Manuel Montes y Gómez, Aurelio López López, Alexander Gelbukh. Text mining as a social thermometer. Proc. Text Mining workshop at 16th International Joint Conference on Artificial Intelligence (IJCAI'99), Stockholm, Sweden, July 31 – August 6, 1999, pp. 103-107.
Text Mining as a Social Thermometer
|
Manuel Montes-y-Gómez, Alexander F. Gelbukh |
Aurelio López-López |
|
mmontesg@susu.inaoep.mx gelbukh(?)pollux.cic.ipn.mx Natural Language Laboratory, National Polytechnic Institute (IPN). Mexico |
allopez@inaoep.mx Electronics, INAOE Luis Enrique Erro No. 1 Tonatzintla Pue. 72840 México
|
Abstract
In this paper, we show how text mining techniques can be used in analysis of Internet and newspaper news. We present a method that focuses on the current topics of opinion appearing in the news, illustrating the method mostly with Spanish examples. This method uses a classical statistical model based on distribution analysis, average calculus, and standard deviation computation to discover information on how society interests are changing and in which direction this change points. We also describe a method to identify important current topics of opinion, those that lead to stability within a period.
1 Introduction*
“Data Mining and Knowledge Discovery address the needs of alphanumeric databases. Text Mining is directed at textbases. The implications are that the equivalent of Knowledge Discovery is Undiscovered Public Knowledge. If this is true, this work could be the most important effort underway today” [tryb.org site, 1998].
Without a doubt, newspapers and Internet news remain one of the most important information media that reflect most current social interests. This is why we consider interesting and useful to apply text mining techniques on them.
The principal aim of our system is to analyze news and to discover the main opinion topics, their trends and some description patterns. We consider opinions to be especially important for investigating the state of society and related sociological and political issues. Indeed, opinions are not determined so directly by the interests and intentions of the columnists and professional writers; instead, they represent more or less directly the vox populi, thus allowing to identificate the topics that are important for ordinary people.
Other systems similar to our that are focused to the analysis of some document collections has been developed [Feldman and Dagan, 1995; Lent et al., 1997]. However, the work with opinions appearing in the news has some specifics. For example, it faces a double problem: (1) the discovery of changing trends and (2) the identification of states characterizing the periods of stability.
2 Source information
All Text Mining systems face the problem of obtaining the input information, or, in other words, the problem of making a structure out of the raw texts to be analyzed. This situation has caused many of the existing text mining systems to work over easy-to-extract information such as document keywords, themes or topics, proper names, or other types of simple strings [Feldman and Dagan, 1995].
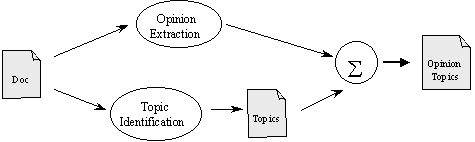
Considering this problem and the way others have resolved it, we designed an opinion acquisition method based on well-known indexing and information extraction techniques. Figure 1 shows the architecture of our opinion topic extraction system.
The system consists of three modules. The first module finds the topic(s) of the document using a method similar to that proposed by [Gay and Croft, 1990], when the topics are related to noun strings.
The second module extracts the opinion paragraphs basing on so-called pattern matching technique [Kitani et al., 1994] using as a trigger a list of verbs denoting communication actions, such as Spanish dijo ‘say’, propuso ‘propose’, etc. [Klavans and Kan, 1998].
The third module matches topics with opinion paragraphs and selects only the topics that are explicitly mentioned in these opinions. This new set of topics is what we call the opinion-topic set.
|
Figure 2. Example of Opinion Topics to be used for Mining. |
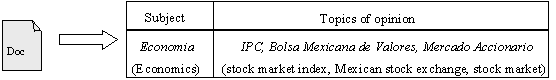
After this process, the input data (opinion-topic set) is complemented with the information about the opinion subject, e.g., economía ‘economics’, política ‘politics’, sociales ‘social’, etc. An example of the output of the process described above which is used as the input for our text mining component is shown in the Figure 2.
3 Trend analysis
After the opinion topics have been extracted from a set of news texts, the mining process begins to analyze these topics with the aim of finding and characterizing their trends. The opinion topic trend analysis has two main parts:
· Trend discovery,
· Identification of the factors (opinion topics) that contribute to produce this trend.
|
Figure 1. Module for extraction of opinion topics.
|
It also considers two different situations: trends of change and stability trends. In case of a change trend, it is important to discover the main change sources, for instance, the opinion topics with the maximum change rates. In case of stability trends, it is important to identify the stability factors, for instance, those of the most discussed opinion topics that remained without change.
3.1 Discovering trends
We discover trends in our opinion topic database comparing probability distributions [Glymour et al., 1997]. These distributions have been used before for the same purpose [Feldman and Dagan, 1995], but with a different similarity measure, e.g. Feldman and Dagan used the relative entropy measure (KL-distance).
To determine the changes, we fix two “time moments,” one “past” and another “current” moment, and compare the characteristics of the two data sets, the “past” and the “current” one. We use some area values to compare the past frequency distribution D1 with the current, or last, data distribution D2, where the distributions D1 and D2 are first integrated and filtered to describe the same and relevant opinion topics.
Let T1, T2 be sets of opinion topics at the times t1 and t2 respectively, with t1 < t2, and fi1, fi2 be the frequencies of the opinion topics (q i) at the times t1 and t2.
Integration:
![]()
This operation ensures that the work is done at the same data sets, even if some of the topics appearing at the moment t1 have disappeared at t2 and vice versa.
Filtering:
![]()
This action removes those opinion topics, which are irrelevant to the analysis, for the sake of comutational simplicity. The frequency threshold value b specifies the minimum total frequency for a topic qi to be considered as interesting.
Based on this set, the frequencies and probabilities can be recalculated as follows:
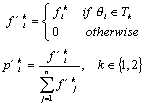
Comparison method:
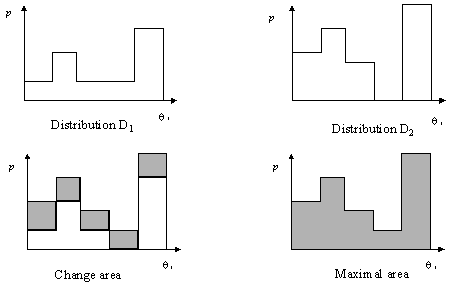
Our purpose is to compare two probability distributions D1 and D2 to discover whether these two distributions are different or similar. To obtain a measure of the relation of these distributions, we compare the two areas: the change area and the maximal area. Figure 3 shows a simple example of two distributions, their change area, and their maximal area.
Change area:
![]()
Maximal area:
![]()
Coefficient of relation:
![]()
The trend discovery criteria:
· If Cc >> 0.5 then there exists a global change trend;
· if Cc << 0.5 then there exists a stability period.
If the coefficient differs from 0.5, there exists a global change trend, slighter or greater, or a stability period.
|
Figure 3. Comparison method. |
3.2 Identification of Change Factors
A global trend of change is caused basically by abrupt changes of individual opinion-topics, that is, their identification in most cases makes evident the causes of this global change behavior.
We calculate a frequency difference value (dF) for each of the opinion-topics, and then select as a change factors the topics with the highest dF value.
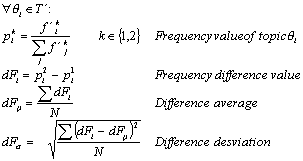
So, the opinion-topic q i is a change factor if:
dFi < dFm - dFs or dFi > dFm + dFs
This criterion was found empirically. In other fields (or with other topics) the Chebyshev criteria may do as well.
3.3 Stability Factors
In general terms, stability is produced by all topics, but the most important topics are those contributing more significantly to produce this trend. The criterion we are using to identify the stability factors is as follows.
Selection of important topics:
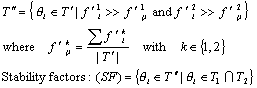
4 Experimental results
To test these ideas, we analyzed El Universal, a Mexican newspaper, and collected the economic news for the last week of January 1999 and for the first week of February 1999. Before normalization, we had:
| Tt1 È Tt2 | = 47 opinion topics.
After integration and filtering:
| T´ | = 15 opinion topics, where
![]()
For each opinion-topic in T’, we calculated its frequency (f’), probability (p’) and a difference-frequency value (dF). Table 1 shows these statistics.
Trend Discovery:
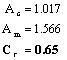
Since Cr > 0.5, there exists a slight global change trend.
Factors of change:
Since dFm = 2 ´ 10-4 and dFs = 0.08311 for the opinion topic set, the change factors discovered are:
·
Opinion topics that are disappearing:
(dFi < dFm - dFs):
bancos ‘banks’,
meta inflacionaria ‘inflationary goal’,
inflación ‘inflation’.
· Opinion topics that are becoming more interesting: (dFi
> dFm + dFs):
tasa de intereses ‘interest rate’,
Brasil,
cambio de moneda ‘change of currency’.
|
Topics |
f´ 1 |
f´ 2 |
p´ 1 |
p´ 2 |
dF |
|
Bancos ‘banks’ |
7 |
4 |
.212 |
.125 |
– .087 |
|
Meta inflacionaria ‘inflationary goal’ |
3 |
0 |
.09 |
.0 |
– .09 |
|
Política monetaria ‘Monetary policy’ |
4 |
4 |
.121 |
.125 |
.004 |
|
Ajuste fiscal ‘Fiscal adjustment’ |
2 |
0 |
.06 |
.0 |
– .06 |
|
Inflación ‘inflation’ |
4 |
0 |
.121 |
.0 |
– .121 |
|
Union monetaria ‘Monetary union’ |
2 |
0 |
.06 |
.0 |
– .06 |
|
Tasa de intereses ‘interest rate’ |
3 |
9 |
.09 |
.28 |
.19 |
|
Política fiscal ‘fiscal policy’ |
2 |
0 |
.06 |
.0 |
– .06 |
|
Economías asiaticas ‘Asian Economies’ |
1 |
1 |
.03 |
.031 |
.001 |
|
Brasil ‘Brasil’ |
1 |
4 |
.03 |
.125 |
.095 |
|
Economía nacional ‘national economy’ |
2 |
1 |
.06 |
.031 |
– .029 |
|
Cambio de moneda ‘change of currency’ |
0 |
3 |
.0 |
.094 |
.094 |
|
Mercado accionario ‘stock market’ |
2 |
2 |
.06 |
.062 |
.002 |
|
Crisis financiera ‘Financial crisis’ |
0 |
2 |
.0 |
.062 |
.062 |
|
Mercados financieros ‘Financial market’ |
0 |
2 |
.0 |
.062 |
.062 |
Table 1. Experimental results.
5 Conclusions and future work
These experiments and results encourage us to continue working in this direction. We have shown that it is possible to obtain useful information from not very complex text representation, though we believe that robust text representations can improve the system and will allow the design of more sophisticated text mining tools, such as inference tools, relational processes, clustering methods, visualization techniques, and summarization. As further work, we plan to:
· Enrich the topics beyond keywords, with the aim of handling themes generalizing single words. Namely, we plan to test the resources proposed in [Guzmán, 1998]. Their use will allow generalizing or specializing the topics for different levels of analysis.
· Develop a method to discover the change relations between opinion areas. For example: How the topic of the Soccer World Cup, or a general increment in sport topics, affect the general trend of the political topics?
· Analyze and classify the opinions on types. For example, opinions in which something is proposed predicted or qualified. This classification could be interesting and useful for a high level analysis of opinions.
Like with any data mining system, the more data and data types we have the more, and better, information or knowledge the system can discover. This is why we are working on construction of improved opinion representations that permit obtaining additional interesting results, for example, discovering similar opinions, opposite opinions, contradictions, or identifying trends, deviations, or patterns in different opinion components.
References
[Agrawal et al., 1993] Rakesh Agrawal, Tomasz Imielinski and Arun Swami. Database Mining: A Performance Perspective. In IEEE Transactions on Knowledge and Data Engineering, Special issue on Learning and Discovery in Knowledge-Based Databases, Vol. 5, No. 6, December 1993, 914-925.
[Agrawal et al., 1996] R. Agrawal, A. Arning, T. Bollinger, M. Mehta, J. Shafer, R. Srikant. The Quest Data Mining System. In Proc. of the 2nd Int'l Conference on Knowledge Discovery in Databases and Data Mining, Portland, Oregon, August, 1996.
[Bhandari et al., 1997] Inderpal Bhandari, Edward Colet, Jennifer Parker, Zacary Pines, Rajiv Pratap, Krishnakumar Ramanujam. Advanced Scout: Data Mining and Knowledge discovery in NBA Data. In Data Mining and Knowledge Discovery 1, 121-125, 1997.
[Church and Rau, 1995] Kenneth W. Church and Lisa F. Rau. Commercial Applications of Natural Language Processing. In Communications of the ACM, Vol.38, No 11, November 1995.
[Cowie and Lehnert, 1996] Jim Cowie and Wendy Lehnert. Information Extraction. In Communications of the ACM, Vol.39, No.1, January 1996.
[Davis, 1989] Roy Davis. The Creation of New Knowledge by Information Retrieval and Classification. In The Journal of Documentation, Vol 45, No 4, pp. 273 –301, December 1989.
[Feldman and Dagan, 1995] R. Feldman and I. Dagan. Knowledge Discovery in Textual databases (KDT). In Proc. Of the 1st International Conference on Knowledge Discovery (KDD_95), pp.112-117, Montreal, 1995.
[García-Menier, 1998] Everardo García Menier. Un sistema para la Clasificación de notas periodisticas (in Spanish). In Proc. Of the Simposium Internacional de Computacion, CIC-98, México, D. F., 1998.
[Gay and Croft, 1990] Gay, L. and Croft, W. Interpreting Nominal Compounds for Information Retrieval. In Information Processing and Management 26(1): 21-38, 1990.
[Glymour et al., 1997] Clark Glymour, David Madigan, Darly Pregibon, Padhraic Smyth. Statistical Themes and Lessons for Data Mining. In Data Mining and Knowledge Discovery 1, 11-28, 1997.
[Guzmán, 1998] Adolfo Guzmán. Finding the main Themes in a Spanish Document. In Expert Systems with Applications, 14, pages 139-148, 1998.
[Hahn, and Schnattinger, 1997a] Udo Hahn and Klemens Schnattinger. Knowledge Mining from Textual Sources. In F.Golshani & K.Makki (Eds.) CIKM’97, Proceedings of the 6th International Conference on Information and Knowledge Management. New York/NY: ACM, Las Vegas, Nevada, USA, November 10-14, 1997, pp.83-90.
[Hahn and Schnattinger, 1997b] Udo Hahn and Klemens Schnattinger. Deep Knowledge Discovery from Natural Language Texts. In D. Heckerman, H.Mannila, D. Pregibon & R.Uthurusamy (Eds.) KDD’97, Proceedings of the 3rd Conference on Knowledge Discovery and Data Mining. Newport Beach, Cal., August 14-17, 1997. Menlo Park/CA: AAAI Press, 1997, pp.175-178.
[IBM, 1997] IBM. Text Mining: A Quick Overview. IBM Technology Watch, A Decision Support System, http: // www. synthema. it / tewat / demo / pres / ntwprese. htm
[Kitani et al., 1994] Tsuyoshi Kitani, Yoshio Eriguchi, and Massami Hara. Pattern Matching and Discourse in Information Extraction from Japanese Text, In Journal of Artificial Intelligence Research 2 (1994) 89-100.
[Klavans and Kan, 1998] Judith Klavans and Min-Yen Kan. Role of Verbs in Document Analysis. In Proc. 17th Conference on Computational Linguistics (COLING-ACL’98), 1998.
[Lent et al., 1997] Brian Lent, Rakesh Agrawal and Ramakrishnan Srikant. Discovering Trends in Text Databases. In Proc. of the 3rd Int'l Conference on Knowledge Discovery in Databases and Data Mining, Newport Beach, California, August 1997.
[Schnattinger and Hahn, 1997] Klemens Schnattinger & Udo Hahn. Intelligent Text Analysis for Dynamically Maintaining and Updating Domain Knowledge Bases. In X.Liu, P.Cohen & M.Berthold (Eds.), IDA'97, Proceedings of the 2nd International Symposium on Intelligent Data Analysis. London, U.K., August 4-6, 1997. Berlin etc.: Springer, 1997, pp.409-422.
[Weiss and Indurkhya, 1998] Sholom M. Weiss and Nitin Indurkhya. Predictive Data Mining: A Practical Guide. Morgan Kaufmann Publishers, Inc., 1998.
[tryb.org site, 1998] http: // www. tryb. org / tmkd / id1_cf.htm, Text Mining and Knowledge Discovery, 1998.