A.F. Gelbukh. Using a semantic network for lexical and syntactical disambiguation. Proc. CIC-97, Nuevas Aplicaciones e Innovaciones Tecnológicas en Computación, Simposium Internacional de Computación, 12-14, 1997, CIC, IPN, Mexico City, Mexico, pp. 352 - 366.
Using a Semantic Network
for Lexical and Syntactical
Disambiguation
Alexander F. Gelbukh
Natural Language
Processing Laboratory,
Centro de Investigación en Computación,
Instituto Politécnico Nacional,
Mexico D.F.
gelbukh(?)pollux.cenac.ipn.mx,
gelbukh(?)micron.msk.ru
Abstract
A procedure is proposed for determining the measure of “nearness” of two word senses in a semantic network dictionary such as FACTOTUM® SemNet. Applications of this procedure are discussed in detail for lexical, syntactical, and referential disambiguation in natural language processing, as well as in text generation in frame of machine translation. A simplified version of the same procedure is used for automatic translation of the semantic network itself into other languages, that simplifies creation and maintenance of semantic network dictionaries for these languages, as well as makes the described methods available for processing of texts in languages other than English.
1. Introduction
This article describes an ongoing research that is being conducted in the Natural Language Laboratory, CIC, IPN, Mexico D.F. The research is in an early stage so the results are very preliminary.
The most unpleasant problem that nearly any algorithm dealing with the natural language faces is the curse of ambiguity. Be it just one word, or a phrase, or a text, there always are several possible interpretations of what it means or what structure it has. We could claim that ambiguity resolution is the most important problem of natural language processing. In much larger number of cases than it seems at the first glance, to resolve the ambiguity complicated reasoning or deep knowledge is needed, often of semantic, pragmatic, or extralinguistic nature.
There is a large number of researches on ambiguity resolution that employ marked up text corpora, dictionaries [1], thesauri [2], semantic networks [3, 4], or a combination of lexical information sources [5]. However the problem is far from being completely solved up to the date.
Ideally, ambiguity resolution might be just a side effect of some kind of “understanding,” by which we would mean construction of some detailed model of the whole situation described in the text, and embedding it in one’s whole world model based on the experience of life or other texts read. However, such “understanding” is too demanding computationally to be considered now. What is more, it seems that such a way is too demanding even for human brain.
A less demanding idea is to use some pre-constructed pieces of “typical” situations and first of all to check the ambiguous constructions against them, addressing to a deeper analysis only when a serious contradiction arises in the reading process. Such pre-constructed pieces of information can be of different nature, such as syntagmatic, semantic, pragmatic, etc.
For example, syntagmatic patterns could be represented by frequently used or “meaningful” word combinations, such as take a bus, take a pen, as opposed to *take weather [6]. Such a simplified set of syntagmatic patterns can be used (and possibly is used by a human) in syntactic analysis instead of expensive combinatory dictionaries like ones developed in frame of the Meaning Û Text theory [7].
Similarly, instead of a computationally demanding reasoning, a set of simplified “typical” semantic patterns can be used for disambiguation. Such semantic patters could describe some atomic pieces of typical situations involving the words of the text. One of the form of representation of such knowledge is a semantic network.
2. Structure of a semantic network
In this research we use the FACTOTUM® SemNet semantic network dictionary [8] kindly made available to us by Dr. P.Cassidy of MICRA, Inc. It is English, but below we describe some idea how to use it for other languages, our target language being Spanish[1].
Logically FACTOTUM® SemNet dictionary is a set of so called relationships between pairs (and in rare cases between sets) of concepts.
A concept is usually a word, e.g., book, or a word combination, e.g., address book, referring to a specific thing or idea. If the word has several meanings, they are included in the dictionary at different locations and are marked with different numbers, e.g., bill1, note, banknote, versus bill2, law, legislation, or bill3, ax, knife. All the senses of any word, even related, have different numbers, while they can be connected explicitly by relationships. Thus one textual word can represent different concepts.
Similarly, one concept can be represented by several words. In this case they are considered synonymous in these particular meanings, and are listed all to represent and disambiguate the concept, as it was shown above, e.g., bill1, note, banknote. Thus generally by a concept we always mean a group of synonymous word senses. However for convenience we name the concepts with just one of the words of the group.
Relationships are used to connect a pair, or rarely more, concepts. They are of different types, like IS_A, USES, CAUSES, etc. A relationship can be also viewed as a simplest affirmative statement expressing a “typical” fact, e.g., computer IS_A equipment, explosion CAUSES damage. There are some properties of the relationships, like MAYBE, USUALLY, RARELY, etc., e.g., seeing MAYBE USES telescope, i.e., telescope IS_USED_FOR seeing. As it is seen in the previous example, for human convenience there are different ways to express the same fact in this semantic network, though they can be formally converted to a common internal representation. A fragment of such a network is shown on the Fig. 1.
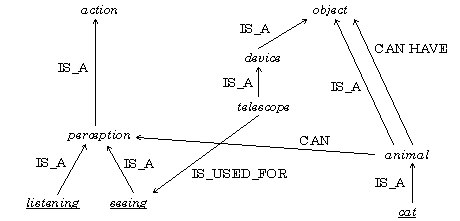
Fig. 1. Semantic network.
From this example, we can see that a telescope is a tool to see, an animal can have an object, etc.
In the human-editable form of the dictionary the most extensive set of relationships, namely most of the IS_A relationships, are represented implicitly by just placing the concepts in hierarchical order in the dictionary. This does not imply that a concept may not be a subtype of several concepts, for example, a girl IS_A child and IS_A female, in this case one of the relationships is indicated in the dictionary explicitly.
Clearly, there are many possible relationships that can be easily inferred by some general rules from other relationships; e.g., transitive relationships like IS_A and IS_PART_OF: if a IS_PART_OF b and b IS_PART_OF c, then a IS_PART_OF c. In such cases only some of the relationships are explicitly included in the dictionary, to keep its size maintainable.
There are many other rules of inference involving particular relationships or groups of relationships. E.g., the most obvious one is that if a IS_A b and b R c, then a R c, where R is any relationship. In some semantic networks, such inheritance of characteristics from higher categories is defeasible, i.e., it may be blocked explicitly by a special notation in the definition of a concept, or it may be canceled where contradictory information is inherited from more than one higher node.
3. Paths in the semantic network
Since some of the relationships are present in the network only implicitly and can be inferred by application of rules, a problem arises of generating all the relationships, including the implicit ones, between, say, two given words. The problem can be formulated as enumerating all the network paths with some condition, that lead from one given word to another. By a path we mean a chain of relationships, with the beginning of the first one and the end of the last one being the two given words.
What is more, in some cases important commonality between words may not be expressed in terms of any existing named relationship. E.g., on Fig. 1, it can be seen that a cat CAN HAVE something that IS_USED_FOR seeing. There is no named relationship expressing this fact, so we have to represent it by just a path in the network.
Another reason to use paths is that some rules of inference may have fuzzy character, being rather common-sense observations. At least this may imply that application of too many rules can make the result less reliable. We can express this lost of reliability, in some cases, by adding the MAYBE attribute to the resulting inferred relationship.
In general we need to weight the resulting relationships, so that even too long sequence of IS_A relationships makes the resulting relationship less reliable. E.g., on Fig. 1, it is true but less reliable that cat CAN HAVE telescope, due to too many applications of IS_A transitivity rule. The fuzzy character of the inference rules is quite obvious when it comes to such relationships as IS_SIMILAR_TO, which is “to some degree” transitive.
This measure of “reliability” of a generated relationship or in general the measure of “nearness” of two words in the network, can be important for some applications described below. We could call such a measure the “weighted length” of a path. It gives the quantitative estimation of how closely are related the two given words, while the path itself gives the qualitative estimation of exactly how the two given words are related.
Naturally the curse of ambiguity manifests itself in the full degree in the task of finding such paths. There is virtually infinite number of paths in the network connecting the two given words, and we cannot say in advance which of them will be useful in a particular case for a particular application. We can guess that shorter paths tend to be more useful, but this is not a firm rule.
3.1. Problem statement
Thus we can consider such a problem, which, as it will be shown below, has interesting and useful applications:
Enumerate the paths in the network between two given nodes, generally starting from shorter ones.
It is supposed that the calling routine will at some moment stop the enumerating process, or some kind of time-out will be applied to prevent the algorithm from infinite work, like a restriction on the number of paths, or on their weighted lengths. Also some other restrictions may be imposed on the desirable paths, e.g., not to contain a particular relationship.
Though the problem is well formulated and has clear mathematical meaning, we don’t know of any existing good algorithm to solve this problem. It is very similar to well-known problems of logic and optimization, but there are some differences in goals and conditions with the classical problems of optimization, shown in Table 1.
|
Classical Optimization |
Our problem |
|
Only one path is needed. |
Paths must be enumerated until the caller “accepts” one. |
|
The very best path must be found. |
The better paths should go first, but not necessarily the very best is to go first. |
|
The length of a path is a mere sum of the lengths, or weights, of the individual links. |
The weighted length is calculated according to the fuzzy rules of combination of the relationships. |
|
Time and memory requirements are not critical. |
Since this is a part of a text understanding procedure and many pairs of words are tried, time, and in part memory requirements, are very critical. |
|
No previously prepared data is usually used. |
Some data can be prepared in advance, before the first request is processed. |
Table 1. Comparison of the proposed problem with the classical one.
By better paths we mean the ones with less “weighted length”, that usually means ones that contain fewer links. In fact this measure is computed as a combination of their weights, with application or taking into account the rules of inference. For example, a chain of five IS_A relationships may be considered “shorter” than a chain of two IS_SIMILAR_TO relationships. In general such an estimation is a complex problem by itself, and we will not describe it here in more detail.
Note that the measure of length used by the algorithm can differ from the measure of length used by the caller, the latter being probably calculated or refined by the caller itself.
This difference arises from our intention to separate the information internal to the semantic network from the information used in various applications described below, and to provide a general procedure (probably implemented as a separate module) that permits the caller to treat the semantic network as a black box. Though, some minimal adjustments of the procedure will anyway be necessary for some applications; they are discussed below in the sections on the corresponding applications.
Thus we presume that the algorithm should find the paths just good in some general meaning, and the caller will check if the path is really good for it, though the “generally good” paths should be usually good enough for the caller.
This implies that the algorithm should not even try to absolutely optimize the enumerating process, since anyway chances are little that the very best in general sense path will be the very best for the caller, and we expect usually it will not. This changes the whole approach to the algorithm as compared with the classical optimization problems.
3.2. Possible algorithms
It is not the main goal of this article to propose a mathematically refined algorithm, since at the current stage of the research we are mostly interested in linguistic applications of the idea itself.
One possible simple algorithm of enumerating all the paths could be as follows. A sphere of the radius 1 is taken around each of the two starting points A and B, as the set of the ends of all the relationships that go from the given point. Then spheres of radii 2, 3, etc. are determined as the union of all the spheres of radius 1 around each point of the previous sphere, see Fig. 2. Special precautions have to be taken to prevent the algorithm from infinite loops.
When the spheres first intersect, the paths leading through the intersection point(s) can be considered the first candidates. Further increasing of the radii of the spheres will give other, generally worse, candidates.
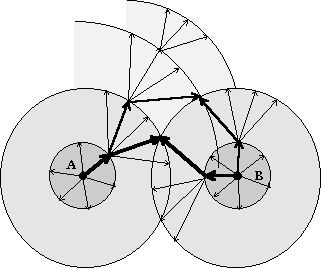
Fig. 2. Search for paths in the network.
The inference rules and the weights of different combinations of the relationships can be taken into account when the spheres are increased. The relationships are taken into account that can be inferred from the other ones. Thus, a sphere of the radius 1 could contain a whole chain of IS_A relationships, according to the weight of this chain.
Due to too high number of “dimensions” of the network, this method is good only to find short enough paths, since spheres of bigger radii will be too huge. In practice it may not be a problem if only short paths are searched for.
However if longer paths are required, an additional network of “control nodes” with pre-calculated information about their connections with each other may be used. This is similar to the idea of a cellular telephone system, see Fig. 3.
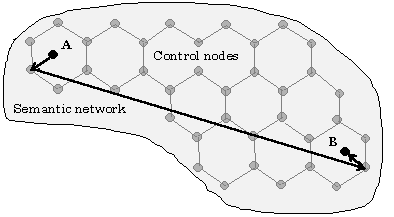
Fig. 3. The network of control nodes.
At the stage of preparation of the network, nodes are added, or existing nodes are used, at nearly equal distances from each other and not further than some threshold distance from any node in the network. The number of such control nodes should be much less than the total number of nodes in the network. The information is stored with these nodes that helps to find the paths leading from each of them to each another. To find a path from an arbitrary point A in the network to another point B, first the paths from each of these points to the nearest control node are determined using the method of increasing spheres described above, and then this path can be varied or optimized locally.
Surely other algorithms exist to find the paths in the network with the conditions mentioned above, but in this research they were not yet tried.
4. Applications
A working procedure of finding the paths in the network between the two words and measuring their “nearness” in the network, has useful applications for disambiguation in language processing.
4.1 Syntactical disambiguation
Consider an English phrase “John sees a cat with a telescope.” The phrase is syntactically ambiguous: Does it mean “John uses a telescope to see a cat” or “John sees a cat that has a telescope,” or “John sees a cat and a telescope,” or maybe “John that has a telescope sees a cat,” etc.? This ambiguity cannot be resolved using only lexical or syntactical information, since all the interpretations are quite legal syntactically. On Fig. 4, the first two of above variants are represented.
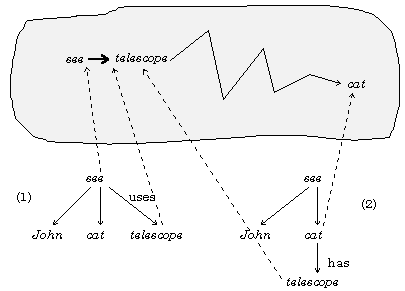
Fig. 4. Resolution of syntactical ambiguity.
The syntactical relationships in doubt are see ® telescope and cat ® telescope. But what about the semantic relationships between these words? There is a good, short path between seeing and telescope in the semantic network dictionary. What is more, the type of the relationship(s) constituting this path agrees with the supposed, namely instrumental, syntactical relationship between these words in the phrase. On the other hand, the best path between all the senses of cat and telescope, that agrees with the type of the supposed syntactical relationship, is much longer. Thus, the variant (1) should be chosen as the probable one.
Note that this of course should not prevent the linguistic processor from being able to revise this decision later if the subsequent sentences disagree with this choice.
In the simplest case, just the quantitative measure of the nearness (the weighted length of the path) can be used for comparison. However for better quality of analysis the whole path should be checked against the expected syntactical type of the relationship. E.g., in a phrase “John sees a cat with a boy” there is a short path between seeing and boy: boy CAN see, but the type of the relationship contradicts with the hypothesis that boy here is a tool to see with.
In general, we emphasize that the methods we describe should not be regarded as the ultimate solution of the problem of ambiguity. Instead, we believe that this problem must be solved by “voting” of as many different methods as possible in a particular system, and here we propose one of such “voters.”
4.2 Lexical disambiguation
Similar problems arise with the selection of a particular meaning of a word in the phrase. Sometimes they can be resolved at syntactical level, usually when the choice is made between different parts of speech, e.g., in the phrase “John tables his cards” the word tables is clearly a verb. However in many cases, especially when a word has different meanings within the same part of speech, semantic information has to be employed.
Compare, for example, the phrases “There were fruits and drinks on the table” and “The numbers were arranged in a table.” By addressing to the semantic network, it can be determined that in the first phrase the shortest path exists between other words and the sense “table as a furniture,” while in the second phrase, the shortest path leads from numbers to “table as a picture.”
It is not as clear as it is with syntactical ambiguity, with what words in the phrase to compare the given word. Since many words or word senses possibly have to be tried and the results have to be accumulated, the procedure may be computationally demanding. However, in comparison with, say, Word Expert Parser model [10], our procedure requires easier available data and better coexists with traditional text processing algorithms.
4.3 Referential disambiguation
The problem of referential disambiguation arises each time a pronoun, ellipsis, or zero subject (very common in such languages as Spanish) is used in the text. In general, at the stage of text analysis such a reference must be replaced with another word probably used somewhere in the text. Though there are linguistic considerations on selecting the candidates to fill the valence, they usually give ambiguous results if only lexical and syntactical information is considered.
However, it is possible to resolve this task into the task of lexical disambiguation. Namely, when several candidates are to be tried to fill the valence, they can be just treated as different “senses” of the pronoun in this particular context. Then the procedure described in the previous section can be applied with nearly no modifications.
4.4 Machine translation
In general text translation is quite another task than text understanding. Ideally translation should include the steps of text understanding in the source language and then text generating in the target language. If the ambiguity is resolved at the stage of analysis, and the bilingual dictionary is good enough, there should be no problems with ambiguity during text generation. However, in real life it is not the case, for both practical and theoretical reasons [11].
In practice currently some less sophisticated methods are used, working mostly at syntactical level. To our knowledge, most commercially available translation programs, such as Globalink’s Power Translator [12], distinguish the senses of the words only by a limited number of semantic classes or by storing some number of idioms. E.g., this phrase was translated from Spanish by Power Translator Professional: “El artista realiza bien el papel” Þ “The artist accomplishes well the paper” (instead of role[2]).
For the ideal scheme of translation, there must be available (1) a good disambiguating procedure in the source language, (2) a good bilingual dictionary that translates one-to-one senses to senses, not textual words to sets of words. Both conditions are very difficult to meet. For example, there might not be available a Spanish dictionary to disambiguate the two senses of the word papel.
What is more, the most elaborated up to date dictionaries, including academic dictionaries, usually provide translations of a word to several possible words in the target language, e.g.: “papel: paper; document; role; <...>” [13]. In this case even if the senses had been disambiguated in the source language, the dictionary anyway does not contain the information necessary to translate them one-to-one into words of the target language.
However with the procedure suggested in this work it becomes possible to disambiguate the words after translation in the target language. As in the previous section, we can treat the ambiguous position as a word with several “senses” and then apply the procedure of lexical disambiguation to the generated phrase in the target language.
E.g., in the example above we can notice that there is a shorter path in the English semantic network between artist and role than between artist and paper or document. This will allow to use a semantic network as a “black box” to improve the results of translation made with help of existing bilingual dictionaries, rather than to develop new sense-to-sense dictionaries, which are expensive to create and difficult to share between different systems due to their tight integration with the other modules of a linguistic processor.
4.5 Automatic translation of the semantic network
The disambiguation procedure can be applied to automatic or semi-automatic translation of the semantic network itself into other languages. Since the author has taken part in such a translation project (though the work was mainly done by hand), we are aware of all the deficiencies of the very idea of translation of a semantic network, and of low quality of the resulting dictionary [14]. However, we see at least two reasons to translate semantic networks.
First, creating a semantic network from zero is a very difficult and expensive work. If the task is tolerant to the incompleteness and minor inaccuracies, it may be more efficient to use a lower quality dictionary translated from an existing resource than to wait for a better dictionary to be created in the future.
What is more, since the semantic network contains mostly the facts about real-world objects and ideas, and in part due to commonality between the languages, most of the relationships tend to be translated correctly (though this may depend on the languages and subject area). Besides, we believe that due to the nature of the functioning of natural language, any language processing software must be tolerant enough to incomplete and inaccurate information.
Second, the linguistic resources for such languages as English, French, Japanese, etc., are maintained by many people and groups in the world, with much money spent on their development, enlargement, and refinement. It would be a waste of effort to repeat all this work in full size for each language.
Thus for groups that work on, say, Spanish language, to take advantage of the efforts spent in the world on development of English semantic networks, it is necessary not only to translate the first draft of the dictionary from English, but to be able to repeat such translation automatically as new versions of the English dictionaries become available. There is no need to mention that the existing machine translation programs designed for translation of phrases in a discourse are not appropriate to translate structured resources such as dictionaries; thus the necessity to create specialized dictionary translating software.
A detailed description of the translation procedure is beyond the scope of this article and will likely be the topic of a later paper. Here we only discuss the application of the procedure for enumerating the paths in the network between two given points, to the task of translation of the semantic network itself.
The main problem of automatic translation of a semantic network is the same: ambiguity. Each word in each its occurrence in the text of the dictionary, presumably in different senses, is translated by an ordinary bilingual dictionary to several different words of the target language.
We propose the following procedure to choose the correct variant of the translation, using the same (English in our case) semantic network. Each variant of translation of a word should be translated back to the source language. Then the distance in the source semantic network should be measured between the source word and each variant of such a reverse translation. The variant(s) of translation should be chosen, at least one of whose reverse translations is located near the source word sense in the network, i.e., there is a “short” enough path from this variant to the source word sense, see Fig. 5.
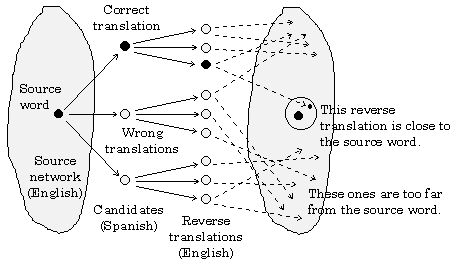
Fig. 5. Translation of a semantic network[3].
Naturally, the copy of the source word should be removed from the set of the reverse translations. Words having only one reverse translation, namely the same source word, should be treated as special cases. They should be inserted in the resulting dictionary, and if the source word had different senses, such words should be marked when automatically inserted in the dictionary and then checked by hand.
Ideally, only the words with a reverse translation within the same concept, i.e., at the zero distance from the source word, should be accepted. But in real life, a bilingual dictionary in most cases does not gives such accurate results, therefore the paths of nonzero length should be taken into account.
When searching for the paths in the network, for each textual word all its senses should be tried unless any disambiguating information is available in the bilingual dictionary, that is usually not the case.
In contrast with the procedure of enumerating the path, used for text processing, the procedure used for translation of the dictionary itself can be simplified by ignoring completely the inference rules, since in this case the meanings should be preserved much more precisely. The length of the path can be calculated as just the number of links in it. This makes implementation of the procedure for translation much more straightforward than the one for text understanding.
For better results, though, the inference rules may be used, but application of each rule should substantially increment the “weighted length” of the path. E.g., a chain of transitive relationships like IS_A should be considered long enough, whereas the procedure used for text understanding would give the length near to 1 for such a path. The choice here, as well as the choice of the thresholds described below, is made on the basis of desired compromise between the accuracy of the translation (less usage of inference, less thresholds) and the number of words that will get any translation at all (more usage of inference, more threshold).
In any case only basic relationships, such as IS_A or possibly IS_PART_OF and few others, should be allowed to appear in the paths, while such relationships as USES, etc., should be prohibited.
The choice is made in two steps. First the “weights,” i.e., the weighted lengths of the corresponding paths, of the reverse translations of each candidate are combined to calculate the “weight” of the candidate itself, and, second, the candidate(s) are chosen with the best such “weight.”
Different procedures can be used for both calculations. To combine the weights of the reverse translations for one candidate, in the simplest case a maximum (but not average) can be taken. In more sophisticated procedure, all the reverse translations worse than some threshold should be ignored, and the values for others should be accumulated.
Similarly, to choose the acceptable candidates of translation, in the simplest case only the best one should be taken for each word, or all the candidates should be accepted that are better than some threshold value. More sophisticated procedures can also be tried. For example, all candidates better than some threshold value should be accepted, all candidates worse than some threshold value should be rejected, and the best one should be chosen from those candidates whose weight fells between these two thresholds.
The resulting semantic network dictionary may be then post-edited by hand. To be able to repeat the translation as new versions of the source dictionary become available, the changes made by hand should be saved in a special protocol.
5. Conclusions
In recent years several semantic network dictionaries have become available, mostly for English language, such as MICRA’s FACTOTUM® SemNet dictionary [8, 9].
As it was shown in this work, a relatively simple procedure for determining the measure of “nearness” of two word senses in a semantic network can be used for disambiguation in a variety of important tasks of natural language processing, namely for lexical, syntactical, referential disambiguation, as well as in text generation in frame of machine translation.
Also this procedure can be used to automatically translate the semantic network dictionary itself into other languages. This makes the methods described in the work available for processing of languages other than English, and also simplifies creation and maintenance of semantic network dictionaries for these languages.
To our knowledge, the approach is new and was not considered in this form for other languages including English, despite of availability of several types of semantic network dictionaries for this language.
Acknowledgments
Dr. P.J.Cassidy of MICRA, Inc., and M.S. S.N.Galicia-Haro of CIC read the manuscript and provided me with very useful advice, discussions, and references. Lic. R.Reyes-Gonzalez and Lic. M.I.Romero-Zuñiga of CIC took part in discussions of the algorithms and implemented the first version of the program.
References
1. Alpha K. Luk, Statistical Sense Disambiguation with Relatively Small Corpora Using Dictionary Definitions // Proceedings of the 33rd Annual Meeting of the Amer. Soc. for Comp. Ling., 181-188 (1995).
2. David Yarowsky. Word-Sense Disambiguation Using Statistical Models of Roget's Categories Training on Large Corpora // Proceedings of COLING-92, pp. 454-460 (1992).
3. Voorhees, E.M. Using WordNet to disambiguate word sense for text retrieval // Proceedings of ACM SIGIR Conference, pp. 171-180 (1993).
4. Sussna, M. Word Sense disambiguation for free text indexing using a massive semantic network // Proceedings of CIKM, 1993.
5. David Yarowsky. Unsupervised Word Sense Disambiguation Rivaling Supervised Methods // Proceedings of the 33rd Annual Meeting of the Amer. Soc. for Comp. Ling., 189-196 (1995).
6. Bolshakov, I.A., P.J.Cassidy, A.F.Gelbukh. CrossLexica -- a dictionary of collocations and thesaurus of the general Russian lexicon (in Russian, abstract in English) // Proceedings of International Workshop Dialogue’95: Computational Linguistics and its Applications, Khazan, 1995.
7. James Steel, ed. Meaning – Text Theory. Linguistics, lexicography, and implications. University of Ottawa press, 1990.
8. FACTOTUM® SemNet, MICRA, Inc., ftp://ftp.cs.cmu.edu/user/ai/new, files fsn*.*, relation.asc; email: cassidy@micra.com.
9. George A. Miller, ed. WordNet: An on-line lexical database. International Journal of Lexicography, 3: 235-312. (1990).
10. Berleant, Daniel. Engineering "word experts" for word sense disambiguation // Natural Language Engineering 1: 339-362 (1995).
11. Narin’yani, A.S. Automatic text understanding – new perspective (in Russian, abstract in English) // Proceedings of International Workshop Dialogue’97: Computational Linguistics and its Applications, Moscow, 1997.
12. Power Translator Professional software, Globalink Inc., http: // www. globalink. com / scripts / products. ixe.
13. Spanish-English, English-Spanish dictionary, Pocket books, Inc. NY, 1963.
14. Bolshakov, I.A., P.J.Cassidy, A.F.Gelbukh. Parallel English and Russian hierarchical thesauri with semantic links, based on an enriched Roget’s thesaurus (in Russian, abstract in English) // Proceedings of International Workshop Dialogue’95: Computational Linguistics and its Applications, Khazan, 1995.