I.A. Bolshakov, A.F. Gelbukh, S.N. Galicia Haro. Electronic Dictionaries: For both Humans and Computers (also published in Russian). J. International Forum on Information and Documentation FID 519, ISSN 0304-9701, N 3, 1999.
Electronic Dictionaries:
For Both Humans and Computers
Igor A. Bolshakov
Alexander F. Gelbukh
Sofia N. Galicia-Haro
Centro de
Investigación en Computación,
Instituto Politécnico Nacional,
Mexico D.F.
{igor, gelbukh, sofia}@ pollux.cic.ipn.mx
Abstract
The idea is developed that the modern electronic dictionaries of natural languages should be more universal, to be used by a human and a computer for reference and text processing, for current needs and further lexicographic research. In the linguistic aspects, the modern dictionaries should be a multi-linked database similar in their contents to the explanatory combinatorial dictionary by I. Mel’čuk and A. Zholkovsky or integral dictionary by Yu. Apresian, but with more stress on thesaurical links between entries and on the storing of common word combinations. In interface aspects, the dictionaries should have their data accessible to a text processing software, to a human user (through a sophisticated interactive browser) and to a lexicographer, to permit him or her appending new features and data to the ever growing structure. The problem is investigated with applications to dictionaries of English, Russian, and especially Spanish language.
Introduction
During several decades there exist in parallel two different types of dictionaries of natural languages. The dictionaries in the printed form were oriented to needs of various readers, i.e., common educated people (for references) and lexicographers (for further research). The dictionaries in electronic form were mainly oriented to various needs of automatic processing of texts and were not directly accessible for a user as a reference tool. But about ten years ago electronic dictionaries appeared which purely repeat their paper form and are directly oriented to a computer user.
After the broad spreading of CD-ROMs, not speaking about Internet access to the data, all thinkable limitations on the size of electronic dictionaries and on the complexity of tools for demonstration of texts on the screen were eliminated. The evident tendency of the next decade is to reduce the role of the paper form to a minimum. The broad community of computer scientists might mistook of this situation as of an ultimate solution of the problem of electronic dictionaries, when all information necessary for automatic processing of texts may be adopted from broad variety of large dictionaries of academic type.
But the situation is not so optimistic. The ex-paper dictionaries, even academically complete, do not contain a lot of important information necessary for text processing, and no entirely automatic procedure may derive this information from these human-oriented texts.
Meanwhile, in their majority, electronic dictionaries constituting the databases for language-oriented software are also not perfect so far, even for their own tasks, not speaking about full absence of human-oriented information and interface for them.
This article discusses the general problems of both forms of electronic dictionaries, and, after revealing some their deficiencies, proposes a possible form of a universal dictionary, similar in its contents to [1, 2], but with more stress on word combinations and thesaurical links. It is supposedly suitable for both mentioned tasks since it should contain the achievements of both academic and applied science. We describe three groups of possible users of the universal electronic dictionary and discuss some requirements for its parts oriented to various applications.
Some deficiencies of human-oriented dictionaries
The motive for a more detailed investigation of possible roles of modern computerized dictionaries has arose among the authors when they were trying to use the results of the search in available Spanish electronic dictionaries to determine some morphological and syntactic features of lexemes for the purposes of a future text processing system.
One of these dictionaries, that of Anaya group [3], was accessible through Internet, the other, that of Spanish Real Academy [4], was acquired on CD-ROM.
At the beginning, we supposed that the electronic form of such dictionaries may give some reliable materials for those researchers and developers who wants to use the information about words of natural language for their automatic processing. But no wonder has occurred.
The electronic version of a dictionary with some prehistory in paper form (e.g., [4] is the 21st edition of the same dictionary in paper form) simply repeats its pre-electronic version, with all its advantages and disadvantages. If the lexicography in the dictionary-creating country is very traditional, being oriented mainly to other lexicographers and putting the maximal stress on etymological issues, then the same feature will be typical for the electronic versions too. Nobody takes care of needs of automatic processing, for which all characteristics of language should be described in absolutely formal manner, even more formal than if it were oriented to a foreigner.
Here are some examples of our unsatisfied needs in graphical, morphological, and syntactical information about Spanish words that were absent in these dictionaries.
In morphology, no automata can calculate that in the pairs like lunes vs. mes or isósceles vs. inglés the former ones are invariable, while the latter ones have two and four forms correspondingly. So it is necessary to append the morphological information to an electronic dictionary, maybe in the shape of the number of the corresponding inflectional class for nouns and adjectives (in [5], as many as three inflectional classes were proposed for Spanish nouns and six classes for adjectives).
The alternations in the graphical form of nouns and adjectives like joven (acquiring the accent mark in plural) or inglés (losing the accent mark in plural) may be given as a common grammar rule of preserving the stressed syllable for these part of speech. But then the reference to a standard (absolutely formal and proved) algorithm of syllabication of Spanish words should be given. However to our knowledge it does not exist. In this situation the dictionary should have supplied additional information for the few exceptions from some simplified general rules.
As to Spanish verbs, no one of these dictionaries indicates, for example, that two homonyms of the verb aterrar, ‘to frighten’ vs. ‘to land’, have quite different paradigms, with and without diphtongization.
In syntax, all dictionaries of Spanish give the label of transitivity or intransitivity for verbs, and this is very important feature for both syntactical and morphological behavior of the verbs. Only a transitive verb in imperative and infinitive can have such a morphological feature as possible agglutination of pronominal clitics (cántale).
However within transitive verbs there exists a very important subgroup with a property of dativity (dar, dirigir, etc.), and the number of agglutinated clitics for them can be up to two (one in dative and another in accusative case, like dámelo). These forms are important part of paradigms of Spanish verbs, and without label of dativity neither a reader nor a machine can synthesize or analyze such forms properly.
The situation is better in the good academic dictionaries of English. Peculiar morphological features of English words are nonstandard endings of plural for such nouns as thesaurus, phenomenon, index, etc., and nonstandard paradigm for such verbs as do, see, go, etc. In such dictionaries as Merriam-Webster, there is all relevant information about these irregularities. Other well-elaborated dictionaries, including the bilingual dictionaries like [13], also give such information. Of course, all these features are available in electronic editions of the same dictionaries.
For Russian language, the purely formal representation of the sophisticated morphology of each inflectional word was given 20 years ago in the dictionary by A. Zalizniak [14]. Software developers and electronic publishers have taken this unique dictionary at once for their purposes. We may see one of reference systems on this basis in the CD-ROM edition under name Russkij Filolog by Agama, Russia [15].
But just as we try to find in academic dictionaries something about combinatorial properties of any specific language, we will usually find nothing or nearly nothing. The information about usual valencies of nouns, adjectives, and especially verbs is not given systematically in any such dictionary even for English language. Only specialized dictionaries like the one by Jackendorf contain such information for some English verbs.
Analogously, in academic dictionaries there is no information about other aspects of word combinability, formalized by A.Zholkovsky and I. Mel’čuk as lexical functions [1]. So we cannot derive from them how we should express in Spanish or Russian such word combinations as to pay attention or to give help. For English some information on this issue may be found in [6], for Russian and French there exist a small explanatory combinatorial dictionaries. But in full scale the problem remains unsolved for any language.
Some deficiencies of computer-oriented dictionaries
The main problem with computer-oriented dictionaries is the same: each dictionary contains only some kind of information on the words, so that many different dictionaries are necessary to process the information on different levels of the language. On the first glance, this should not be a problem since computer dictionaries should be easily combined with each other. Unfortunately, this is not the case.
First, the sets of words present in different dictionaries can be different, so that for a particular word some piece of the information can be absent in such a combined dictionary. Except for a small kernel, dictionaries tend to differ very significantly in their coverage. E.g., very similar in their goals FACTOTUM® SemNet by MICRA, Inc., and WordNet dictionaries have only 20% of common lexicon [16]. When several, or even many, dictionaries are combined, nearly no words will have complete information announced in the partial dictionaries.
What is more, combining of dictionaries is not as straightforward as it may seem. Such a combination is meaningful only if the corresponding senses of the homonymous and polysemantic words are combined correctly. However, both the number and the sequence of the senses in different computer dictionaries are different, and often there is no way to recognize what sense of the word in one dictionary corresponds to what sense in another one.
This divergence may be easily proved by comparison of any two large dictionaries. Below two entries with the same Spanish vocable estante, noun ‘rack / bookcase / shelf’, or adj. ‘staying / settled’, are given. The first is taken from [3], and the second from [4], with the translation of explanations to English.
estante (in [3])
1. m. Bookcase without doors and with shelves.
2. m. Shelve in a bookcase.
3. m. Each leg supporting the frame of a machine.
4. adj. Staying, immobile.
estante (in [4])
1. a. p. us. de estar. Who is or constantly staying at some place: Pedro, ESTANTE en la corte romana.
2. adj. Applicable to cattle, especially to the wooly, which constantly pastures in the limits of a juridically settled territory, being administratively ascribed to it.
3. Applicable to a cattle-breeder or an owner of a flock of cattle.
4. Piece of furniture with shelves or planks, usually without doors, that is used for books, paper, and other things.
5. Shelf.
6. Each of four straight legs that supports the frame of a machine-tool in which wooden hammers are warping.
7. Each of two straight legs, on which the rotating horizontal axis of a lathe is resting.
8. Murc. Participant of Easter procession.
9. Amér. Each of wooden non-decaying supports, which after its hammering in the soil serves for supporting frames of buildings in tropical cities.
10.Mar. Stick or pole, which is settled under a fitting table for the fastening to it of the ship rigging. Ú. m. en pl.
Even after exclusion of dialectological and terminological variants, the difference in the number and the content of the explanations stays rather significant for a human, not to speak about the machine. Examples of such divergence are very numerous.
In human-oriented dictionaries some remarks are usually given to help distinguishing the senses, whereas in computer dictionaries such remarks are usually either absent from the very beginning or were stripped out when converting the dictionary to the computer form.
Also human-oriented dictionaries usually give some additional information, like grammar references, tables of measurement units, etc. Naturally computer-oriented dictionaries do not give such information, not to mention the explanations and examples for the words.
In general, the absence of informal information, or comments, in a case where some important piece of information cannot be represented formally, is usually a problem with computer dictionaries.
Towards the idea of the universal dictionary
As we have seen in the previous examples, the problems of the existing dictionaries are caused, apart from natural incompleteness of the information, by spreading of the information across many dictionaries of various types, with different interfaces, provided separately from various sources. Surely there exist (or will be created) morphological dictionaries of, say, Spanish, at least in paper form like [7], that possibly are or will be available in electronic form. The problem is that one needs to look up (and probably search through) many different sources to see all the information on a particular word.
Our main idea is rather trivial:
· A computer dictionary must present all the information about each word and the language in general.
· It must present all the possible ways of accessing and searching this information.
By all the possible ways of accessing the information we mean, besides other requirements, that the information should be accessible to both human users and other programs. A dictionary is so large piece of data, and its development is so expensive, that it is unacceptable to maintain, keep, and use separate versions of dictionaries for the users and for the machine.
The information in the dictionary should be presented uniformly and should be available in an integrated environment, such as a common browser (for the user) or a consistent API[1] (for programs), both with powerful search capabilities.
Since general information on the language, i.e., its grammar, can be considered applicable to each word of the language, the dictionary that gives all the possible information on words, must give also all the available grammatical information, with cross-references between the grammar tables and individual words.
What is more, since grammatical information often has the form of algorithms rather than tables, the universal dictionary should not only show some text on the screen and provide the descriptions of algorithms, but contain active procedures to apply these algorithms, in particular, various services of checking and parsing, accessible through both a browser and an API.
All this may sound as if what we are speaking about were a CD-ROM with all the known and yet unknown linguistic knowledge, sources, and algorithms, as well as all the types of lingware from spell-checkers to translators. Well, we do not say that, though in the long term this is the right direction. What we suggest is, first, to collect all the already available information, including algorithms, into a common integrated dictionary, and, second, then start to improve this dictionary by development of the parts it most obviously lacks.
Clearly such a dictionary should be, at least for the first time, a mechanical combination of different dictionaries, licensed from different sources and maintained by different groups, since it is hardly possible to organize right now a great project on creating a new universal dictionary. However, all such sources should be merged by a program, that will parse all their formats and compile this information in one consistent database with all the necessary cross-references.
For a dictionary it mainly means to collect all the information available in all the sources for each word and combine it in a single entry. Many problems arise when combining such information. The most obvious problem is avoiding the repetitions of similar sections of the entry.
Well-formalized information, such as morphological features, can be relatively easy uniformed and merged. However, other sections of the dictionary entry, such as the explanations, are extremely difficult to automatically combine.
The situation is complicated by the fact that the merging operations should involve minimum of hand work. Since many different sources are used in the dictionary, and they are updated at random moments by their maintaining groups, the whole dictionary is to be updated very frequently.
As the idea of the universal dictionary becomes more popular and the participant groups become to be more concerned with being involved in a common project, it will be possible to develop some guidelines, and then standards, for unification of the formats of different sections of the dictionary entry. This will allow for creation a better automatic procedure for merging such sections.
All these problems mainly arise when the dictionaries are combined with large intersection in their purposes and coverage. On the other hand, if they are “orthogonal” enough to each other, i.e., have different purposes, it is enough to mechanically combine the information, adding a special mark to each part. E.g., it is enough to mechanically combine the explanations for the word root from a mathematical and a biological dictionaries, with an appropriate usage mark accompanying each meaning.
A good example of the idea of collecting different sources in one product with a consistent user interface is given by the excellent MultiLex dictionary system by MediaLingua, Inc., Russia that we describe in more details in the next section [8]. However, because of the difficulties mentioned above no attempt was made in this system to merge the information for each word together, or to provide a way to search through all the dictionaries available in the system.
Since the universal dictionary will obviously contain much more information for each single word than is necessary for any particular application or user, powerful and well-thought search tools are to be provided for both human user and programs; the amount, form and the type of information presented in reply to the queries should be fully customizable. This includes the possibility to ignore or hide some (or most) of the types of the information on a word.
The theory and practice of search tools is now developed well enough, so that supplying such a tool with a dictionary is absolutely not a problem technically. Thus we will not discuss those tools in detail here. Also, specific requirements and specifications for the interface for the universal dictionary go beyond the scope of this article.
Therefore, the universal dictionary should ideally contain the following types of information, or a subset of it:
· Orthographic form(s) of keyword
· Pronunciation, including options if they exist
· Syllabic structure of the keyword
· Morphemic structure of the word and its morphological class (of inclination or subjugation)
· Syntactical classifying features including part of speech
· Explanation(s) of the keyword given in the most possibly formal way and with the maximal systemic consistency. Special allusive and stylistic labels at different meanings are also to the point
· References to semantically related words that are ideally included in a thesaurus or semantic network. On the first stages, the references can be limited to those synonymous ones
· Government patterns (improved subcategorization frames)
· Examples of usage
· Etymology
· Combinatorial features, that may include a full combinatory dictionary in the style of [1, 9], and/or the dictionary of word combinations, i.e., the possibility to view the list of other words with which it can be used in texts [10]
· Translations to other languages in the maximally possible number. This can be achieved by the combination of several bilingual dictionaries
· Other types of available information.
The necessity for including to the dictionary the combinatorial information should be especially emphasized, since it gives a very important part of the information for the words, that can be currently found only in special dictionaries. Compiling for each word a list of words with which it usually or naturally occurs in texts is much easier as compared with listing all the lexical functions of each word, but in combination with a simple thesaurus such a feature proves to be very useful for both human users (for text compilation) and computer programs (for syntactical analysis, disambiguation, etc.) [10]. In our opinion, this is the direction in which modern dictionaries should evolve in the nearest future.
Below we give some discussion of the user interface to the universal dictionary and its API.
Needs of the end user
For a common human user, the dictionary should provide a special modernized interface with a browser permitting to extract all necessary knowledge from the linguistic database and deliver it to a user in a comprehensible and convenient form.
An example of an extendible dictionary system that provides a uniform interface to a variety of different dictionaries is the mentioned above MultiLex 2.0. Though it has the interface to Microsoft Word word processor, it is a purely user-oriented product. Its user interface is shown on Fig. 1.
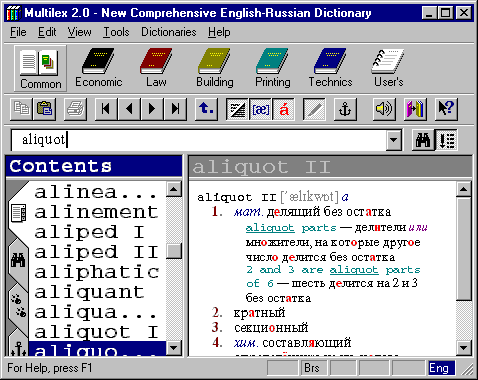
Fig. 1. MediaLingua’s Russian-English MultiLex 2.0.
However the authors do not combine all the dictionaries available in the system to one dictionary. Instead, the user can “open,” one at a time, any book shown in the “dictionary bar” near the top of the window.
In the version 2.0, the user has to re-type the same word if he or she wants to see it in another dictionary. If the other dictionary were automatically opened at the current word when you switch the dictionaries, it would make the MultiLex system much closer to the idea of the universal dictionary. In this case the dictionary buttons would serve as switches of the type of desirable information for the current word, giving the user the illusion of the presence of all the information on the current word in one “big edition”.
In [11], two of the co-authors of the program discuss the principles they used when adapting the existing paper dictionaries scanned from famous books like [13] to the electronic dictionary system. Since their work is in Russian, it’s appropriate to repeat here their main suggestions.
They emphasize four main differences between the paper and electronic form of a dictionary that affect both the way the dictionaries are to be created and the way existing dictionaries can be shown on a computer screen:
· There is no need to save the space in the dictionary
· The means of emphasis can be wider used
· Different modes of presentation of the information can be used
· Selections can be compiled.
The first difference is the key point in all the issues of modern electronic dictionaries, oriented to a human user, or to a program, or both. For the user interface even to existing, originally paper, dictionaries, it has simple, but important implications:
· There is no need to glue together in one entry the information on different words with the same root
· There is no need to put all the information on one word in a paragraph. Instead, the entry should be visually structured on the screen
· The examples can be used much more intensively; one example can be included in different dictionary entries when it is necessary.
Splitting the dictionary entry in different paragraphs, one paragraph for each structural unit of the entry, changes the way the dictionary entry can be shown in the screen:
· Colors and fonts can be used to visually distinguish various marks and types of information, since there is no more need to use them to emphasize the boundaries between structural units
· A nested hierarchy of paragraphs can be used to reflect the structural hierarchy of the entry, e.g., parts A, I, 1., 1), a), examples, etc.;
· Various delimiters, e.g., the long dash, can be used to visually structure the information on one line, like examples and their translations.
In other respects the user can take advantage of the active nature of a computer:
· The dictionary can be customized when shown, as if it was a specialized dictionary or a variant of the dictionary, e.g., oriented only to native speakers of the source or target language
· The unwanted types of information can be removed from the screen or iconized, e.g., etymology, pronunciation, examples, etc.
· It is possible to present an outline view of the entry, or organize the dictionary entry in the form of a tree, allowing the user to interactively expand the branches that they really need
· It is possible to collect the information from different dictionary entries or from different available dictionaries to create lists of, to say, only examples.
However, in its most useful way the active nature of a computer can be applied in search capabilities of a dictionary system, so that it may go far beyond just the ability to automate the alphabetical search. An example of relatively powerful search capabilities gives a very professionally implemented browser for Diccionario de la Lengua Española by Espasa Calpe, Spain. Regrettably we are aware of the use of this browser only for a single dictionary, but its search tools are much closer to the tools that would be appropriate to the universal dictionary. A screen shot of a search query in the system is shown on Fig. 2.
This browser allows the user to view the dictionary in different aspects, sorted by various marks such as grammatical categories, languages of origin, areas of usage, stylistic marks, special subjects, and many other issues. In fact, the dictionary can be sorted by any kind of the marks used in the dictionary. These marks are organized in trees, so that the user can see only nouns, or only masculine nouns; only words used in American continent, or in Central America, or in the Caribbean, or in Cuba.
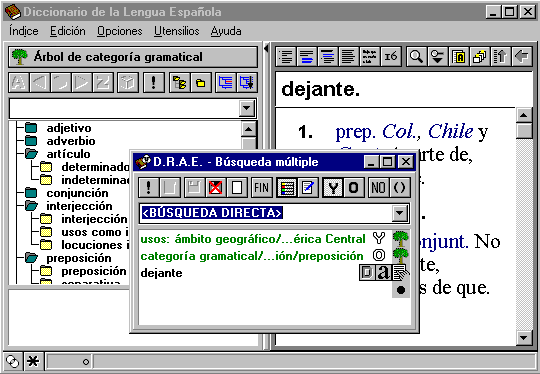
Fig.
2. Advanced search in Espasa Calpe’s Spanish
Diccionario
de la Lengua Española.
In addition, such limitations can be combined in general logical expressions, possibly parenthesized, with the use of AND, OR, NOT operators, as it is shown in the pop-up window on Fig. 2. Best of all, the request can be compiled in a convenient drag-and-drop way, or, as an option, directly typed in a window.
In general, of course, there are many other possible search operators on words involving different levels of their representation, such as morphological normalization, using the morphemic or phonemic structure, or using regular expressions for the letters of the words. Some of such features, like morphological normalization, are implemented, e.g., in MultiLex system mentioned above.
In addition, the universal dictionary should provide access to some procedures, such as inclination and conjugation, agreement within word combinations, determining the syntactical structure of a phrase, translation of phrases or texts, learning procedures or games, etc. Some of these features are very natural for current dictionaries and are implemented even in some pocket electronic dictionaries like Franklin’s Spanish Master [12], others, like translation capabilities, are to be added to the universal dictionary in the future.
Needs of text processing system
For needs of text processing software, the dictionary should have a software library of procedures permitting to serve any separate layer of the language processing or all of them.
The technical issues of such an interface go far beyond the scope of this work. The general consideration is that all the information, or as much of it as possible, should be accessible from other programs in clear and formal way. It should be possible to navigate through the dictionary, extracting for a specific word its morphological, syntactical, semantic, combinatorial features, represented in a compact and unambiguous form.
Specifically, this representation should not be just strings extracted from an electronic version of an ex-paper dictionary, with all their inconsistencies within one dictionary and differences between dictionaries. Instead, they should be members of well-defined sets, or structures consisting of such members.
There should be a way to navigate the tree of senses of a single word, from the textual representation of the word to a specific, disambiguated sense. In the simplest case, this means that the desired part of speech can be specified or not, a group of senses like A, I, 1., 1), a), can be specified or not, etc.
In general, many of the requirements to the visual representation of the dictionary, mentioned in the previous section, hold for its API.
It is especially important that the universal dictionary should provide services for other programs to various requests, from spell-checking to translation of texts, words, phrases, etc. There is no need to wait for the time when all these algorithms will be developed to the acme of perfection. The dictionary should provide the services that are available right now, at least those morphology-related ones.
In the future, the interfaces to such services ought to become standard parts of the operating system, in the way how the interfaces to, say, computer networks or databases are provided. For example, it would be natural if morphological normalization became a part of standard search tools, or spell-checking became a part of the context menu of the standard edit control like in Microsoft Windows. However, what is important for us now is that even if the information itself cannot be provided by standard tools, at least the way it is accessed in the universal dictionary should be standardized in the future by the operating system.
Needs of lexicographer
Naturally, the universal dictionary itself should be the environment in which lexicographers prepare new data for this or other dictionaries. An excellent example of such an integrated environment for a lexicographer is the system by S. Starostin [16].
This means that the dictionary should provide a convenient way to modify the information in it, make temporal notes, run very sophisticated queries. What is more, the dictionary should provide a specialized built-in language or API for the lexicographer to be able to create his or her own programs to investigate the data present in the dictionary.
Information in the dictionary should have labels of its completion, anonymous or personified. The information without such labels, i.e., probably incomplete or unreliable, is to be accessible only to privileged users (lexicographers and system managers, or other users in special mode) for further appending and correcting.
One of the parts of the universal dictionary very important for both categories of the human users, i.e., for common users and especially for lexicographers, are examples of usage of words. The examples for a lexicographer should be given in a broader context, should be marked up (including morphology, syntax, etc.) and accessible with a built-in language for detailed investigation. A text corpus could be also a very useful part of the universal dictionary, properly marked up with disambiguated references to the dictionary entries.
Conclusion
The main problem of the existing dictionaries, not to mention the natural incompleteness of information, is spreading the information and functions across many different dictionaries and programs. There are mathematical and biological dictionaries, dictionaries for human users and for computers, morphological and etymological dictionaries. There are programs for spell-checking and translation, for learning and indexing, and each one uses its own special dictionary. With paper dictionaries it was, and is, inevitable, but with electronic dictionaries it is a nonsense.
We propose to combine all the available types of linguistic information on each word in one universal electronic dictionary. For the first time, it can be just a mechanical combination of existing dictionaries. The universal dictionary should provide a wide variety of ways to access the information, both by other programs or human users, and powerful search capabilities. It should be used as a universal source of information for various tasks of text processing, learning, translation, etc.
In the future, additional types of information are to be appended to the dictionary, especially the combinatorial information in the form of lexical functions and word combinations.
References
1. Mel’čuk, I. A. and A. K. Zholkovsky. Explanatory combinatorial dictionary, in: M.W. Even (ed.), Relational Models of the Lexicon: Representing knowledge in Semantic Networks. Cambridge: Cambridge University Press, 1988, pp. 41-74.
2. Yu. Apresian. On integral dictionary (in Russian). in: Semiotika i informatica, No. 32, Moscow: VINITI Publ., 1988.
3. Diccionario del Español contemporaneo, grupo ANAYA, http://www.anaya.es.
4. Diccionario de la lengua Española. Real Académia Española, Edición en CD-ROM, 1996.
5. A. Bolshakov. Modelo morpfólogico formal de sustantivos y adjetivos en español. Computación y Systemas, N 1, 1997
6. Benson, Benson, and Ilson. The BBI Combinatory Dictionary. Moscow, 1989
7. García-Pelayo, R., G. M. Durand, Práctico Larousse de la conjugación. Ediciones Larousse, México: 1983.
8. MultiLex, MediaLingua, Inc., http://www.medialinva.com/english/russian/MultilexOnline/MOLFrames.htm
9. James Steel, ed. Meaning – Text Theory. Linguistics, lexicography, and implications. University of Ottawa press, 1990.
10. Bolshakov, I. A. Multifunction thesaurus for Russian word processing. Proceedings of 4th Conference on Applied Natural language Processing, Stuttgart, 13-15 October, 1994, p. 200-202.
11. Volovich, M., K. Zorky. Vocabulary in books and on displays (in Russian, abstract in English) // Proceedings of International Workshop Dialogue’97: Computational Linguistics and its Applications, Moscow, 1997.
12. BookMan. Franklin Inc. http://www.franklin.com/products/newprod.html.
13. Apresian, Yu.D. New English-Russian Dictionary, Russkij Yazyk, Moscow, Russia, 1994.
14. Zaliznyak, A.A. Grammaticheskij Slovar’ Russkogo Yazyka (in Russian, Russian Grammar Dictionary), Russkij Yazyk, Moscow, Russia, 1974.
15. Russkij Filolog, Agama Inc., Russia, http://russia.agama.com/Rfil.htm.
16. Pertsov, N.V., S.A.Starostin. On the lexicographic inquiry information system LEXIS of the Russian language (in Russian, abstract in English) // Proceedings of International Workshop Dialogue’95: Computational Linguistics and its Applications, Moscow, 1995.
17. Bolshakov, I.A., P.J.Cassidy, A.F.Gelbukh. Parallel English and Russian hierarchical thesauri with semantic links based on an enriched Roget’s thesaurus (in Russian, abstract in English) // Proceedings of International Workshop Dialogue’95: Computational Linguistics and its Applications, Khazan, 1995.