
Figura 13. Ejemplo de una representación sintáctica superficial.
|
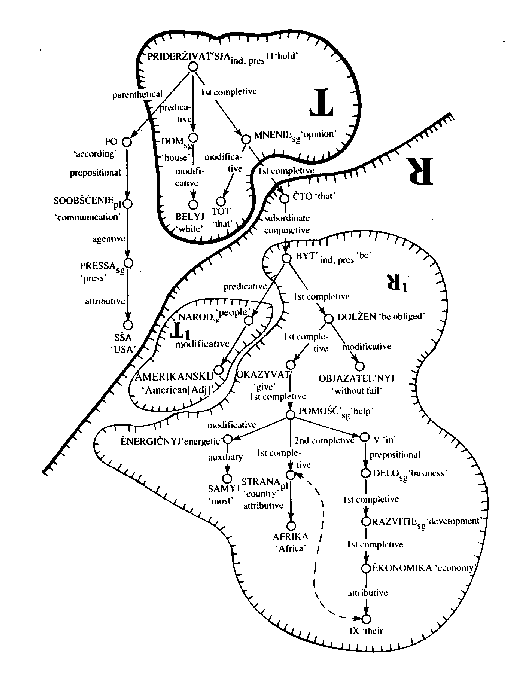
Así que cada PM es una colección completa de descripciones de todos los posibles objetos de una palabra específica (verbo, sustantivo o adjetivo), sin considerar su orden en la oración.
Después de la tabla de PM, en la zona sintáctica, se presentan dos secciones: restricciones y ejemplos. Las restricciones consideradas en los PMs son de varios tipos: semánticas, sintácticas o morfológicas; entre estas restricciones también se considera la compatibilidad entre valencias sintácticas. La sección de ejemplos cubre todas las posibilidades: ejemplos para cada actuante, ejemplos de todas las posibles combinaciones de actuantes y finalmente los ejemplos de combinaciones imposibles o indeseables, es decir, los órdenes permitidos y prohibidos de estas diferentes palabras manejadas.
La parte principal de la tabla de PM es la lista de valencias sintácticas de la palabra encabezado. Se listan de una manera arbitraria pero se prefiere el orden de incremento en la oblicuidad: sujeto, objeto directo, objeto indirecto, etc. Cada encabezado usualmente impone cierto orden; por ejemplo, una entidad activa (sujeto) toma el primer lugar, después el objeto principal de la acción, después otro complemento (si existe), etc. También la forma de
expresión del significado de la palabra encabezado influye en el orden.Esta expresión precede cada PM.
Otra información obligatoria en cada valencia sintáctica es la lista de todas las posibles formas de expresión de la valencia en los textos. El orden de opciones para una valencia dada es arbitrario, pero las opciones más frecuentes aparecen normalmente primero. Las opciones se expresan con símbolos de categorías gramaticales o palabras específicas.
[Steele, 90] presenta el vocablo teach, como una entrada del Diccionario explicativo combinatorial del inglés, ejemplos para el francés se presentan en [Mel’cuk et al, 84, 88]. Para el vocablo teach, presenta ocho descripciones, de entre ellas presentamos tres a continuación:
I.1 X, having knowledge of, or skills in, Y, causes Z intentionally and methodically to learn 1 Y [Mr. Brown taught his students History]
I.2a X makes a statement Y, that forms part of a doctrine Y2, espoused by X in order that Z may learn 1 the contents of Y [Socrates taught that wisdom is desirable
I.2b X contains a statement Y1, which is part of a doctrine Y2, expounded in X for the information of Z [The Bible teaches us that we should love our neighbors]
Cada una de estas descripciones presenta un sentido atribuido al lexema. Cada sentido tiene una forma de realizar sintácticamente sus valencias. La descripción de la zona sintáctica del sentido I.2a se presenta en el siguiente cuadro, terminando con un ejemplo.
De lo anterior se desprende que las descripciones propuestas están dirigidas al ser humano. Las entradas del diccionario combinatorio son exhaustivas, indicando todos los posibles sentidos atribuidos al vocablo y con las realizaciones sintácticas de las valencias. Las posibles combinaciones se muestran con ejemplos muy completos.
|
I.2a. X teaches Y to Z = X makes a statement Y1 that forms part of a doctrine Y2, espoused by X in order that Z may learn 1 the contents of Y.
1) C2.2 without C3.1 : impossible. C1 + C2 : The philosopher taught purity and selfcontainment; Jesus Christ taught his followers to love one another; Lenin taught that left-wing communism is an infantile disorder. C1 + C2 + C3 : The order taught chastuty to its members; The army taught every soldier to keep his powder dry; Socrates taught people that wisdom is the highest good. Impossible : *He taught to be courageous (1) [=he taught them to be courageous].
Examples According to George Bernard Shaw, many Anglican clergymen do not hesitate to teach that all Methodists incur damnation. The Party taught self-reliance and self-criticism.
|
Definiciones lexicográficas
Las palabras de cada lenguaje natural se dividen en autónomas y auxiliares. Existen unos diccionarios especiales que explican el sentido de cada palabra autónoma. Se llaman diccionarios de la lengua, o de explicaciones y se dirigen a seres humanos. El rasgo muy importante de la MTM es que el diccionario computacional se propone como la estructura que contiene las explicaciones (definiciones lexicográficas) para palabras autónomas, y estas definiciones sirven como el medio para las transformaciones en el nivel semántico, así como para establecer las correspondencias entre las valencias semánticas y sintácticas. En la forma inicial, las definiciones se representan como una oración o un conjunto de oraciones en lenguaje natural. Los rasgos muy importantes de las definiciones son:
· Las palabras usadas se libran de toda ambigüedad, es decir son de un solo significado. Puesto que las palabras comunes de cada lenguaje tienen frecuentemente homónimos, se hace la selección y las marcas especiales.
· El sentido de muchas palabras, especialmente de verbos y sustantivos verbales, no puede definirse sin mencionar unas entidades las cuales hay que precisar en la situación específica. Estas entidades sirven como los papeles en las acciones que son reflejadas por los verbos correspondientes. Son justamente las valencias semánticas del verbo. En las definiciones lexicográficas, las valencias se representan como variables en las formulas algebraicas por letras X, Y, Z, W....
· Debemos explicar el sentido de la palabra por sentidos de otras palabras que son más “simples” que la palabra bajo definición. No tenemos lugar para explicar cual es esta simplicidad, sólo hacemos notar que el conjunto de todas las definiciones no debe contener círculos viciosos y conducir a unos sentidos elementales.
Ejemplos de definiciones
Las definiciones de clasificación son bastante comunes en los diccionarios de explicación orientados a los seres humanos. En primer lugar dan una noción de cual es el género semántico (= superclase) para la noción bajo definición y además añaden tales propiedades específicas de esta especie (= subclase) que le distinguen de otras especies dentro de la misma clase.
Por ejemplo, la definición para blueberry (arándano en castellano) de dice:
blueberry es una baya comible de color azul o negruzco
Entonces podemos representar esta fórmula de lenguaje natural con la fórmula lógica usando predicados ES_SUBCLASE(), AZUL(), NEGRUZCO() y COMIBLE ():
ES_SUBCLASE(blueberry, baya) & COMIBLE(blueberry) & (AZUL(blueberry) Ú NEGRUSCO(blueberry))
A su vez el predicado COMIBLE puede expresarsecon COMER() e INSALUBRE() que se consideran más simples:
COMIBLE(y) º ~$persona INSALUBRE (COMER (persona, y), persona))
(Es comible y = No existe persona para la cual es insalubre comer y)
Las definiciones de unos predicados por otros son también bastante comunes. Si definimos soltero en la forma libre como
Soltero es un hombre adulto para quien no existe mujer con la cual él es casado
podemos expresar el predicado SOLTERO()tras los predicados SEXO(), ADULTO() y CASADO():
SOLTERO(x) º SEXO(x, masculino) & ADULTO(x) &
~$y (SEXO(y, femenino) & CASADO(x, y))
Ahora conocemos el método de convertir las formulas libres de las definiciones a las fórmulas lógicas correspondientes. Pero el problema de seleccionar las palabras sin homónimos y círculos viciosos en las fórmulas libres queda bastante complejo. Al mismo tiempo palabras de lenguajes extranjeros parecen más exentas de homonimia. Es por que preferimos las definiciones en inglés para la descripción de sentidos.
Métodos lexicográficos tradicionales de compilación de diccionarios
La lexicografía es una rama de la lingüística aplicada que trata con el diseño y la construcción de bases de datos léxicas (diccionarios, enciclopedias) para el uso práctico de los seres humanos y de sistemas tecnológicos. También trata con su adecuación a cometidos generales o específicos y con el acopio de los recursos teóricos necesarios para alcanzar estos fines.
Los métodos lexicográficos difieren dependiendo de los objetivos y las fuentes de información. Por ejemplo, un diccionario clásico puede tener las siguientes características de representación durante el proceso de desarrollo lexicográfico: 1) un formalismo de estructuras de campos como bases de datos para entradas léxicas, con referencias cruzadas a otros campos, 2) un número de notaciones, para diferentes campos, o para léxico diferente basado en la misma base de datos lexicográfica, y 3) varias implementaciones (como bases de datos). Pero para construir un diccionario clásico en base a un corpus de textos, se requieren varios pasos adicionales[Gibbon, 99]:
1. Adaptación de conjuntos de caracteres, de estructuras de registros, etc. a los requerimientos del marco de trabajo del lexicógrafo.
2. Identificación de las unidades estructurales más pequeñas del texto de entrada, palabras, y resolución de elementos codificados (datos, abreviaturas, etc.)
3. Identificación de las formas de palabra completamente flexionadas que aparecen en el contexto del corpus, que servirá de fuente de información.
4. Especificación de la microestructura: definición de la estructura de los atributos, de la estructura del registro de la base de datos, etc. para los tipos de información léxica que se requiere.
5. Extracción de información:
(a) análisis estadístico, en sus diferentes variantes (frecuencia de las palabras, frecuencia de pares de palabras, frecuencia de colocaciones, estimación de la probabilidad como información de la microestructura, etc.)
(b) análisis lingüístico, es decir, lematización (extracción de palabras encabezado), información fonológica, ortográfica, morfológica, sintáctica, semántica y pragmática de microestructura.
En la construcción de diccionarios computacionales, los investigadores hacen énfasis en la distinción de entradas mediante el sentido. Los principios para identificar un sentido en lexicografía según [Meyer et al, 90] y [Mel'cuk, 88a], son los siguientes:
1. Si para una unidad léxica sugerida, pueden aplicar dos posibles mapeos a la ontología[25], entonces se deben crear dos unidades léxicas (es decir, crear dos sentidos si se desea tener significados diferentes apuntando a diferentes partes de una jerarquía de tipos).2. Si hay restricciones elegibles incompatibles para una unidad léxica sugerida, debe haber dos sentidos.
3. Si hay dos conjuntos incompatibles de co-ocurrencia (morfológicos, sintácticos como marcos de subcategorización, o léxicos como colocaciones), se deben crear dos sentidos.
4. Si hay dos posibles lecturas de una palabra, se deben crear dos sentidos.
La creación de entradas en el diccionario ha sido una tarea manual cuyo trabajo requiere expertos. [Mel’cuk, 88a] establece criterios para distinguir sentidos, criterios que están dirigidos a los humanos. Para él, un vocablo es el conjunto de todas las unidades léxicas (sentidos) para el cuál las definiciones lexicográficas están ligadas con un puente semántico. Un puente semántico entre dos unidades léxicas es una componente común a sus definiciones, que formalmente expresa un enlace semántico. Una unidad léxica básica de un vocablo es una unidad léxica que tiene un puente semántico con la mayoría de las otras unidades léxicas del vocablo.
Un campo semántico es el conjunto de todas las unidades léxicas que comparten una componente semántica no trivial explícitamente distinguida. Un campo léxico es el conjunto de todos los vocablos cuyas unidades léxicas básicas pertenecen al mismo campo semántico. Aunque Mel’cuk usa un vocablo para agrupar sentidos similares bajo una superentrada, cualquier entrada principal puede tener cualquier número de grupos de sentidos bajo ella.
Mel’cuk articula el principio de descomposición donde la definición de una unidad léxica debe contener solamente términos que son semánticamente más simples que la unidad léxica. Más aún, a través de su principio de puente semántico, las definiciones de cualesquiera dos unidades léxicas del mismo vocablo deben enlazarse explícitamente, ya sea por un puente semántico o por una secuencia de puentes semánticos.
Estos principios deben seguirse en la construcción de un diccionario y asegurar su consistencia interna. Más importante aún es que estos principios deben aplicarse para determinar la relación entre una definición y el resto del diccionario, incluyendo otras definiciones de la misma entrada principal. Mel’cuk hace seis observaciones pertinentes para agrupar y ordenar los sentidos de una entrada:
1. El agrupamiento en un vocablo polisémico tiene una motivación semántica, es decir, que todos los lexemas deben compartir al menos un componente semántico importante.
2. La división en grupos de sentidos está basada semánticamente.
3. El ordenamiento se basa en proximidad semántica.
4. El ordenamiento se basa en cuál entrada es semánticamente más simple.
5. Un sentido intransitivo se sitúa antes de un sentido transitivo, de nuevo basado en simplicidad semántica (el transitivo se define en términos del intransitivo).
[Litkowski, 92] considera como principios lexicográficos para organizar un diccionario computacional, los siguientes: las entradas principales y palabras encabezado, el agrupamiento y el orden de sentidos, y por último las seudoentradas. Las entradas principales y palabras encabezado, se refiere a que las unidades léxicas en un diccionario generalmente tienen la intención de asegurar la lexicalización del significado, uniendo grupos y configuraciones de elementos semánticos en unidades léxicas reales y proveyendo información sintáctica y léxica de ocurrencia concurrente. Pueden existir varias entradas correspondientes a homónimos.
El agrupamiento y el orden de sentidos se refiere a que la creación de sentidos para un diccionario computacional tiene consecuencias importantes para el compromiso del análisis sintáctico que se implemente. En diccionarios para sistemas amplios, mientras más información se tenga en el diccionario, la estructura de una entrada supone mayor importancia, particularmente la manera en la cuál los sentidos se relacionan uno a otro.
Las seudoentradas se refieren a que se codifica otro grupo distinto de entrada léxica para caracterizar generalidades lingüísticas y léxicas. Las seudoentradas codifican solamente abstracciones semánticas o gramaticales, constituyen entradas metalingüísticas en el diccionario. Las seudoentradas varían en importancia con la teoría gramatical.
[Ilson & Mel’cuk, 89] discuten varios problemas léxico-gramáticales: las cuasi-pasivas, las variaciones sintácticas y los complementos objeto y sujeto. Las cuasi pasivas no son posibles en todos los verbos, son lexemas separados de sus formas activas, mientras que las pasivas reales son formas gramaticales del mismo lexema. Por lo que discuten que las pasivas reales no se deben describir como entradas separadas en las entradas propias del diccionario.
La variación sintáctica se refiere a que puede haber dos patrones de manejo que tengan el mismo significado para un solo sentido de un verbo. Por lo que discuten que solamente es necesario un sentido en el diccionario. En los complementos sujeto/objeto, algunos son obligatorios y deben incluirse entre los argumentos de los verbos correspondientes, mientras que otros son opcionales y añadidos libremente. Así que arguyen que el reconocimiento debe tratarse en la gramática y no como resultado de diferentes entradas.
En todos estos casos, cierta información puede situarse en el diccionario. Tal vez la clave para hacer distinciones sea la eficiencia en el procesamiento, por ejemplo, situar información en el diccionario si puede accesarse y usarse más eficientemente que el retroceso a través de varias trayectorias en un analizador sintáctico. Con el desarrollo de reglas léxicas, reglas derivacionales, y funciones de colocación que pueden situarse en el diccionario mismo, es difícil determinar exactamente dónde abandonar la creación de entradas del diccionario, es decir, en qué momento detener las definiciones lexicográficas.
Revisión de los enfoques diversos para la descripción de valencias sintácticas
En todos los formalismos descritos, las valencias sintácticas involucran tanto la estructura de los distintos argumentos como la función gramatical de cada uno de ellos. El número de argumentos y la descripción de la función gramatical que cada uno de los formalismos considera difiere, así como el nivel en que se representan.
La estructura de argumentos, es decir, los predicados y los argumentos asociados con los participantes, se define en el nivel sintáctico en la GB, en la GPSG, en la LFG, en la DUG, y en la MTT; en cambio en la HPSG y en la CG forma parte de la representación semántica de predicados.
Los participantes de la acción en todos los formalismos con la excepción de la HPSG, la DUG y la MTT se marcan con roles temáticos que no están motivados totalmente de manera semántica. En la HPSG, la DUG y la MTT se marcan los participantes específicos del significado de cada verbo o palabra de que se trate. Se hace clasificación de roles temáticos en la GB (externos e internos), en la LFG (una jerarquía temática universal) y en la CG (roles prototípicos de Dowty, aumentados). Esta clasificación determina la funcionalidad sintáctica de los participantes.
Por la importancia de la selección semántica en la subcategorización, formalismos como la GB o la LFG que no incluyen un nivel de representación semántica proveen un nivel de descripción lingüística que expresa la estructura semántica de los objetos de los predicados en términos sintácticos.
Mientras en la DUG y en la MTT los objetos sintácticos se expresan léxicamente y se ven como primitivas; en los demás formalismos, los objetos sintácticos se ven como enlaces entre constituyentes seleccionados sintácticamente y los roles semánticos. A excepción de la GB que sitúa esta información en la estructura sintáctica, los demás formalismos la colocan en el diccionario.
La especificación de los objetos sintácticos se hace en la GB como relaciones de predicación y rección; en la LFG la especificación se hace mediante los principios de mapeo léxico, que rige el enlace de roles-q a las características de las funciones gramaticales primitivas en formas léxicas. En la HPSG y la CG los argumentos se clasifican sintácticamente de acuerdo a la jerarquía oblicua. En la MTT y en la DUG no se define una jerarquía, y aunque se puede emplear el orden en la oblicuidad, existen otros factores a considerar, como el orden de los actuantes en el sentido del lexema.
De entre estos formalismos solamente la LFG y la MTT consideran la estructura de información o comunicativa, en la primera con el foco y tópico, y en la segunda con el tema y el rema. La estructura de información ha sido un problema en el enfoque de constituyentes, porque a menudo las unidades de información no coinciden con las unidades establecidas por la estructura de frase.
En esta sección presentamos los métodos estadísticos requeridos para reconocer modelos del lenguaje. Estos modelos permiten explicar fenómenos del lenguaje para sistemas computacionales. Por lo que mediante estos métodos estadísticos se detectan regularidades de los lenguajes.
Para emplear métodos estadísticos en el reconocimiento de secuencias de letras y palabras en los lenguajes naturales es necesario primero conocer el concepto de información. [Weaver, 49] estableció que la palabra información en la teoría de comunicación se relaciona no tanto con lo que se dice sino con lo que se puede decir. La información es una medida de la libertad de selección cuando se escoge un mensaje. El concepto de información se aplica no sólo a mensajes individuales, como sería el concepto de sentido, sino a la situación como un todo.
Para aclarar esta situación, un ejemplo es el caso donde el contenido del mensaje depende de echar al aire una moneda. Si el resultado es águila, el mensaje entero consistirá de una palabra, de lo contrario el mensaje consistirá del texto entero de un libro. En este ejemplo, para la teoría de la información lo único importante es que hay dos salidas equiprobables, y no tiene que ver con que el contenido semántico del libro sea mayor que el de una sola palabra. La teoría de la información se interesa en la situación antes de la recepción del símbolo, más que en el símbolo mismo. Por ejemplo, la información es muy baja después de encontrar la letra q (en textos en español) puesto que hay una mínima libertad de elección en lo que viene después, porque casi siempre es una u.
La cantidad empleada para medir la información es la entropía, exactamente el término conocido en termodinámica (H)[26]. Si una situación está totalmente organizada, es decir, no está caracterizada por un alto grado de aleatoridad o elección, la información o entropía es baja.
La unidad básica de información es el bit. El bit se define como la cantidad de información contenida en la elección de uno de dos símbolos equiprobables como 0 ó 1, si o no. Cada mensaje generado a partir de un alfabeto de n símbolos o caracteres puede codificarse en una secuencia binaria. Cada símbolo de un alfabeto de n-símbolos contiene log2 (n) bits de información, puesto que es el número de dígitos binarios requeridos para transmitir cada símbolo. Por ejemplo para cada uno de los 33 caracteres en el alfabeto para el lenguaje español (a, b, c, …, ñ, …z, á, é, í, ó, ú, ü), se requieren log2 (33) = 5.044 bits.
La entropía está relacionada con la probabilidad. Por ejemplo, cuando se ha empezado a transmitir un mensaje que empieza con las palabras “se diría”. La probabilidad de que la siguiente palabra sea que es muy alta, mientras que la probabilidad de que la siguiente palabra sea perico es muy baja. La entropía es baja en las situaciones donde las probabilidades son muy desiguales y mayor cuando las probabilidades de varias elecciones son iguales. La relación exacta entre entropía y probabilidades inherentes en un sistema está dada por la siguiente fórmula:
![]()
El signo menos hace que H sea positiva, puesto que los logaritmos de fracciones son negativos. Para calcular la entropía de un lenguaje natural se debe:
· Contar cuantas veces aparece cada letra del alfabeto.
· Encontrar la probabilidad de ocurrencia de cada letra al dividir su frecuencia por el número total de letras en el texto.
· Multiplicar cada probabilidad de letra por su logaritmo base dos.
· Cambiar el signo menos por uno más.
Por ejemplo, la entropía de caracteres de la palabra lata se calcula como sigue: l ocurre una vez, a ocurre dos veces y t ocurre una vez. Este minúsculo texto consiste de cuatro letras, la probabilidad de ocurrencia de l es 0.25, la de a de 0.5 y la de t es de 0.25, la probabilidad de todas las otras letras es cero porque no aparecen en el texto. Cuando se multiplica cada probabilidad de letra por su logaritmo de base dos, para l se obtiene 0.25 ´ log2 (0.25) = 0.25 ´-2 = -0.5, para a se obtiene 0.5 ´-2 = -1.0 y para t se obtiene -0.5 . Sumando estos valores y cambiando el signo se obtiene el valor de entropía final de 1.5
[Kahn, 66] escribió que el lenguaje con la entropía máxima posible sería aquél sin reglas que lo limitaran. El texto resultante sería completamente aleatorio, teniendo todas las letras la misma frecuencia y cualquier caracter igualmente probable de seguir a cualquier otro caracter.
Sin embargo, las reglas de cualquier lenguaje natural le imponen una estructura y por lo tanto una baja entropía. La fórmula anterior da el grado de entropía de acuerdo a la frecuencia de caracteres solos en el lenguaje, sin tomar en cuenta que la probabilidad de encontrar una letra también depende de la identidad de sus vecinas. Se pueden hacer mejores aproximaciones a la entropía de un lenguaje natural repitiendo el cálculo anterior para cada par de letras (bigram) como ac, ad, etc. después dividiendo entre dos porque la entropía se especifica en una base por letra. Una mejor aproximación aún se produce al realizar el cálculo anterior para cada tres letras (trigram) como adm, con, etc. y después dividiendo entre tres.
El proceso de aproximaciones sucesivas a la entropía puede repetirse incrementando cada vez la longitud del grupo de letras hasta encontrar las secuencias más largas de caracteres (n-grams) las cuales ya no tienen una probabilidad válida de ocurrencia en textos. Mientras más pasos se tomen, más precisa será la estimación final de entropía, puesto que cada paso da una aproximación más cercana a la entropía del lenguaje como un todo.
Tomando un alfabeto de 27 letras (26 letras y un caracter espacio), [Shannon, 49] encontró que la entropía del inglés fue de 4.03 bits para una letra, de 3.32 bits por letra en bigrams, y de 3.1 bits por letra en trigrams. La razón de esta disminución es que cada letra influye a la que sigue, es decir, imponen un orden. En base a esto Shannon estableció que cualquiera que hable un lenguaje posee implícitamente un enorme conocimiento de las estadísticas de un lenguaje. Desafortunadamente ese conocimiento es vago e impreciso, por lo que se requieren modelos lingüísticos.
[Edmundson, 63] definió el término modelo lingüístico como una representación abstracta de un fenómeno del lenguaje natural. Estos modelos requieren datos cuantitativos así que necesariamente tienen que basarse en corpus. Los modelos lingüísticos pueden ser predictivos o explicativos. Los modelos predictivos expresan la explicación de comportamiento futuro. Los modelos explicativos existen para explicar fenómenos ya observados. Algunos modelos se emplean tanto como modelos predictivos como explicativos, por ejemplo el modelo de Markov.
Un modelo del lenguaje siempre es una aproximación al lenguaje real. Ejemplos de modelos estadísticos del lenguaje son: las predicciones estocásticas de secuencias y los rangos de distribución de frecuencias. El término proceso estocástico fue definido por [Shannon, 49] como un sistema físico, o un modelo matemático de un sistema, que produce una secuencia de símbolos gobernados por un conjunto de probabilidades.
Los modelos lingüísticos basados en estadísticas son necesarios para considerar la variedad de observaciones lingüísticas y comportamiento cognitivo inherente en la producción de patrones de secuencias de palabras en el lenguaje. Ejemplos de modelos estadísticos del lenguaje son los de [Markov, 16], predicción estocástica de secuencias, el de [Shannon, 49], redundancia del inglés, y el de [Zipf, 35], distribución de rangos de frecuencias.
En esta sección presentamos la distribución de rangos de frecuencias, la predicción estadística de secuencias, y la reestimación.
Distribución de rangos de frecuencias
Entre los modelos predictivos, la ley de Zipf trata de explicar el comportamiento futuro. De acuerdo a la distribución Zipf [Zipf, 49], una variable aleatoria tiene una distribución Zipf si la probabilidad de su función masa esta dada por la siguiente fórmula para algún valor de a>0.
![]()
Puesto que la sumatoria de las probabilidades anteriores debe ser igual a 1, entonces:
La ley de Zipf dice que para la mayoría de los países, la distribución del tamaño de las ciudades se ajusta impresionantemente a una ley poderosa: el número de ciudades con poblaciones mayores que S es proporcional a 1/S. Suponiendo que, al menos en la última parte, todas las ciudades siguen algún proceso de crecimiento proporcional (esto parece verificarse empíricamente). Esto lleva su distribución, automáticamente, a converger a la ley de Zipf.
De acuerdo a la ley de Zipf, el rango de una palabra en una lista de frecuencias de palabras, ordenada por frecuencias de aparición en forma descendente, está relacionada inversamente a su frecuencia. Se puede predecir la frecuencia de una palabra a partir de su rango usando la fórmula:
![]()
La ley de Zipf es una observación empírica de que en muchos dominios, el rango de un elemento dividido por la frecuencia de ocurrencia de ese elemento es constante. Por ejemplo, si las poblaciones de ciudades obedecen la ley Zipf, significaría que si la más populosa tiene una población n, entonces la segunda ciudad más grande tiene n/2 y la tercera n/3, etc. Zipf observó que esta ley se aplica en muchas áreas diversas, incluyendo frecuencias de palabras en textos, escritas en diversos lenguajes. Publicaciones posteriores demostraron que la ley de Zipf es una consecuencia de asumir que la fuente del lenguaje del cuál se toman los datos de frecuencia es un proceso estocástico simple.
De la fórmula de frecuencia observamos una interdependencia lineal entre frecuencia y rango. Esa fórmula no puede extrapolarse al infinito, puesto que su normalización es imposible. Para los primeros rangos, el cálculo probabilístico directo puede realizarse pero para rangos muy grandes la situación es muy diferente. En cualquier conjunto de frecuencias empíricas, cerca de la mitad de todos los rangos corresponde a los casos de una ocurrencia de los objetos bajo observación. Por lo que objetos con valores grandes de rango no pueden ordenarse apropiadamente, tampoco calcularse con precisión.
La ley de Zipf's nos dice que tendremos dificultad delineando cualquier conclusión basada en la observación de la distribución de la mayoría de los elementos del tipo que nos interesa (frase, palabra, etc.). Además de indicarnos que muchos elementos ocurrirán con una frecuencia muy baja, podemos deducir que habrá un gran número de elementos disponibles pero que no ocurren en el corpus de textos. Para nuestra investigación, donde no podemos “alisar” los datos, simplemente nos indica que se requiere incorporar información sobre ellos.
Para tener buenos resultados deberíamos incrementar el tamaño de los datos hasta un límite, mucho mayor que el valor del rango, pero este requisito nos lleva a una labor muy larga de extracción y acumulación de datos, es decir, a una tarea que consume una cantidad impresionante de trabajo.
La distribución de palabras, en varios lenguajes naturales, sigue la ley de Zipf [Baayen, 92], pero la distribución de caracteres concuerda menos. [Shtrikman, 94] muestra que esta diferencia es menos pronunciada en el chino porque muchos caracteres son realmente palabras completas.
Predicción estadística de secuencias aleatorias de palabras
En esta sección presentamos métodos probabilísticos que consideran no un evento aislado sino eventos dependientes, es decir de probabilidades condicionales. La probabilidad condicional de la salida de un evento se basa en la salida de un segundo evento.
Modelo de Markov
Entre los ejemplos que Shannon dió como procesos estocásticos están los lenguajes naturales escritos. Shannon hizo una serie de experimentos para generar un texto, considerando desde el más simple, donde los símbolos son independientes y equiprobables, denominado aproximación de orden cero, hasta el de estructuras de trigram para el inglés. El parecido a un texto usual en inglés aumenta en cada uno de los pasos. En el caso de primer orden, la selección depende solamente de la letra precedente, nada más. La estructura estadística se puede describir por un conjunto de probabilidades de transición Pi(j), la probabilidad de que la letra i sea seguida de la letra j. Una forma equivalente de especificar esta estructura es con las probabilidades de bigrams o de la secuencia de dos caracteres P(i, j), la frecuencia relativa del bigram i,j.
El siguiente paso en complejidad involucra frecuencias trigram. Para esto se requiere un conjunto de frecuencias trigram P(i, j, k) o probabilidades de transición Pij(k). Por ejemplo, los trigram encontrados por [Pratt, 42] para el inglés son: THE, ING, ENT, ION. Arriba de este nivel, se topa uno con la ley de regresos disminuidos y muy grandes, matrices de transición muy poco densas.
Los procesos estocásticos del tipo descrito se conocen como procesos discretos de Markov. La teoría de estos procesos fue desarrollada por [Markov, 16]. En un modelo de Markov, cada estado exitoso depende solamente del estado presente, así que una cadena de Markov es la primera generalización posible, alejada de una secuencia independiente de experimentos. Un proceso complejo de Markov es uno donde la dependencia entre estados se extiende más adelante, a una cadena precedente al estado actual. Por ejemplo, cada estado exitoso puede depender de los dos estados previos. Una fuente de Markov para la cual la selección del estado depende de los n estados precedentes da una aproximación de orden (n+1)-iésimo al lenguaje del cual las probabilidades de transición fueron delineadas y se denota como un modelo de Markov de orden n-iésimo. Si cada estado exitoso depende de los dos estados previos, tenemos un modelo de Markov de segundo orden, produciendo una aproximación de tercer orden al lenguaje.
Shannon describió los procesos ergódicos de Markov como procesos en los cuales cada secuencia producida de suficiente longitud tiene las mismas propiedades estáticas que las frecuencias de letras y frecuencias de bigrams. En estos modelos cada estado del modelo puede alcanzarse desde cualquier otro estado en un número finito de pasos. El lenguaje natural es un ejemplo de un proceso ergódico de Markov.
Un modelo oculto de Markov(en inglés, Hidden Markov Model, HMM) es un proceso doblemente estocástico que consiste de: (a) un proceso estocástico subyacente que no puede observarse, y (b) un proceso estocástico cuyos símbolos de salida pueden observarse, representados por las probabilidades de salida del sistema. Los componentes esenciales de este modelo pueden resumirse en: el conjunto completo de probabilidades de transiciones, el conjunto completo de probabilidades de salida, y su estado inicial. Básicamente, un modelo HMM es un autómata finito en el cuál las transiciones entre estados tienen probabilidades y cuya salida también es probabilística. [Sharman, 89] establece que cuando estos modelos se aplican prácticamente, deben solucionarse tres problemas importantes: evaluación, estimación y entrenamiento.
El problema de evaluación es calcular la probabilidad de que una secuencia de símbolos observada ocurra como resultado de un modelo dado. En el problema de estimación se observa una secuencia de símbolos producidos por el modelo HMM. La tarea es estimar la secuencia más probable de estados que el modelo realiza para producir esa secuencia de símbolos. Durante el entrenamiento, los parámetros iniciales del modelo se ajustan para maximizar la probabilidad de una secuencia observada de símbolos. Esto permitirá que el modelo prediga secuencias futuras de símbolos.
La solución a la ecuación de la probabilidad de que sea la marca t1 dada la marca previa t0 dada la probabilidad de que la palabra1 tenga la marca t1 tiene al menos dos algoritmos conocidos: Viterbi y backward-forward.
Este modelo ha sido muy empleado en reconocimiento de voz, un tutorial extenso en este tema se encuentra en [Rabiner, 89]. Técnicas estadísticas basadas en HMM están bien establecidas [Holmes, 88] para esa área. En el área de análisis sintáctico, [Collins, 99] usó bigrams, es decir, probabilidades de dependencias entre pares de palabras, como estadísticas para mejorar el análisis sintáctico, emplea el núcleo-h del constituyente asociado a otro núcleo-h dependiente.
En las llamadas gramáticas de Markov [Charniak, 97] se almacenan las probabilidades que permiten inventar reglas de improviso. Por ejemplo, al inventar reglas de NP se debe conocer la probabilidad de que un NP empiece con un determinante (una probabilidad alta) o con una preposición (una probabilidad baja). Similarmente, al estar creando una frase nominal y con una entrada de determinante se debe saber cual es la probabilidad de que el siguiente constituyente sea un adjetivo (una probabilidad alta) u otro determinante (una probabilidad baja). Sin embrago, estas estadísticas se obtienen de los llamados bancos de árboles (tree-bank, en inglés), es decir, corpus analizados y marcados sintácticamente cuya labor manual es intensiva en extremo. También hay que considerar que tienen errores y son limitados.
Información Mutua entre palabras de una secuencia
A continuación se describe la llamada información mutua en el contexto establecido de la teoría de la información. Considerando h e i como los eventos que ocurren dentro de secuencias de eventos, en un contexto lingüístico, h podría ser una palabra de entrada a un canal ruidoso mientras que i es una palabra de salida del canal. h e i deben ser miembros de la misma secuencia. Por ejemplo, dos palabras que ocurren en una colocación idiomática.
[Sharman, 89] describe cómo la información mutua, denotada I(h, i) muestra qué información se provee del evento h por la ocurrencia de i. P(h | i) es la probabilidad del evento h habiendo ocurrido cuando se sabe que el evento i ha ocurrido, llamada la probabilidad a posteriori; y P(h) es la probabilidad del evento h habiendo ocurrido cuando no se sabe si i ha ocurrido, llamada la probabilidad a priori. La relación entre la probabilidad a posteriori de h y la probabilidad a priori de h es:
I(h, i) = log2 (P(h | i) / P(h))
[Church et al, 91] establecieron que la información mutua puede emplearse para identificar diferentes fenómenos lingüísticos, desde relaciones semánticas como doctor – enfermera, hasta preferencias de ocurrencia simultánea léxico- semántica entre verbos y preposiciones. En las primeras, se encuentra la fuerza de asociación contenida en las palabras, y en las últimas se encuentra la fuerza de asociación entre una palabra contenido y una palabra conexión. Mientras mayor es la información mutua, más genuina es la asociación entre dos palabras.
Este método fue empleado por [Yuret, 98] para encontrar los enlaces entre palabras, sin considerar información gramatical. Aunque obtiene un porcentaje de 60% de precisión entre relaciones de palabras de contenido, una deficiencia es que no se encuentran diferencias entre frases con diferentes preposiciones, por ejemplo el arquitecto está trabajando en el edificio gubernamental, y el arquitecto está trabajando sobre el edificio gubernamental.
Estadísticas Bayesianas
Cuando se emplean las estadísticas Bayesianas se trata la probabilidad condicional de una proposición dada una evidencia particular. Es decir, se trata de la creencia en una hipótesis más que su probabilidad absoluta. Este grado de creencia puede cambiar con el surgimiento de nueva evidencia.
La teoría de probabilidad Bayesiana [Krause & Clark, 93] puede definirse usando los axiomas siguientes:
· Primero p(h|e) la probabilidad de una hipótesis dada la evidencia, es una función monotónica[27] continua en el rango 0 a 1.
· Segundo, p(True|e) = 1, significa que la probabilidad de una hipótesis verdadera es uno.
· Tercero, el axioma p(h|e) + p(¬h|e) = 1 significa que ya sea la hipótesis o su negación será verdadera.
· Cuarto, la igualdad p(gh|e) = p(h|ge) × p(g|e) da la probabilidad de dos hipótesis que son simultáneamente verdaderas, lo cuál es igual a la probabilidad de la primera hipótesis, dado que la segunda hipótesis es verdadera, multiplicado por la probabilidad de la segunda hipótesis.
Del cuarto axioma se puede actualizar la creencia en una hipótesis en respuesta a la observación de la evidencia. La ecuación p(h|e) = p(e|h) × p(h)/p(e) significa que la creencia actualizada en una hipótesis h observando la evidencia e se obtiene la multiplicar la creencia previa en h, p(h), por la probabilidad p(e/h) de que la evidencia será observada si la hipótesis es verdadera. p(e/h) se llama la probabilidad a posteriori, mientras que p(e) es la probabilidad a priori de la evidencia. De esta forma, la probabilidad condicional y Bayesiana actualizadas permiten razonar de la evidencia a la hipótesis (abducción) tanto como de la hipótesis a la evidencia (deducción).
Otra consecuencia del cuarto axioma es la regla de cadena. La probabilidad de que los eventos A1 a An, todos ocurran (la distribución de probabilidad conjunta) se denota como p(A1, A2 … An) y es igual a p(An|, An-1 , …, A1) x p(An|, An-2 , …, A1) x … x p(A2 | A1) x p(A1). Por ejemplo, la propiedad de encontrar tres palabras en una secuencia es igual a la probabilidad de encontrar la tercera palabra dada la evidencia de las dos primeras palabras, multiplicada por la probabilidad de encontrar la segunda palabra dada la evidencia de la primera palabra, multiplicada por la probabilidad de la primera palabra.
Este tipo de análisis se ha empleado para combinar de manera óptima la información anterior a una palabra con la nueva evidencia provista por su ocurrencia, principalmente en reconocimiento de señales de voz [Rosenfeld, 94].
Reestimación de estadísticas
El valor de los modelos iterativos es que pueden emplearse aun cuando no hay una fórmula exacta para alcanzar una solución. En un procedimiento iterativo se hace una estimación inicial de la solución, y la estimación se prueba para ver si es aceptablemente próxima a la solución. Si no es así, la estimación se debe refinar. Las pruebas y las fases de refinamiento se repiten hasta que se alcanza una solución.
Ya que no se conoce una solución analítica para el problema de entrenamiento de los modelos ocultos de Markov, se pueden emplear técnicas iterativas, como el algoritmo de reestimación de Baum-Welch. La tarea es ajustar los parámetros del modelo para maximizar la probabilidad de una secuencia de símbolos observada [Sharman, 89].
Dado un modelo que produce una secuencia de
símbolos observada, se quiere encontrar ![]() , la probabilidad de que estando en un estado qi en el tiempo t se haga una transición al estado qj en el tiempo t+1.
, la probabilidad de que estando en un estado qi en el tiempo t se haga una transición al estado qj en el tiempo t+1.
![]()
donde:
![]() es la probabilidad de llegar
al estado qi en el tiempo tpor cualquier trayectoria que salga del
estado inicial, y produciendo el símbolo de salida Ot.
es la probabilidad de llegar
al estado qi en el tiempo tpor cualquier trayectoria que salga del
estado inicial, y produciendo el símbolo de salida Ot.
![]() es la probabilidad
de hacer la transición del estado qi
al estado qj . Las
probabilidades de la transición son parámetros originales del modelo.
es la probabilidad
de hacer la transición del estado qi
al estado qj . Las
probabilidades de la transición son parámetros originales del modelo.
![]() es la probabilidad
de producir el símbolo de salida en el siguiente paso
es la probabilidad
de producir el símbolo de salida en el siguiente paso ![]() . Las probabilidades de la salida también son parámetros
originales del modelo.
. Las probabilidades de la salida también son parámetros
originales del modelo.
![]() es la probabilidad de dejar el estado qj en el tiempo t+1 por cualquier trayectoria, y
eventualmente obtener el estado final.
es la probabilidad de dejar el estado qj en el tiempo t+1 por cualquier trayectoria, y
eventualmente obtener el estado final.
La probabilidad de estar en el estado qi en el tiempo t se llama ![]() y se encuentra al
sumar todos los valores de
y se encuentra al
sumar todos los valores de ![]() calculados para todos
los valores de i desde 1 hasta N, el
número total de estados en el modelo, como sigue:
calculados para todos
los valores de i desde 1 hasta N, el
número total de estados en el modelo, como sigue:
![]()
El número esperado de transiciones realizadas a
partir del estado qi se llama ![]() , la cuál es la suma de todos los valores de
, la cuál es la suma de todos los valores de ![]() calculados en cada
paso de tiempo desde t=1 hasta t=T , donde T es el número total de pasos tomados por el modelo, como se
muestra a continuación:
calculados en cada
paso de tiempo desde t=1 hasta t=T , donde T es el número total de pasos tomados por el modelo, como se
muestra a continuación:
![]()
El número esperado de transiciones realizadas del
estado qi al estado qj se llama ![]() , y es la suma de todos los valores de
, y es la suma de todos los valores de ![]() tomados en cada paso
de tiempo desde t=1 hasta t=T , como se muestra a continuación:
tomados en cada paso
de tiempo desde t=1 hasta t=T , como se muestra a continuación:
![]()
Con objeto de optimizar los parámetros del modelo
para maximizar la probabilidad de la secuencia observada, se vuelven a estimar
los valores de los tres parámetros que definen el modelo: las probabilidades
iniciales del estado, las probabilidades de transición y las probabilidades de
salida. Primero se reestima la probabilidad de cada uno de los estados
iniciales. La probabilidad original del modelo estando en el estado i se llama ![]() y la probabilidad
reestimada se llama
y la probabilidad
reestimada se llama ![]() . Los valores
. Los valores ![]() son iguales a los
valores
son iguales a los
valores ![]() , los cuales son los valores cuando t=1. En segundo lugar, la nueva estimación de cada probabilidad del
estado de transición, llamada
, los cuales son los valores cuando t=1. En segundo lugar, la nueva estimación de cada probabilidad del
estado de transición, llamada ![]() se encuentra usando
la relación
se encuentra usando
la relación
![]()
Ésta es la razón del número esperado de
transiciones de un estado al siguiente, dividido por el número total de
transiciones fuera de ese estado. Finalmente, la nueva estimación de cada
probabilidad de salida, llamada ![]() es la razón de numero
esperado de veces de estar en un estado y observar un símbolo, dividido por el
número esperado de veces de estar en ese estado, dado por:
es la razón de numero
esperado de veces de estar en un estado y observar un símbolo, dividido por el
número esperado de veces de estar en ese estado, dado por:
![]()
Se tiene entonces un modelo nuevo ![]() , el cuál está definido por los parámetros de reestimación:
, el cuál está definido por los parámetros de reestimación: ![]() . Estos valores pueden emplearse como los puntos de inicio de
un nuevo procedimiento de reestimación, para obtener las estimaciones de
parámetros que expliquen aún mejor la secuencia observada de símbolos.
. Estos valores pueden emplearse como los puntos de inicio de
un nuevo procedimiento de reestimación, para obtener las estimaciones de
parámetros que expliquen aún mejor la secuencia observada de símbolos.
Continuando este proceso iterativo, se llegará eventualmente a un punto donde los parámetros reestimados ya no son diferentes de los parámetros de entrada, es decir, los valores convergen. El punto de convergencia se llama un máximo local, que no impide la posibilidad de que el algoritmo pueda haber pasado por alto un mejor conjunto de parámetros llamado el máximo global. Si el máximo local es igual al máximo global, se encontró el conjunto de parámetros del modelo más próximo a explicar la secuencia observada de símbolos.
El algoritmo de Baum-Welch es un ejemplo de la clase de algoritmos denominados algoritmos de estimación-maximización (algoritmos EM), los cuales convergen en un máximo local. [Goodman, 98] presenta usos novedosos para las probabilidades interiores y exteriores, que se han empleado tradicionalmente para mejorar las probabilidades de las reglas de gramáticas CFG. Estas probabilidades se obtienen con algoritmos EM. La probabilidad interior es la probabilidad de que un no terminal consista exactamente de determinados terminales, es decir hacia dentro de su subárbol. Las probabilidades exteriores son las probabilidades de lo que está alrededor del no terminal, es decir, del contexto cercano. El producto de ambas probabilidades para los constituyentes de la oración da la probabilidad total de la oración con determinada estructura.
Existe una idea bastante extendida, tanto en la psicología como en la Inteligencia Artificial, de que en la mente humana los conceptos se encuentran relacionados entre sí formando una red. Bajo esta idea, cada concepto constituye un nodo de la red que se conecta con otros nodos mediante enlaces de distinta naturaleza. Los enlaces establecen el tipo de relación, entre ellos, algunos de los más empleados son: el enlace que indica pertenencia a una clase (“es un tipo de”), el de meronimia (“es una parte de”), el de sinonimia (“es igual que”), el de función (“tiene la función de”), el de contener (“contiene un”), etc. Este conjunto de nodos y enlaces se conoce como red semántica.
La red semántica es un conjunto de relaciones entre pares de palabras, o una combinación de palabras, refiriéndose a una cosa específica o idea. Si la palabra tiene diferentes sentidos, se incluyen en el diccionario en diferentes localidades y se marcan con diferentes números (por ejemplo banco1, banco2). Todos los sentidos de una palabra, aún los relacionados, tienen números diferentes y pueden conectarse explícitamente mediante relaciones. Así que una palabra puede representar muchos conceptos diferentes. De forma similar, un concepto puede representarse mediante varias palabras (banco1, taburete, etc.), pero por conveniencia el concepto se marca con una sola palabra y no con el grupo de homónimos.
Como se observa en la Figura 14 una red semántica es un grafo. En ese grafo, hay cadenas de relaciones como las antes descritas. Una trayectoria se traza siguiendo las relaciones de una palabra a otra. De esta forma se puede medir que tan cercanas o lejanas en la red se encuentran pares de palabras. Dos consideraciones importantes deben tomarse en cuenta, primero que algunas relaciones solamente están presentes de forma implícita, por lo que se presenta el problema de generar todas esas relaciones aplicando reglas de inferencia. Segundo, algunas veces la relación entre pares de palabras no se puede establecer mediante alguna relación existente, por ejemplo un ser humano PUEDE_TENER un amigo que ES_CAPAZ de beber, entonces se deben emplear las dos relaciones.
La dificultad que plantea este modelo simbólico es la delimitación de los diversos conceptos y de sus relaciones que intervienen en la red. Todavía se está muy lejos de poder establecer cuales son los conceptos básicos y de asignarles un contenido fijo. No hay por el momento un conjunto de conceptos o de primitivas semánticas universales. Por lo que cada grupo investigador tiene su conjunto de conceptos, aunque haya coincidencias entre ellos.
Aunque las redes semánticas también son una aproximación a las habilidades humanas y por lo tanto son modelos simplificados, pueden usarse de una forma acorde a sus limitaciones. Existen investigaciones en el área de lingüística computacional que han utilizado redes semánticas para resolver cierta clase de ambigüedad. Por ejemplo [Sanfilippo, 97] emplea WordNet [Miller, 90] para obtener automáticamente restricciones semánticas de ocurrencia concurrente para conjuntos de palabras relacionadas sintácticamente a partir de un corpus de textos. Propone crear clases de restricciones de ocurrencia concurrente, utilizando valores de entropía de los conceptos más informativos que incluyen en una categoría superior pares de palabras en la jerarquía.
|
Figura 14Red semántica para la frase
|
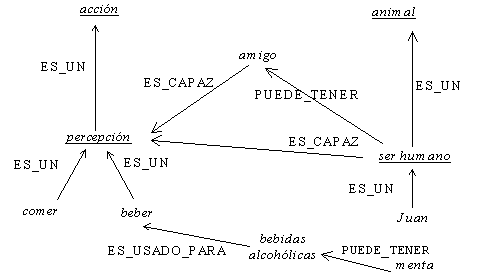
Otro trabajo es el de [Rigau et al, 97], quienes proponen un método para desambiguar sentidos de palabras en un corpus grande sin marcas. Emplean diversas heurísticas, de entre ellas una es la distancia conceptual y la utilizan para determinar la cercanía entre significados de palabras. Esta distancia conceptual es la distancia más corta que conecta los conceptos en la jerarquía. Emplearon WordNet como jerarquía y la distancia se mide entre la entrada de la definición del hipónimo y el genus de la definición del hiperónimo candidato.
En esta investigación también hacemos uso de la red semántica para reconocer cercanía de sentido entre grupos de constituyentes.
Capítulo 2.
Compilación del diccionario de verbos españoles con sus estructuras de
valencias
En este capítulo presentamos la caracterización de la estructura de valencias sintácticas con énfasis especial en las particularidades del español. Desarrollamos las características que se necesitan describir, presentamos estas características y sus valores para verbos y otras partes de la oración. Esta caracterización es finalmente la elaboración de las herramientas de la MTT para el análisis sintáctico del español, es decir el desarrollo de los patrones de manejo sintáctico para verbos principalmente, y también para sustantivos y adjetivos del español.
El problema de la caracterización es un problema de la lingüística general, pero aquí la consideramos más formalmente, desde el punto de vista computacional. Necesitamos términos y estructuras adecuadas para la descripción de los fenómenos lingüísticos. Las herramientas desarrolladas en la lingüística general se dirigen a los seres humanos, no a las computadoras, por lo que tenemos libertad para seleccionar medios semiformales. En la mayoría de los casos, tomaremos las estructuras usadas en la MTT, posteriormente mencionaremos otras maneras de descripción casi formal para enseguida presentar la comparación entre ellas.
En los patrones de manejo sintáctico se describentodaslas valencias de los verbos de acuerdo a su significado. En el español existen verbos con 0 valencias sintácticas y hasta 5, en general. Sin embargo, la mayoría de los verbos en español caen en el rango de 1 a 3 valencias. Algunas estadísticas acerca del número de valencias se presentaron en [Galicia et al, 98].
Comenzamos la explicación informal de los patrones de manejo, en el español, presentando algunos ejemplos de oraciones cuyos verbos tienen diferente número de valencias. Los números entre paréntesis indican las valencias semánticas y preceden a la correspondiente realización sintáctica.
|
Número de |
Ejemplos |
|
0 |
Llueve. |
|
1 |
(1) Juan duerme. |
|
2 |
(1) Juan mira (2) las montañas. |
|
3 |
(1) Juan acuerda (2) el proyecto (3) con su jefe. |
|
4 |
(1) Juan compra (2) un vestido (3) en la tienda (4) en 500 pesos. |
|
5 |
(1) Juan renta (2) un departamento (3) a María (4) por un año (5) en 500 pesos. |
Aunque en la literatura que trata temas de constituyentes, se denomina alternación a la posibilidad para un verbo dado de aparecer en más de un tipo diferente de marco de subcategorización [Alsina, 93], que pueden relacionarse uno a otro a través de un conjunto limitado de relaciones de mapeo, nosotros la denominamos variación ya que el término alternación se ha empleado principalmente como una noción morfológica [Alarcos, 84]. Ejemplos bien conocidos de estas variaciones son las siguientes:
· Existencia versus ausencia de objeto directo del verbo (su uso transitivo versus intransitivo). Por ejemplo Juan comió un taco y Juan comió.
· Agentiva versus instrumental. Por ejemplo: Juan quebró el florero con el martillo y El martillo quebró el florero. En el primer caso martillo es un instrumento, mientras que en el segundo, su función corresponde al agente que realiza la acción.
· Inversión. Por ejemplo: Juan cargó la paja en la carreta y Juan cargó la carreta con paja.
Mucho se ha escrito acerca de estas variaciones. [Atkins et al, 86] investigaron el rango de variaciones entre formas transitivas e intransitivas de verbos. [Levin, 93], [Levin & Rappoport, 91] exploran las relaciones entre el significado y las posibilidades de subcategorización para unos cuantos verbos, y sus agrupamientos relacionados. [Kilgarriff, 93] intenta generalizar el comportamiento de las variaciones en clases de verbos. Todos estos estudios consideran la clasificación de verbos, es decir, que se pueden agrupar diferentes verbos que presentan los mismos fenómenos sintácticos y que por lo tanto pueden analizarse en igual forma.
La clasificación de verbos se ha realizado desde diferentes perspectivas. En cuanto a estructura sintáctica se ha realizado considerando el tipo de complementos que son compartidos por diferentes verbos. Por ejemplo, en una forma simple, considerando el grupo de verbos transitivos cuyo objeto directo es un grupo nominal, o cuyo objeto directo es una frase preposicional, etc. [Kilgarriff, 92] presenta una clasificación de verbos más compleja, basada en conceptos semánticos y sintácticos en el nivel más alto de la jerarquía y con verbos de cierto tipo específico en los niveles inferiores.
Sin embargo, como se vio en la sección 1.2, en las consideraciones de la HPSG, algunos verbos con sentidos similares presentan diferentes marcos de subcategorización, además, como se verá más adelante, verbos con sentidos similares presentan diferentes números de valencias. Por lo que las clasificaciones, en cuanto a caracterización de valencia sintáctica y relación con la valencia semántica, no resulta ser la mejor forma de presentación.
En los patrones de manejo a diferencia de este tipo de clasificaciones, se describen individualmente las diferentes variaciones para cada verbo, lo que permite diferenciar las diferentes realizaciones sintácticas para cada verbo específico. En lugar de considerar diferentes grupos de variaciones como las mencionadas arriba, se analiza y describe individualmente cada verbo. Por ejemplo, establecer que el verbo comer tiene una segunda valencia opcional que indica qué cosa se come.
Las mencionadas clasificaciones tienen la desventaja de no permitir esta diferencia ya que al agrupar formas de subcategorización pueden quedar en clasificaciones diferentes las variaciones para un verbo dado. Por ejemplo, el verbo cargar, tiene tanto la forma de subcategorización GN GP(en), la paja en la carreta, como GN GP(con), la carreta con paja, que denotan la inversión de los actuantes semánticos en el nivel sintáctico. Tampoco es posible apoyarse en esa clasificación para separar verbos homónimos cuando se detectan diferentes sentidos.
Al describir individualmente las diferentes valencias sintácticas de los verbos se describe el sentido implícito en las diversas construcciones. Para comparar con los roles semánticos presentamos el ejemplo clásico de quebrar, que se describe en los siguientes ejemplos de [Allen, 95]:
Juan quebró la ventana con el martillo.
El martillo quebró la ventana.
La ventana se quebró.
La tercera frase corresponde a la traducción del inglés de The window broke. Desde la perspectiva de roles temáticos, Juan es el actor (el papel del agente), la ventana es el objeto (el papel de tema) y el martillo es el instrumento (el papel de instrumento) usado en el acto de quebrar. La idea en los roles temáticos es generalizar los posibles participantes.
Desde el punto de vista de los actuantes semánticos, el sentido implicado requiere diferenciarse:
· En la oración Juan quebró la ventana con un martillo, una entidad animada utiliza un objeto para separar en dos o más partes otro objeto, con un fin determinado. Así que en la frase Juan quebró la ventana, está ausente el instrumento, que pudiera ser incluso su mismo cuerpo.
· En la oración El martillo quebró la ventana, un objeto separó en dos o más partes otro objeto; sin la participación de una entidad animada con un propósito específico.
· En la tercera oración La ventana se quebró, es una variante de se quebró la ventana, que indica la ausencia del objeto que separó en dos o más partes la ventana.
La descripción del verbo quebrar indicando sus valencias y posible separación en homónimos se presentará en Mapeo de valencias semánticas a sintácticas de la sección 2.8. De lo anterior, se desprende que el número de valencias sintácticas resulta de determinados rasgos semánticos, que deberán considerarse para caracterizar los verbos específicos. Este hecho se amplía en la sección 2.8
2.2 Ejemplos de patrones de manejo para verbos.
Aunque en los ejemplos de verbos que a continuación presentamos mencionamos la clasificación usual de transitivos e intransitivos también indicamos las diferencias que las valencias presentan.
Para todos los verbos del español en modo activo, la primera valencia o primer actuante es el sujeto gramatical de la oración, como se considera en la gramática clásica, y en forma simple se denomina sujeto[28]. Para muchos verbos, las características sintácticas del sujeto lo definen como un sustantivo animado. En la sección 2.4 daremos detalladamente las consideraciones de animidad en el español. Entonces, la lista de características sintácticas para el sujeto de esos verbos es (S, an), donde S indica sustantivo, y puesto que la marca de animidad sólo se da en sustantivos, esa lista podría simplificarse a (an).
La mayor parte de la información del sujeto en las oraciones en español, es común a casi todos los verbos, por lo que es mejor concentrarla en la gramática en lugar de situarla en los patrones de manejo sintáctico. Así que la descripción del sujeto, en los patrones de manejo sintáctico, normalmente se limitaría a la lista de índices léxico-semántico y semántico, como se verá en los ejemplos siguientes.
Verbos sin valencias
Los verbos españoles que no presentan ninguna valencia son los verbos que sólo se conjugan en tercera persona como: llover, granizar, nevar.
llover
water falls to earth in drops
Solamente se considera su descripción.
Verbos con una valencia
Algunos verbos españoles intransitivos tienen únicamente la valencia que corresponde al sujeto, por ejemplo el verbo cojear:
cojear
person or animal X walks lamely
1 = X; quién cojea?
1.1 S % el hombre ~
% el gato ~
Por definición, los verbos intransitivos no pueden tener un complemento directo. Sin embargo, la ausencia del complemento directo es una peculiaridad puramente sintáctica. Los verbos intransitivos pueden tener otras valencias representadas mediante diversos complementos indirectos. Estas valencias, en el patrón de manejo, se numeran usualmente en el orden de importancia de ellas.
En los diccionarios comunes la información de las propiedades sintácticas de los verbos intransitivos de los lenguajes naturales, como el español, no considera estos posibles complementos. En el análisis sintáctico de textos por computadora es esencial esta definición para reducir la ambigüedad sintáctica. Por ejemplo, el verbo perecer tiene una segunda valencia realizada sintácticamente mediante un complemento indirecto que expresa la causa de la acción.
perecer
X ceases to live because of Y
1 = X; qué/ quién perece?
1.1 S % el hombre ~
2 = Y; de qué?
2.1 de S % ~ de hambre
% ~ de frío
Estos verbos intransitivos tienen más de una valencia semántica y, en términos rigurosos, no pertenecen al grupo bajo consideración. Para marcar que algunos verbos intransitivos pueden presentar otras valencias, algunos diccionarios como LDOCE [Procter et al, 78] consideran la clasificación de intransitivos estrictos. Esta misma clasificación fue considerada en la descripción de subcategorización en las Gramáticas Categoriales (sección 1.2).
Verbos con dos valencias
Los verbos transitivos, por definición, tienen una segunda valencia semántica denominada en el nivel sintáctico como objeto directo o complemento directo. En muchas lenguas europeas, el complemento directo se une al verbo directamente, sin preposiciones. En español, existen dos posibilidades para esta conexión. Los sustantivos inanimados (na) generalmente se unen directamente al verbo, en cambio, los sustantivos animados (an) usualmente se unen al verbo mediante la preposición a.
Una característica de los verbos transitivos es que el complemento directo es obligatorio. Por ejemplo, la frase *Juan quiere no es gramatical, requiere la indicación explícita de qué o a quién quiere Juan. Indicamos esta condición de obligatoriedad con el signo derecho de admiración (!) exactamente después de la fórmula de equivalencia entre valencias sintácticas y semánticas, por ejemplo: 2 = Y!; de qué? Cuando la valencia no es obligatoria en el nivel sintáctico aparece únicamente el punto y coma.
A continuación presentamos un patrón de manejo sintáctico para el verbo transitivo querer:
querer1
person X experiences positive feelings to person Y
1 = X; quién quiere?
1.1 (S, an) % el padre ~
2 = Y!; a quién?
2.1 a (S, an) % ~ a su hijo
Verbos con tres valencias.
Los verbos considerados en la gramática clásica como doble transitivos tienen tres valencias. La tercera valencia se denomina objeto indirecto o complemento indirecto. En el español, los complementos indirectos siempre están unidos al verbo mediante preposiciones, por lo que frecuentemente se les denomina objetos preposicionales. Por ejemplo, el verbo solicitar:
solicitar
X asks something Y from Z
1 = X; quién solicita?
1.1 (S, an) % Juan / el gobierno ~
2 = Y!; qué solicita?
2.1 (S, na) % ~ una prórroga / un préstamo
2.2 que C % ~ que este libro se le dé
2.2 (V, inf) % ~ cancelar la autorización
3 = Z; de quién solicita?
3.1 a (S, an) % ~ a la secretaria
3.2 con (S, an) % ~ con el secretario
3.3 de (S, an) % ~ de usted
donde C indica una cláusula subordinada.
En el ejemplo Juan solicita una prórroga al gobierno, la primera valencia es el sujeto y la segunda el complemento directo. Para este verbo, se observa que además de que el complemento directo es obligatorio (no es posible decir *Juan solicita al gobierno, sin indicar qué se solicita), existe un conjunto de preposiciones con las cuales la tercera valencia se une al verbo: a, con, y de (a diferencia de perecer donde la preposición de es la única que introduce la valencia).
La diferencia de significado de las frases solicita un pase con el secretario y solicita un pase al secretario no es de considerar, en la mayoría de los casos. Estas preposiciones no son sinónimas, su equivalencia está implicada en el verbo que las emplea. Otros verbos pueden usar un conjunto diferente de preposiciones para propósitos similares.
En la mayoría de los ejemplos previos las valencias se realizaron con sustantivos, pero las valencias pueden realizarse de formas diferentes. Por ejemplo, la segunda valencia del verbo solicitar, se puede realizar con que C.
Verbos con cuatro valencias
Otro ejemplo, el verbo condenar muestra el caso de una preposición que introduce un verbo en infinitivo:
condenar
person X condemns person Y to Z for action W
1 = X; quién condena?
1.1 (S, an) % el juez ~
2 = Y!; a quién condena?
2.1 a (S, na) % ~ al acusado
3 = Z; a qué?
3.1 a (S, na) % ~ a cadena perpetua
4 = W; por cuál motivo?
4.1 por (S, na) % ~ por asesinato
4.2 por (V, inf) % ~ por matar
En este ejemplo, la cuarta valencia presenta una forma diferente de realización de las anteriores, con un verbo en infinitivo, además de la forma más común, mediante un sustantivo.
En la gramática española [Seco, 72] se considera el hecho de que la forma del verbo refleja las distintas funciones que desempeña el núcleo de la oración; por ejemplo, cuando funciona como sustantivo, aparece en infinitivo. Para funcionar como adjetivo aparece en forma de participio, cuando funciona como adverbio, aparece como gerundio. Frecuencias de aparición de los distintos usos del infinitivo se encuentran en [Luna-Traill, 91], [Arjona-Iglesias, 91] y [Moreno, 85].
[Gili, 61] indica que mientras el francés desde el siglo XVI limitó mucho el número de infinitivos que pueden sustantivarse, el español ha conservado esta libertad, donde además se sustantiva la forma reflexiva. También indica que otras lenguas como el francés, el alemán y el inglés, limitan el número de preposiciones que pueden unirse al infinitivo, o bien restringen las construcciones verbales y sustantivas a que pueden aplicarse. Por lo que el empleo amplio de las preposiciones con los verbos en infinitivo es una peculiaridad más del español
El uso de preposiciones lleva aparejada ciertas dificultades. En algunos verbos, una frase preposicional describe tanto valencias del verbo como circunstancias. Por ejemplo, algunos verbos locativos [Rojas, 88] requieren complementos con la noción de espacio, cuya marca aparece tanto en la palabra introductora del complemento como en el complemento mismo. Por ejemplo, con el verbo colocar:
colocar1
person X puts Y in place Z
1 = X; quién coloca?
1.1 (S, an) % el estudiante ~
2 = Y!; qué/ a quién coloca?
2.1 (S, na) % ~ los libros
3 = Z; dónde coloca?
3.1 en/sobre (S, na) % ~ en el estante
3.2 (Adv, loc) % ~ aquí
En la frase coloca un libro en este momento en el espacio disponible, la frase preposicional en NP describe tanto una valencia (en el espacio libre) como un complemento (en este momento) que es circunstancial de tiempo. Por lo que se requiere un descriptor como en el caso de animidad que distinga estos casos. Entonces la tercera valencia se modifica a:
3 = Z; dónde coloca?
3.1 en (S, loc) % ~ en el estante
3.2 sobre (S, na) % ~ sobre la mesa
3.3 (Adv, loc) % ~ aquí
En donde loc indica sentido locativo del sustantivo.
Verbos con cinco valencias
Por último, presentamos un ejemplo, el verbo rentar que tiene cinco valencias:
rentar
person X uses the possession Y of the owner Z giving in return a quantityW by a period V
1 = X; quién renta?
1.1 (S, an) % María ~
2 = Y!; qué renta?
2.1 (S, na) % ~ un departamento
3 = Z; a quién?
3.1 a (S, na) % ~ a la compañía Zeta
4 = W; en cuanto?
4.1 en (S, na) % ~ en dos mil pesos
5 = W; por qué período?
5.1 por S(tm) % ~ por mes
5.2 a S(tm) % ~ al mes
Donde tm significa tiempo y se refiere a un sustantivo que denota intervalo de tiempo.
2.3 Ejemplos de patrones de manejo para sustantivos y adjetivos
Los adjetivos y los sustantivos difieren de los verbos, en las valencias que presentan, específicamente en la primera valencia. En los adjetivos, la primera valencia semántica es el correspondiente sustantivo que el adjetivo modifica. Desde el punto de vista semántico, los adjetivos son lexemas predicativos, que al menos tienen una valencia. El primer actuante es precisamente la palabra expresada mediante un sustantivo. En los verbos, la dirección de rección va del verbo al sujeto. En cambio en los adjetivos, la dirección de rección sintáctica es inversa, el arco de la relación sintáctica va del sustantivo al adjetivo. La razón es que el sustantivo es la palabra dominante y el adjetivo es la palabra dependiente.
El primer ejemplo que presentamos es un adjetivo homónimo: blanco. En español, existen al menos dos significados diferentes: blanco1 con sentido referido al color, y blanco2 con sentido referido a inocencia o pureza. Cada uno de estos homónimos tiene una sola valencia. Puesto que esta valencia no implica la correspondiente dependencia sintáctica, la fórmula 1 = X! tiene un carácter condicional y representa la llamada valencia pasiva. En este caso, la dependencia sintáctica (adjetivo de un sustantivo) es contraria a la dependencia semántica (sustantivo de adjetivo atributivo). Esta peculiaridad es inmanente a los adjetivos en muchos lenguajes, y desaparece al nivel semántico.
blanco1
physical object X is of white color
1 = X!
1.1 (S, <Phys-obj>) % la pintura ~
blanco2
narrative X is innocent or pure
1 = X!
1.1 (S, <Narr>) % chistes ~
Como usualmente la diferencia entre los homónimos se manifiesta en los descriptores semánticos de cada opción, <Phys-obj> denota un objeto del mundo y <Narr> denota el elemento del texto.
Los descriptores pueden emplearse para la desambiguación de los homónimos, cuando los dominios que ambos abarcan no intersectan. Por ejemplo, en la frase, una pintura blanca, blanca sólo puede referirse al color. En cambio, en la frase, un libro blanco hay duda del sentido asignado, el color del libro o su contenido.
Existen adjetivos con dos valencias. Por ejemplo, el adjetivo lleno en el que la segunda valencia expresa el objeto preposicional con el significado de establecer qué contiene en toda o casi toda su capacidad.
lleno
object X is full of object Y
1 = X!
1.1 (S) % el estadio ~
2 = Y; de qué?
2.1 de (S) % ~ de gente
El primer ejemplo que consideramos para los sustantivos, es un sustantivo que no deriva de forma verbal:
presidente
person X is the highest official of country or organization Y
1 = X; quién?
1.1 (S, Propr) % ~ Adolfo López Mateos
2 = Y; de qué país u organización?
2.1 de (S, <Org>) % ~ de México, ~ del club
2.2 ¯A0(<Org>) % ~ mexicano
El parámetro <Propr> denota una palabra o secuencia de palabras que expresan un nombre de persona; <Org> denota una subclase semántica de sustantivos que expresan un nombre oficial de una organización, la cuál puede ser de tipo social, político o cualquier otro tipo e incluye nombres de países.
La opción 2.2 es muy específica. El signo ¯ indica que la información de esta opción, en el nivel sintáctico, no se expresa mediante dependencia de valencia sino por una de atribución, mientras que en un nivel más profundo la diferencia se elimina y la valencia semántica puede derivarse y representarse explícitamente. El término A0() es una función que deriva un adjetivo a partir del argumento, que es un sustantivo. Por ejemplo, A0(México) = mexicano, A0(España) = español, etc. En términos generales, esta opción presenta el ejemplo de una valencia semántica expresada por medio de otras dependencias sintácticas, ya que México y España son valencias semánticas.
Otro ejemplo con esta característica es el sustantivo conclusión, donde la opción 2.2 se expresa mediante adjetivo posesivo:
conclusión1
It is the reasoned deduction or inference of person X on subject Y
1 = X; de qué persona?
1.1 de (S, <Person>) % ~ del profesor
1.2 ¯ (Adj, poss) % mi ~
2 = Y; sobre qué cosa?
2.1 sobre (S) % ~ sobre el proyecto
2.2 de que C % ~ de que el proyecto es...
2.3 de (S) % ~ de una serie de investigaciones
En este caso la marca de animidad se cambió por el descriptor semántico persona <Person>. En la mayoría de las ocasiones ambas etiquetas significan lo mismo, seres humanos. Pero la animidad se aplica también a entidades personificadas como animales, grupos de personas, países, etc. y realmente el sentido es más estrecho en este caso donde no es posible imaginar su uso en el ámbito extendido de personificación. Aunque por otro lado, en el mundo contemporáneo, una conclusión también puede realizarla un autómata que razone. El descriptor semántico corresponde al ámbito bastante estrecho de este caso particular. Puede ocurrir que el descriptor de este tipo no “funcione” correctamente en casos de métafora.
El último ejemplo que presentamos es el sustantivo querella, que generalmente no va acompañado de adjetivos.
querella1
complaint of perosn X against person Y on subject Z
X = 1; de quién?
1.1 de (S, an) % del vecino ~
1.2 ¯ (Adj, poss) % mi ~
Y = 2; contra quién?
2.1 contra (S, an) % ~ contra quién resulte responsable
2.2 en contra de (S, an) % ~ en contra de Juan
Z = 3; por qué?
3.1 por (S, na) % ~ por robo
3.2 por (V, inf) % ~ por defraudar
3.3 de (S, na) % ~ de robo
La segunda valencia sintáctica presenta una de las peculiaridades de muchos lenguajes modernos: se trata de una preposición compuesta. Además de las preposiciones comunes simples que registran los diccionarios como tales, existen numerosas locuciones preposicionales o locuciones prepositivas en las cuales figuran ordinariamente un sustantivo o un adjetivo: alrededor de, encima de, dentro de, junto a, frente a, enfrente de, etc. y otras muchas que ocasionalmente pueden crearse para precisar la relación, a veces poco definida, de las preposiciones solas. De esta manera, y con la combinación de dos o más preposiciones, el español compensa el número relativamente escaso de preposiciones simples.
Algunas de estas locuciones prepositivas son casi del todo equivalentes a preposiciones simples, y en ocasiones más usadas que éstas: delante de (= ante), encima de (= sobre), debajo de (= bajo), detrás de (= tras). También el adverbio se suma a la función enlazadora aportada por la preposición, y la unión de las dos palabras se convierte en una nueva preposición: antes de, encima de.
Se forman nuevos conjuntos uniendo las preposiciones a otras preposiciones, dando lugar a complejos característicos del español, en los que la aglomeración de preposiciones expresa una gran variedad de relaciones. Por ejemplo: de entre ellos, de con sus amigos, desde por abajo, hasta con sus compañeros, para entre nosotros, por de pronto. A veces llegan a reunirse hasta tres preposiciones, por ejemplo: hasta de con sus compañeros fueron a buscarla; desde por entre los árboles nos espiaban. Estos grupos se consideran como una sola preposición introductora de realizaciones sintácticas en los patrones de manejo.
2.4 Dependencia del objeto directo en la animidad, como una peculiaridad del español
En la mayoría de los lenguajes el objeto directo está conectado con el verbo directamente, sin preposiciones, es por esto precisamente que este objeto se denomina directo. Por el contrario, en español, las entidades animadas están conectadas a su verbo rector con la preposición a (veo a mi vecina)y las no animadas directamente (veo una casa). La animidad en español se considera como una personificación. Por ejemplo, gobierno en español es un sustantivo animado y al dirigirse a él se utiliza la preposición a (condenó al gobierno). Además de personas, la animidad abarca grupos de animales, personas, organizaciones, partidos políticos, países, etc.
En otros lenguajes, por ejemplo el ruso, también existe una categoría de animidad similar que determina la terminación del caso morfológico del complemento directo, pero los grupos de personas, los países, las ciudades no se personifican en sentido gramatical[29].
Entonces la regla léxica del español es que el complemento directo está unido al verbo rector a través de la preposición a para entidades animadas y directamente en los otros casos. Su empleo es específico del español y lo distingue de otros lenguajes europeos. Pero la animidad en español realmente es aún más complicada, ya que en algunos contextos de indefinición o de conteo el complemento directo animado puede eliminar la necesidad de la preposición, por ejemplo: Vio un niño que corría; Necesita tres ayudantes. El contexto influye en algunos casos para incluir la conexión de objeto directo o eliminarla. Por ejemplo, un animal es animado en un ámbito de relación cercana al hablante: veo a mi perro adorado y es no animado en un ámbito de relación lejana: veo el perro que corre por la pradera.
Por el orden de palabras no estricto del español, se presentan combinaciones donde existe ambigüedad para detectar el objeto directo. Por ejemplo la frase la realidad supera la ficción podría presentarse en la forma verbo, sujeto, objeto directo (*supera la realidad la ficción). Para comprender la frase correctamente, es decir, para identificar los argumentos, se emplea la preposición a antes de objetos inanimados: supera la realidad a la ficción.
Entonces, la categoría de animidad tiene en el español, dos valores opuestos: an (animado) y na (no animado). En el siguiente patrón de manejo mostramos las distintas formas en que se presenta la marca de animidad.
atrapar1
X using force catches Y
1 = X; quién atrapa?
1.1 (S, an) % el policía / el gato ~
2 = Y!; qué / a quién?
2.1 (S, na) % ~ la maleta
2.2 a (S, an) % ~ a un ladrón
En la primera valencia se expresa el uso de sustantivos animados, en la segunda valencia se expresa el objeto directo con sustantivos no animados (S, na) y con la marca de animidad (S, an). Esta última responde precisamente a la pregunta ¿a quién? que se aplica tanto a una persona o a un animal, como a un grupo, a un partido, etc. Por ejemplo: ¿A quienes atrapó la policía? y la respuesta: al equipo de futbol de la secundaria 28.
Así que la animidad es una característica evidentemente sintáctica pero con alusión semántica que se considera para la realización de las valencias. Su principal importancia es la característica gramatical del español al conectar el objeto directo animado con preposición, aunque como hemos visto su uso puede ser útil para otros casos.
Si definimos la noción de animidad en un sentido puramente semántico, como una característica de los seres vivos, entonces comprenderíamos de inmediato que hay una gran diferencia entre esa noción semántica y la animidad gramatical. La animidad semántica, entonces, sólo debería tomarse como característica de valencias de verbos orientados a “lo humano” como leer, cuyo sujeto puede ser solamente un ser humano o un autómata inventado en este último siglo con ese fin específico. En otros casos deberá ser únicamente asociada a los seres humanos ya que es difícil, al menos en este tiempo, asociar un autómata con verbos como: procrear, morir o imaginar.
Por supuesto que no consideramos ni las metáforas ni la poesía como ¡Canta, lluvia, en la costa aún sin mar![30] ya que la comprensión de ellas será posiblemente comprendida por las computadoras, en siglos futuros.
Ya que la noción de animidad en el sentido semántico de criaturas vivientes no incluye las entidades personificadas, se requiere una mayor investigación para definir exactamente si en todas las aplicaciones la característica de animidad es la misma característica de animidad del español o una muy similar a la característica semántica de seres vivientes. Por lo que de aquí en adelante emplearemos únicamente la característica de animidad gramatical para otras valencias.
Es conocido que la preposición a también tiene otros usos, no relacionados con la conexión del objeto directo. Pero aún para el objeto directo su empleo puede servir para diferenciar el significado de algunos verbos, por ejemplo, querer algo (tener el deseo de obtener algo) y querer a alguien (amar o estimar a alguien). El primero ya se presentó en la sección 2.2 como querer1 y el segundo corresponde a:
querer2
person X desires thing Y
1 = X; quién quiere?
1.1 (S, an) % el niño ~
2 = Y!; qué?
2.1 (S, na) % ~ un triciclo
Otra utilidad del empleo de la animidad, está relacionada con la primera valencia de algunos verbos, es decir, con el sujeto, y con su detección para reconocer valencias sintácticas. Por ejemplo, el verbo acusar, tiene dos homónimos: acusar1 (denunciar a alguien como culpable de algo) y acusar2 (revelar algo, ponerlo de manifiesto) conforme a [DEUM, 96]. Presentamos a continuación sus patrones de manejo:
acusar1
person X accuses person Y of action Z
1 = X; quién acusa?
1.1 (N, an) % el ministro ~
% la madre ~
2 = Y!; a quién acusa?
2.1 a (N, an) % ~ a los políticos
% ~ a los niños
3 = Z; de qué?
3.1 de (N, na) % ~ de robo
3.2 de (V, inf) % ~ de defraudar
acusar2
X reveal Y
1 = X; quién/ qué acusa?
1.1 S % el ministro ~, la puerta ~
2 = Y!; qué acusa?
2.1 (S, na) % ~ cansancio
% ~ el paso de los años
En algunas construcciones de acusar1 como las siguientes, el sujeto aparece pospuesto al verbo en dos formas: como nombre propio y como nombre común:
· Al director le acusaba Apel de desembocar en una ilusión idealista por ocuparse de <...>.
· En el presunto fraude aparece como principal sospechoso José Joaquín Portuondo, a quien acusaron varios testigos.
En la primera frase el reconocimiento de nombre propio permite identificar el sujeto. En la segunda frase se requiere reconocer la entidad animada marcada en la realización del sujeto de acusar1, es decir, reconocer que varios testigos es el sujeto. De esta forma no habrá confusión con el objeto de acusar2, por ejemplo en oraciones donde las realizaciones de las valencias no son muy diferenciadas: Que acusaba un alto rendimiento, le acusaba un alto magistrado. Esta confusión puede resultar en una asignación de estructura incorrecta o en detección de valencia de otro sentido.
Generalmente las entidades referidas por las diversas valencias sintácticas son diferentes. Ésta es una situación normal en los lenguajes naturales: cada valencia semántica se puede representar en el nivel sintáctico por solamente un actuante.
Pero existen lenguajes en los cuales se permite la repetición restringida de actuantes. El español se cuenta entre esos lenguajes. En las frases siguientes, en cada oración, los dos segmentos disjuntos marcados con negritas se refieren al mismo objeto:
· Arturo le dió la manzana a Victor.
· El disfraz de Arturo, lo diseñó Victor.
· A Victor le acusael director.
Mientras en la primera frase se repite el objeto indirecto, en las dos últimas frases se repite el objeto directo.
Algunas veces la repetición es obligatoria. El orden de palabras y los verbos específicos imponen ciertas construcciones. Por ejemplo, la anteposición de los argumentos dativos y acusativos presenta una complicación.
Las siguientes frases con objeto directo no permiten la duplicación:
Arturo escribió la carta.
Escribió Arturo la carta.
En cambio la anteposición del objeto directo (*La carta escribió Arturo.) requiere o una marca de puntuación o la duplicación para ser correcta:
La carta, Arturo la escribió.
La carta la escribió Arturo
Para el objeto directo animado, que se introduce con la preposición a, tenemos los siguientes ejemplos:
El frío mató a la mosca.
Mató el frío a la mosca.
Mató a la mosca el frío.
Pero la anteposición del objeto directo animado (*A la mosca mató el frío.) requiere la duplicación para ser correcta:
A la mosca la mató el frío.
En el ejemplo para objeto indirecto que a continuación mostramos, se permite la duplicación:
Arturo escribió una carta a Victor.
Arturo le escribió una carta a Victor.
También la anteposición del objeto indirecto (*A Victor escribió una carta Arturo.) requiere la duplicación para ser correcta:
A Victor le escribió una carta Arturo.
[Zubizarreta, 94] afirma que la existencia de objetos doblados por clíticos es una diferencia más del español, ya que no existe en el italiano escrito, ni en el francés ni en algunos otros lenguajes europeos.
Notamos, por el contrario, que los siguientes ejemplos no están relacionados con la repetición de objetos, corresponden a otra condición. Mientras en la primera frase se omitió la tercera valencia del verbo ordenar (a quién se ordenó algo), en la segunda frase se representó con le.
El juez ordenó tomar declaración al acusado.
El juez le ordenó tomar declaración al acusado.
El objeto indirecto a nadie también puede repetirse con el clítico dativo pero dentro de su propia claúsula, no puede moverse a cláusulas superiores [Zubizarreta, 94]. Por ejemplo:
A nadie le dijo Juan de su boda.
*A nadie piensa María que le dijo Juan de su boda.
Los pronombres personales también se pueden repetir:
A todos les dijo Juan de su boda.
En todos los casos la repetición de actuantes, se restringe mediante las siguientes reglas:
· Uno de los actuantes repetidos es un pronombre personal en caso indirecto (acusativo o dativo). Para las formas personales este pronombre usualmente permanece justo antes del verbo rector, en los infinitivos se pega al verbo.
· Otra repetición del mismo actuante se da con un sustantivo, pronombre o algún otro medio. Pero en el caso de un pronombre personal, se pone en nominativo, por ejemplo: A ellas las encontrarás en la tienda.
En el nivel semántico de representación, todos los casos de esas repeticiones deben juntarse, es decir, se debe dejar un solo representativo de cada actuante semántico.
2.7 El complemento beneficiario en el español y su duplicación
En la caracterización semántica de complementos de muchos verbos en varios lenguajes, se considera la noción importante de la persona que recibe el interés, la beneficiaria, y la persona destinataria. El interés incluye los sentidos de daño y provecho. Para nuestro estudio son importantes los siguientes aspectos:
· Las personas beneficiaria y destinataria están representadas por el mismo objeto indirecto, como en enseñar algo a alguien, donde a alguien es tanto el beneficiario como el destino. En este caso hay que hacer notar que el complemento beneficiario corresponde a una valencia semántica del verbo.
· El beneficiario de la acción no corresponde a ninguna valencia. Es como una circunstancia. Usualmente se introduce mediante la preposición para. Por ejemplo: comprar un libro para alguien, donde el beneficiario se representa con un complemento circunstancial del verbo.
Claro que la preposición para puede introducir también otro tipo de complementos. Por ejemplo, en la frase todo esto es para que te acostumbres (con el sentido de meta), habla muy bien para la edad que tiene (con el sentido de comparación).
Algunos verbos llevan entonces el complemento beneficiario con cualquiera de las preposiciones: a o para, por ejemplo:
Victor concedió una entrevista a la revista C&S.
Victor concedió una entrevista para la revista C&S.
En estas frases puede haber una ligera discrepancia en el sentido, si la acción se realizó directamente o indirectamente. Sin embargo el beneficiario y el destino coinciden. Otras frases pueden mostrar ambigüedad de sentido con esta alternancia de preposiciones:
Emma escribe una carta a Emilio.
Emma escribe una carta para Emilio.
En esta sección nos concentramos en el complemento beneficiario del verbo predicativo y no en otros beneficiarios expresados en la oración, por ejemplo:
Paco dio un libro a su ayudante para Emilio.
Donde para Emilio es complemento beneficiario de un libro y el complemento que recibe el interés del verbo dar es el complemento a su ayudante, es decir, Paco dio a su ayudante un libro para Emilio.
Introducimos una clasificación de verbos de acuerdo a características transitiva, dativa y benefactiva.
En esta sección, los verbos del tipo 0 y 1, sin beneficiario potencial, no son relevantes. No existen verbos con características dativa y benefactiva distintas, por lo que no consideramos los tipos 6 y 7. A continuación presentamos ejemplos de cada tipo:
Del tipo 2 son: corresponder, competer, convenir, doler, parecerse, gustar, faltar, etc. Ejemplos de frases: La creación de leyes corresponde al gobierno, Este asunto compete a todos. Con repetición dativa: La creación de leyes le corresponde al gobierno, Este asunto les compete a todos.
|
Tipo |
Transitivo |
Dativo |
Benefactivo |
Nota |
|
0 |
¾ |
¾ |
¾ |
No relevante |
|
1 |
+ |
¾ |
¾ |
No relevante |
|
2 |
¾ |
+ |
¾ |
|
|
3 |
+ |
+ |
¾ |
|
|
4 |
¾ |
¾ |
+ |
|
|
5 |
+ |
¾ |
+ |
|
|
6 |
¾ |
+ |
+ |
No existen |
|
7 |
+ |
+ |
+ |
No existen |
Del tipo 3 son los más comunes: dar, enseñar, asignar, preguntar, costar, interesar, servir (algo a aguien), etc. Ejemplos de frases: Alberto enseña anatomía a sus alumnos, Alberto preguntó todos los pormenores al abogado. Con repetición dativa: Alberto les enseña anatomía a sus alumnos, Alberto le preguntó todos los pormenores al abogado.
Del tipo 4 son: laborar, cabildear, etc. Ejemplos de frases: Rodrigo labora para la compañía X. Los políticos cabildean para sus amos. Con repetición benefactiva: no se encontraron.
Del tipo 5 son: comprar, componer, comprobar, etc. Ejemplos de frases: Emilio compone los audífonos para su hermano. Arturo comprueba los resultados para su jefe. Con repetición benefactiva: Emilio le compone los audífonos a su hermano. Arturo le comprueba los resultados a su jefe.
Existe una larga discusión acerca de la naturaleza argumental del complemento benefactivo. Entre los autores, [Branchadell, 92] para el español y [Jackendoff, 90] para el inglés, consideran que los benefactivos no son valencias pero se comportan como ellos, por esto los podemos denominar casi valencia.
En el español, el punto de vista de consideración como casi valencia está bien fundada ya que a veces se duplica. Pero esta duplicación está sujeta a ciertas restricciones de realización léxica. Se realiza mediante un pronombre personal en la forma clítica o mediante un grupo preposicional. Por ejemplo:
Emma le ha reservado unos lugares a su familia.
En esta frase tanto le como a su familia representan la cuasi valencia benefactiva, de la misma forma que me y a mí en el siguiente ejemplo:
Emma me ha reservado unos lugares a mí.
Sin embargo, la frase:
Emma ha reservado unos lugares para su familia.
no permite esa clase de repetición. Otros ejemplos presentados por [Demonte, 94] explican cómo la cuasi valencia benefactiva no es posible en ciertas estructuras, por ejemplo:
Le coloqué cortinas al salón.
*Coloqué cortinas para el salón.
*Le coloqué cortinas para el salón.
Y tampoco es posible en ciertos contextos, por ejemplo:
Le puse el papel a la pared.
*Le puse un clavo a la pared.
La autora considera que es por razones del mundo, la pared forma una unidad con el papel y el clavo no.
En otros casos puede verse claramente que existe una distinción entre el complemento indirecto y el destinatario, comparando la diferencia de significado que presentan las dos frases siguientes:
Le di un mensaje para ti.
Te di un mensaje para él.
En los ejemplos, le y te son los complementos indirectos, en cambio para ti y para él son los complementos de destinatario. Si todos los complementos subrayados fueran indirectos, no habría diferencia de contenido entre las dos oraciones.
Esta casi valencia con duplicación potencial se requiere describir explícitamente en los patrones de manejo de los verbos de los tipos 4 y 5. Sin su descripción estaría incompleta la relación con las valencias semánticas. Para los casos de duplicación, su descripción es necesaria para juntarlas en el nivel semántico.
Todas las valencias semánticas son necesarias y suficientes, y el papel que cada una de ellas desempeña está implicado directamente por la definición lexicográfica del lexema correspondiente. La situación con las valencias sintácticas es mucho más complicada y no siempre existe una correspondencia de uno a uno entre valencias sintácticas y semánticas. Se presentan los siguientes casos:
1. Estado incompleto en el nivel sintáctico. Frecuentemente las valencias semánticas no se reflejan en un texto dado, aunque sea totalmente gramatical.2. Correspondencia desigual entre valencias sintácticas y semánticas:
· Dos valencias semánticas pueden implementarse en una valencia sintáctica común.
· Una valencia semántica puede implementarse en dos valencias sintácticas que concurren en un texto.
3. El mapeo de valencias semánticas a sintácticas puede sujetarse a corrimientos y a permutaciones, específicos.
Estado incompleto en el nivel sintáctico
El estado incompleto en el nivel sintáctico se restablece fácilmente (si se necesita) en el cerebro humano, y usualmente ni se menciona. Como ya vimos, existen las valencias sintácticas obligatorias, pero pueden no cubrir todas las valencias. Por ejemplo, si un hablante quiere informar a alguien, de una compra, pero para él son irrelevantes el vendedor y el precio, en la comunicación que se lleva a cabo, el hablante incluirá solamente en su expresión palabras correspondientes al comprador y a la compra. Las valencias semánticas del vendedor y el precio no las realiza sintácticamente, por ejemplo: Javier compró un libro.
Es muy frecuente que no aparezcan en una oración todas las realizaciones sintácticas de las valencias del verbo, entonces se pueden ordenar las valencias semánticas de las palabras por la importancia de sus valencias sintácticas. El orden comienza entonces con las valencias absolutamente obligatorias.
La ocurrencia de valencias para algunas palabras no puede describirse mediante leyes simples, además una tendencia válida para un lenguaje no es verdadera para otro. Por ejemplo, en inglés se puede decir It depends, y en español Depende, cuando una situación depende de algunas circunstancias que se describirán posteriormente. En cambio, en ruso la oración equivalente a esta última es imposible. Esto significa que la segunda valencia sintáctica es optativa para este verbo en inglés y en español, pero no en ruso. Por lo que la obligatoriedad de valencias sintácticas es una cuestión particular de un lexema específico en un lenguaje específico.
Correspondencia desigual entre valencias sintácticas y semánticas
La correspondencia desigual entre valencias sintácticas y semánticas, la dividimos en dos casos:
1. Dos valencias semánticas pueden implementarse en una valencia sintáctica común, por lo que el número explícito de valencias sintácticas puede ser menor en el nivel semántico. Por ejemplo, el verbo discutir:
· Los profesores discutieron con los funcionarios del Ministerio.
· Los profesores discutieron.
En estas dos frases se observa que una valencia ausente se realiza implícitamente en la segunda oración. En la primera oración, las dos valencias sintácticas que corresponden a las valencias semánticas separadas: ¿quién está replicando? y ¿con quién? Mientras que en la segunda frase, la valencia ¿con quién? está explícitamente ausente. Pero la situación difiere bastante del estado incompleto considerado anteriormente. De hecho, la valencia aparentemente ausente está realizada implícitamente también en la segunda valencia pero como una sobrecarga del sustantivo expresado en la primera valencia. Los profesores replican uno con otro, es decir, entre ellos, así que ambas valencias están presentes, una de ellas en esta forma tan particular.
En el caso del verbo discutir, el sentido mismo de por sí implica más de un participante; sin embargo también puede estar presente este fenómeno en el verbo hablar:
Los profesores hablan con los funcionarios del Ministerio.
· Los profesores hablan.
Aunque en la segunda frase, considerar que los profesores hablan entre ellos, sólo está relacionado al sentido de conversar y no al de pronunciar sonidos.
En español tanto como en otros lenguajes, existen varios verbos relacionados con información y actividades de comportamiento, recíprocas. La ausencia de la correspondiente valencia sintáctica se trata como la equivalencia entre el actuante faltante y el primero. El patrón de manejo para esos verbos se complica ya que se requiere adicionar una fórmula condicional especial.
IF (3 = Æ) & (1 = (N, Mult)) THEN (3 Ü 1)
Esta condición tiene la siguiente interpretación: si el tercer actuante se omite en el texto, y el primer actuante es un sustantivo con la propiedad Mult, es decir, es plural o expresa una multitud (grupo), entonces el tercer actuante se establece igual al primero. Esta condición involucra considerar a la tercera valencia como obligatoria.
2. Una valencia semántica puede implementarse en dos valencias sintácticas que concurren en un texto.
Un ejemplo de este caso corresponde al fenómeno presentado en la sección 2.6, donde se repiten valencias sintácticas que deben concentrarse en un sólo representativo de la correspondiente valencia semántica.
Mapeo de valencias semánticas a sintácticas
El tercer y último caso corresponde al mapeo de valencias semánticas a sintácticas, que puede sujetarse a corrimientos y permutaciones, específicos. Cada corrimiento o permutación implica una nueva versión de los PM para el lexema predicativo. Presentamos primero un ejemplo de corrimientos y después uno para permutaciones.
Corrimientos
El ejemplo bien conocido del verbo quebrar (sección 2.1), considerado como ejemplo clásico de roles temáticos, lo consideramos ahora para explicar los corrimientos. La concepción común de quebrar puede explicarse mediante la siguiente definición: Person X split into two or more pieces a thing Y with instrument Z, a esta descripción corresponde la frase Juan quebró la ventana con el martillo. El patrón de manejo considerará entonces las valencias ¿quién quiebra?, ¿qué quiebra? y ¿con qué quiebra?
La frase El martillo quebró la ventana, contiene entonces un corrimiento metafórico de valencias, la valencia Z se vuelve la primera valencia sintáctica y desaparece la valencia X. la valencia Y sigue siendo la segunda valencia sintáctica. Así que se puede introducir este último patrón de manejo como
quebrar1
object Z divides into two or more pieces an object Y.
1 = Z; qué?
1.1 N
2 = Y! qué?
2.1 N
Y en base a este patrón de manejo definir el homónimo:
quebrar2
Person X causes Z quebrar1 Y.
1 = X; quién?
1.1 N
3 = Z; con qué?
3.1 con N
De esta forma quebrar2 está en acuerdo total con la descripción de quebrar1. La mejor aproximación sería la interdependencia de homónimos. La aproximación con dos homónimos parece preferible para los lingüistas.
Permutaciones
Las permutaciones consideradas de valencias ocurren porque el sentido del verbo es recíproco o porque la realización sintáctica las permite.
El primer caso se presenta con algunos verbos cuyo sentido permite que sean posibles las permutaciones. Por ejemplo, con los verbos contrastar y rimar. Sus valencias pueden intercambiarse sin mayor problema, y sus realizaciones sintácticas son iguales, no hay diferencia.
La sequedad del campo contrasta con la vegetación del jardín.
La vegetación del jardín contrasta con la sequedad del campo.
“Sala” rima con “pala”.
“Pala” rima con “sala”.
En los ejemplos anteriores no se requiere diferenciar valencias porque son iguales. La comparación de los siguientes ejemplos para el verbo abundar, indica que se requiere crear una definición semántica para cada realización.
El río abunda en peces
Los peces abundan en el río.
En ambos casos se presenta algo como: espacio X contiene una gran cantidad de objetos Y. Pero comparando con las frases anteriores, las dos posibles alternativas de los patrones de manejo tienen evidentemente valencias permutadas, una contra otra.
La primera alternativa, de un patrón de manejo, correspondiendo al primer ejemplo para abundar es:
1 = X; cosa que contiene?
1.1. (N, Loc) % el río ~ / el bosque ~
2 = Y! de qué / de quién?
2.1 de (N, Mult) % ~ de frutas / de gente / de peces
2.2 en (N, Mult) % ~ en frutas / en gente / en peces
La etiqueta Loc se asigna a un sustantivo con propiedad de espacio. La etiqueta Mult significa el sustantivo en plural (como flores, bosques, peces, ideas) o que tiene el significado de colección (como gente).
La segunda alternativa de un PM, correspondiendo al segundo ejemplo para abundar es:
1 = X; qué es contenido?
1.1. (N, Mult) % los peces ~
2 = Y! dónde?
en (N, Loc) % ~ en el río
La situación puede describirse entonces a través de dos verbos homónimos. De estos ejemplos se infiere que la aplicación lingüística requiere la descripción completa de todas las posibles opciones.
2.9 Ejemplos de complicaciones de patrones de manejo para verbos del español
Los actuantes deben tomarse en una cantidad necesaria y suficiente. Pero las valencias no son entidades predeterminadas y aún en palabras sinónimas pueden diferir en su significado y número. Por lo que la descripción de algunos patrones se vuelve complicada al tratar de establecer cuáles son las valencias necesarias y suficientes.
La descripción de cuantos actuantes están implicados en el lexema está relacionado a su sentido pero esto no quiere decir que los grupos de verbos con significado semejante tengan el mismo número de actuantes. Por ejemplo los verbos decir y contar que tienen un sentido similar, tienen diferente número de valencias, entre los distintos sentidos presentamos los siguientes:
decir1 Alguien X dice algo Y a alguien Z sobre algo o alguien W
Por ejemplo: Juan dijo cosas horribles a María del profesor.
contar1 Alguien X cuenta algo Y a alguien Z
Por ejemplo: Juan contó una historia a sus alumnos.
Las valencias semánticas no están predeterminadas y difieren aún para lexemas sinónimos. Por lo que el marcado de valencias semánticas requiere un trabajo manual. Los verbos decir y contar, que tienen un sentido similar pero presentan diferente número de valencias. Las oraciones con decir pueden contener la frase referente al tema (sobre algo o alguien), mientras que las oraciones para contar rara vez la contienen.
Por ejemplo, la definición para el verbo español acusar1 podría empezar con X acusa a Y de Z, y a partir de ella tratar de explicar la situación con palabras adecuadas que reflejen todas las situaciones. Los tres actuantes involucrados son las valencias semánticas necesarias y suficientes.
Pueden implicarse otros vínculos, como razonamiento, tiempo y lugar. Por ejemplo: Juan acusa a María en base a pruebas irrefutables, Juan acusó a María en el mes de mayo o Juan acusa a María en los tribunales federales. Sin embargo, ninguna de estas circunstancias es obligatoria para distinguir entre acusar1, y otros verbos con sentido similar, como culpar, condenar, imputar, etc. por lo que se comprueba que las valencias descritas son las necesarias y suficientes.
La definición del número de valencias puede complicarse. Existen verbos para los cuales es complicado determinar el número exacto de valencias. Por ejemplo, el verbo enviar se emplea frecuentemente con objetos de información (cartas, mensajes, archivos, etc.), los cuales se envían a través de una oficina de correos, un transmisor, un canal de comunicación, etc. Así que, con este sentido, es válido asignar al verbo enviar cuatro valencias: ¿quién o qué envía?, ¿qué se envía?, ¿adónde se envía?, ¿vía que canal? Entonces, todas las representaciones semánticas de los textos que incluyen el verbo enviar tendrían la valencia de “canal”, independientemente de su realización sintáctica en el texto.
Sin embargo al considerar la frase Arturo envió a Victor a traer las pizzas, la segunda valencia ¿qué se envía? incluye ahora una persona, y en este caso, la cuarta valencia ¿vía que canal?, es dudosa. Por lo tanto se vuelve inconsistente la consideración inicial de valencias.
Por lo que se consideran, inicialmente, dos posibilidades para resolver esa inconsistencia:
Dividir el verbo enviar en dos homónimos, enviar1 y enviar2, el primero sería para los objetos de información y el segundo para personas, con un sentido relacionado a “mandar” o “dar órdenes”. Estos dos homónimos tendrían diferente número de valencias. El verbo enviar1 tendría la cuarta valencia, y enviar2 sólo tres valencias.
Dejar el verbo como una sola entidad, con sólo tres valencias, sin reflejar el canal en la definición lexicográfica. Entonces, toda la información no considerada es adicional y se trataría como circunstancial.
A continuación presentamos los patrones de manejo correspondientes. En el primer caso serían dos homónimos:
enviar1
Person X send thing Y to entity Z through medium W
1 = X; quién?
1.1 N(an) %Victor~
2 = Y!; qué?
2.1 N %~un paquete
3 = Z; a quién?
3.1 a N(an) % a Arturo
4 = W; vía qué?
4.1 por N(an) % por mensajería internacional
enviar2
Person X send person or thing Y to make (if Y=person) or receive (if Y = thing) action Z.
1 = X; quién?
1.1 N(an) %Victor~
2 = Y!; qué? o a quién?
2.1 N %~sus camisas
2.2 a N(an) %~a Arturo
3 = Z; a qué?
3.1 a V_INF %~ a bañar
%~ a planchar
Se observa que este último patrón podría separarse, a su vez, en dos homónimos enviar2 y enviar3, para separar la disyuntiva de hacer o recibir la acción. De esta forma, enviar2 correspondería a la valencia Y para una persona, y enviar3 corresponde a la valencia Y para cosas.
En el segundo caso se consideró un solo patrón:
enviar
Person X send thing or person Y to entity or action Z
1 = X; quién?
1.1 N(an) %Victor~
2 = Y!; qué o quién?
2.1 N %~unas camisas / ~unas cartas
2.2 a N(an) %~a Arturo
3 = Z; a quién? o a qué?
3.1 a N(an) % a Arturo
3.2 a V_INF) % a planchar
En el enfoque de constituyentes hay un desarrollo particular para este caso. En la GB se consideró que todo verbo debe tener un sujeto aún si se trata de la forma infinitiva. En la frase Victor mandó a Arturo a traer unas pizzas y siguiendo a la GB, Arturo es el sujeto de traer y al mismo tiempo objeto directo de enviar. En la frase Arturo mandó sus camisas a planchar y siguiendo nuevamente a la GB, [Lamiroy, 94] considera que ambos verbos comparten el objeto directo: sus camisas.
En la gramática española, [Seco, 72] considera que cuando los verbos aparecen en infinitivo, no expresan por sí mismos el tiempo en que ocurre la acción sino que se deduce del tiempo de la oración, y en cuanto a los sujetos, las frases con verbos en infinitivo presentan los siguientes casos:
· El sujeto es indeterminado. Ejemplo: querer es poder.
· Es sujeto (infinito sustantivizado). Ejemplo: el murmurar de las fuentes, el comer bien.
· El sujeto es el mismo sujeto del verbo principal. Ejemplo: pelaremos hasta morir, deseo pasar unas vacaciones muy tranquilas.
· El sujeto del infinitivo es distinto del sujeto del verbo principal. Ejemplo: Por no saber yo nada me sorprendieron. Te prohibo hablar.
Por otra parte, [Gili, 61] indica que cuando el infinitivo es complemento directo se construye sin preposición, por ejemplo oigo tocar las cornetas. Con verbos de mandato no hay dificultad porque el infinitivo es la cosa mandada y su sujeto es un claro complemento indirecto; pero con verbos de percepción la cuestión resulta difícil. El autor considera que mirada la cuestión psicológicamente, el infinitivo y su sujeto forman una representación conjunta que actúa en su totalidad como complemento directo del verbo principal. Cuando el infinitivo es complemento indirecto lleva preposición. Realmente, en los textos, las valencias semánticas relevantes encuentran su expresión explícita en las palabras correspondientes conectadas (dependientes sintácticamente) con la palabra predicativa, directamente o a través de preposiciones.
Estos estudios muestran los diferentes aspectos que se deben considerar con los verbos en infinitivo; su construcción sintáctica y su información léxica. Apoyan la descripción individual de las variaciones sintácticas del verbo específico para el análisis sintáctico así como el análisis de la construcción sintáctica en la que aparecen. En los patrones de manejo, se determinan las valencias semánticas y se describe esas posibilidades de realización con infinitivo. En los ejemplos anteriores, planchar y traer son acciones, ordenadas por el sujeto de enviar y ejecutadas o recibidas por el tipo de objeto directo que emplea el verbo enviar.
Así que la MTT a través de los patrones de manejo nos permite escoger para palabras predicativas cualquier número de valencias, pero con reservas acerca de dominios semánticos restringidos y con advertencias acerca de posibles efectos y contradicciones cuando se procesan textos sin restricciones. Las implicaciones lexicográficas se detallan en la sección 2.10
Subcategorización
Los métodos tradicionales más empleados para describir el nivel sintáctico de los lenguajes naturales son los basados en las gramáticas generativas, y el español no es una excepción. En esta aproximación, la descripción de las características de las valencias para los lexemas se realiza, principalmente para los verbos. Los actuantes se describen en ellas desde un punto de vista puramente sintáctico (denominados complementos). Las valencias se denominan características sintácticas. La información de la estructura de los complementos de un verbo se conoce como subcategorización. Cada subcategoría del verbo tiene su propio conjunto de complementos que usualmente van en un orden lineal predeterminado.
A continuación presentamos ejemplos de subcategorización para el español, para una selección de verbos.
· ver tiene una subcategoría grupo nominal (GN), por ejemplo: Beto vio una araña.
· dar tiene la subcategoría GN seguido de GP, por ejemplo Beto dió una carta a su novia y la permutación GP GN, por ejemplo Beto le dió a su novia una carta.
· poner también tiene la subcategoría GN seguido de GP, el grupo preposicional se realiza mediante diferentes preposiciones: en, sobre, bajo, etc. Por ejemplo: Beto puso los libros en el librero. En este ejemplo el grupo preposicional es introducido por la preposición en. Notamos que aunque se especifique esta construcción (en GN) existen otros grupos preposicionales con la misma preposición como: en la mañana, que no corresponde a la realización de la misma valencia. Con la aproximación de subcategoría se pierde esta información para el nivel semántico.
· Llover no tiene subcategoría, puesto que es intransitivo y no permite complementos, se ve natural para un verbo impersonal.
· acusar tiene la subcategoría GN de_INF (entre otras), y el objeto directo está conectado mediante la preposición a. Por ejemplo Beto acusó a sus compañeros de negar su ayuda.
Por supuesto, muchos verbos pueden asignar varias subcategorías. Por ejemplo, el verbo decir asigna: GN, que_O, a GN seguido de GN. Por ejemplo: dijo unas palabras de aliento, dijo que el director vendrá pronto, dijo a sus compañeros unas palabras de aliento. Desde el punto de vista de la subcategorización, también existen otros verbos cuyas estructuras de complementos en algunas oraciones son similares a esta última subcategoría. Por ejemplo: aconsejó a su alumna (a GN) una vez más (GN), ya que no se distingue que el último grupo nominal representa una circunstancia, no directamente relacionada con el significado del verbo.
Los marcos de subcategorización se emplean desde hace mucho tiempo [Boguraev et al, 87], ya que son útiles para restringir el número de análisis generados por el analizador sintáctico, para la generación automática de texto y para aprendizaje de lenguajes. Debido a esta utilidad muchos esfuerzos manuales se han aplicado a su compilación para tareas de procesamiento lingüístico de textos por computadora, principalmente para el inglés: ALVEY [Boguraev et al, 87] y COMLEX [Grishman et al, 94].
La subcategorización se describe en diccionarios modernos como COMLEX [Grishman et al, 94], mediante la descripción de los constituyentes que lo forman, principalmente, y algunas otras características. Para el desarrollo de este diccionario emplearon las clasificaciones verbales de diversos diccionarios. Para ilustrar la estructura de las entradas presentamos tres ejemplos:
(verb :orth “accept”:subc ((np)
(that-s )
(np-as-np)))
(noun :orth “acceptance”)
(verb :orth “abstain”:subc ((intrans)
(pp :val (“from”))
(p-ing-sc:pval (“from”))))
El primer símbolo (verb, noun) marca la categoría gramatical o POS. La característica orth describe la forma de la palabra. Las palabras para las cuales se consideran sus complementos tienen la característica subc. Por ejemplo, para el verbo abstain se definen tres tipos de subcategorización, el nombre (pp, p-ing-sc) corresponde al nombre del marco. Se observa la consideración de que algunos verbos pueden pertenecer a más de un tipo de subcategorización.
Cada tipo de complemento se define formalmente mediante un marco. Cada complemento se designa por los nombres de sus constituyentes, junto con unas pocas marcas para indicar casos especiales como el fenómeno de control. El marco incluye la estructura de constituyentes (cs), la estructura gramatical (gs), una o más características (features) y uno o más ejemplos (ex). Por ejemplo:
(vp-frame s :cs ((s 2 : that-comp optional))
:gs (:subject 1 : comp 2)
: ex “they thought (that) he was always late”)
Donde los elementos de la estructura de constituyentes están indexados. En los campos de la estructura gramatical se indican estos índices, por ejemplo, el índice “1” se refiere al sujeto superficial del verbo. La “s” significa que es de tipo oración. Entre las características que se pueden definir y que en este ejemplo no están presentes, se encuentran: sujeto raising, sujeto control, etc.
De los ejemplos anteriores se ve que en los marcos de subcategorización, generalmente, el orden de los complementos es fijo y todos los complementos aparecen después del verbo. Por ejemplo, para el verbo abandon, un marco de subcategorización es un grupo nominal seguido de una frase preposicional introducida por la preposición to, es decir, NP PP(to). La permutación PP(to) NP puede existir, solamente si se expresa explícitamente con otro marco. Esta descripción es muy útil en inglés por su orden de palabras más estricto. En el español, este orden es más libre, por ejemplo, la frase expresó(V) sus ideas (NP) con palabras sencillas(PP) puede expresarse de diferentes maneras, por ejemplo: expresó(V) con palabras sencillas(PP) sus ideas(NP) o con palabras sencillas(PP) expresó(V) sus ideas (NP) son igualmente posibles y esas permutaciones son muy usuales.
Como presentamos en el capítulo primero, la información de subcategorización ha sido considerada en la mayoría de los formalismos gramaticales modernos. Inclusive se han llevado a cabo esfuerzos para estandarizar la información de subcategorización, principalmente por [EAGLES, 96], pero realmente la información de subcategorización en los diccionarios prácticos se ha definido considerando el aspecto teórico del formalismo considerado o las necesidades requeridas en la aplicación para la cual fueron construidos, o ambos.
Los diccionarios prácticos para el procesamiento lingüístico de textos por computadora pueden ser más prescriptivos o menos, dependiendo de sus bases teóricas (formalismos en los que se basan) o del propósito de aplicación. Por ejemplo, considerando los diccionarios ILCLEX [Vanocchi et al, 94], ACQUILEX [Sanfilippo, 93], COMLEX [Grishman et al, 94] y LDOCE [Procter, 87] se observa lo siguiente:
1. El número de argumentos sólo se codifica explícitamente en ILCLEX (mediante una característica con valor numérico), en los demás se debe inferir.
2. La categoría sintáctica se indica en todos los diccionarios explícitamente, salvo en ACQUILEX. Éste sigue el formalismo de gramáticas categoriales, que especifica categorías simples y complejas, por lo que la categoría sintáctica se infiere.
3. Todos especifican requerimientos léxicos, por ejemplo la selección de una preposición particular para introducir complementos, aunque lo hacen con diferentes grados de granularidad.
4. La variación de marcos aparece explícitamente en todos, salvo en LDOCE, dónde se infiere. Pero varían considerablemente en la forma de codificarla y en el rango en que consideran este fenómeno. Por ejemplo, la opcionalidad de argumentos no siempre se trata como variación.
5. La estructura de roles semánticos sólo se marca en ACQUILEX, siguiendo la expresión de relaciones temáticas de [Dowty, 91].
Usualmente en los marcos de subcategorización el orden de los complementos es fijo y todos los complementos aparecen después del verbo. Esta descripción es especialmente útil para el inglés por su orden de palabras más estricto. En español el orden de palabras es más libre, aunque no totalmente, para lenguajes con un orden libre se estudian otras descripciones [Rambow & Joshi, 92], [Bozsahin, 98]. Aún cuando [EAGLES, 96] considera varias lenguas europeas (el español entre ellas), en su trabajo de recomendaciones de normalización, no consideran fundamental la información del orden lineal de los complementos. Sin embargo, explícitamente dicen que en algunas lenguas las restricciones en la precedencia lineal pueden ser completamente necesarias.
Presentamos los marcos de subcategorización para el verbo acusar. El ejemplo considera las ocurrencias con más del 10% en un corpus.

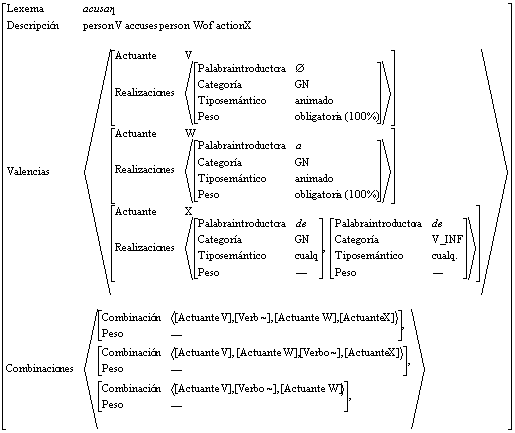
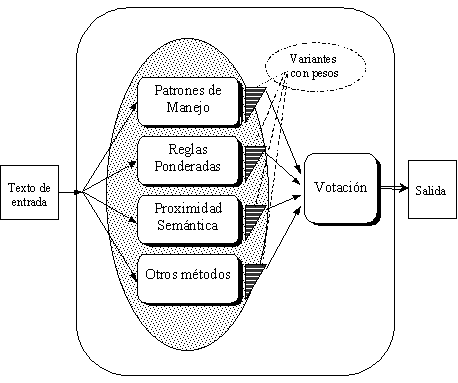

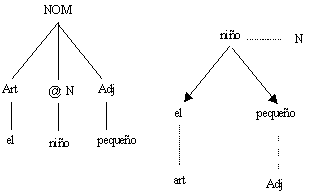
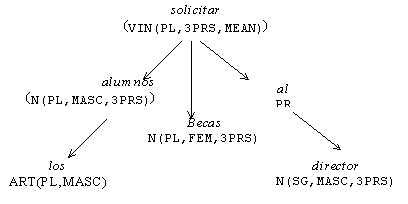
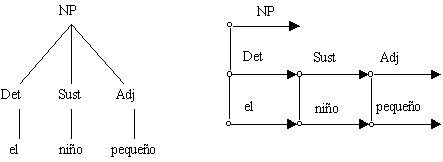
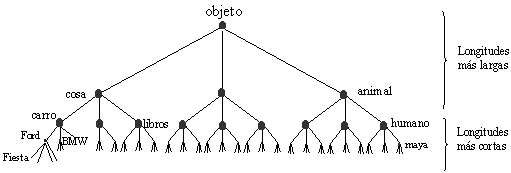
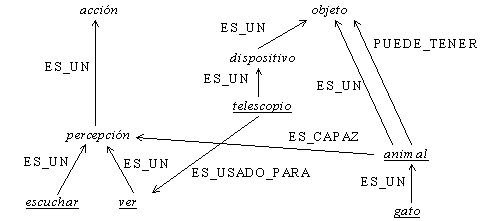
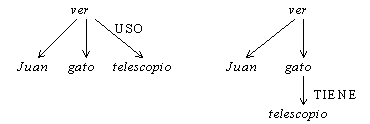
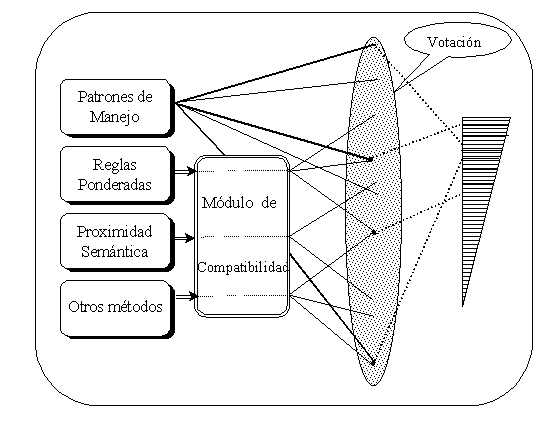
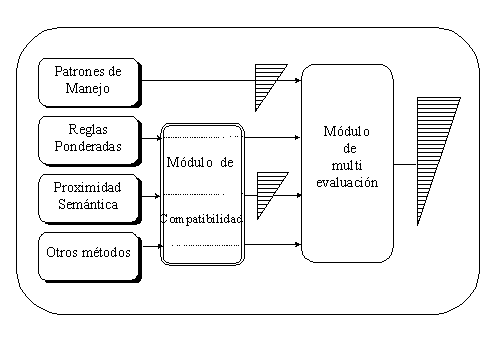
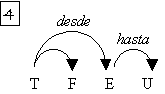
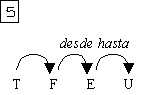
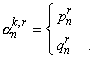

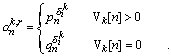
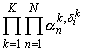
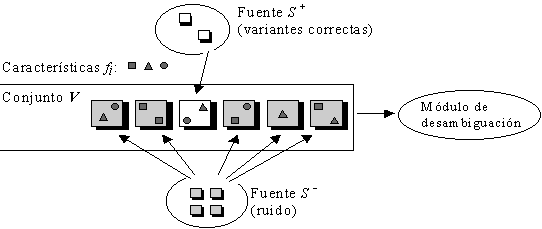
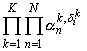
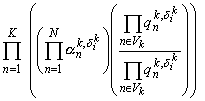
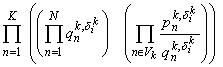
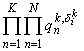 es la matriz llena de
probabilidades q (de no selección de
combinaciones). En esta matriz, las probabilidades q+ están en la fila correspondiente a la variante
correcta y las probabilidades q
es la matriz llena de
probabilidades q (de no selección de
combinaciones). En esta matriz, las probabilidades q+ están en la fila correspondiente a la variante
correcta y las probabilidades q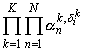
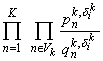 (8)
(8)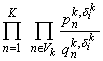 =
= 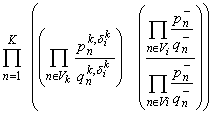 =
= 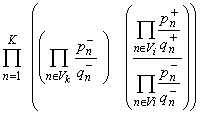
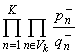 corresponde a todas
las combinaciones que no están presentes en la variante correcta, así que lo
podemos eliminar con cierta pérdida:
corresponde a todas
las combinaciones que no están presentes en la variante correcta, así que lo
podemos eliminar con cierta pérdida: 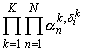
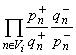 =
= 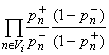 (9)
(9)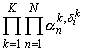
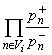 (10)
(10)