Alexander Gelbukh, Igor Bolshakov. Avances y Perspectivas de Procesamiento Automático de Lenguaje Natural. J. IPN Ciencia, Arte: Cultura, N 31 Vol. II, Mayo-Junio 2000, ISSN 1405-2822. IPN, Mexico, pp. 10-18.
Avances y Perspectivas
de Procesamiento Automático de Lenguaje Natural
Cuento de una Máquina Parlante
Alexander Gelbukh
Igor Bolshakov
Laboratorio
de Lenguaje Natural,
Centro de Investigación en Computación,
Instituto Politécnico Nacional.
Av. Juan Dios Bátiz, Zacatenco, 07738 México D.F.
gelbukh(?)cic.ipn.mx
En los cuentos para niños viven los animales que hablan... hasta si no pronuncian ni una sola palabra en todo el cuento: de hecho, en los cuentos, los animales que hablan son los que pueden pensar como las personas, no los que pueden pronunciar palabras como los pericos. Las personas no pueden hablar sin pensar y saber muchas cosas, y parece que no pueden pensar sin hablar en su mente con ellos mismos. ¿Y las computadoras?
En este artículo, hablaremos de cómo las computadoras nos pueden ayudar a los seres humanos en nuestra ocupación principal: pensar y comunicar. ¿Qué es el procesamiento automático de textos? ¿Para qué sirve? ¿Es simple? ¿Es posible? ¿Cuál es su futuro y qué se está haciendo al respecto?
El tesoro más valioso de la raza humana es el conocimiento, es decir, la información. Existen en el mundo volúmenes inmensos de información en forma de lenguaje natural: los libros, los periódicos, los informes técnicos, etcétera. Pero la posesión verdadera de este tesoro implica la habilidad de hacer ciertas operaciones con la información:
- Buscar la información necesaria,
- Comparar las fuentes diferentes, y hacer inferencias lógicas y conclusiones,
- Manejar los textos, por ejemplo, traducirlos a otros idiomas.
En realidad, las computadoras son más capaces de procesar la información que las personas. Pueden procesar muchísimos más grandes volúmenes de información que una persona puede leer en su vida. A base de ésta, pueden hacer inferencias lógicas tomando en cuenta más hechos y más fuentes.
Todo parece estar preparado para el uso de las computadoras para procesar volúmenes grandes de información: los métodos lógicos ya son muy fuertes, los procesadores muy rápidos, muchos textos ya están disponibles en forma digital, tanto en las casas editoriales como en Internet. El único problema para la computadora al procesar los textos es que simplemente ¡no los entiende! Hasta ahora, los textos son para la computadora solamente cadenas de letras sin cualquier sentido y no una información útil para el razonamiento lógico.
Para convertir la computadora en nuestro verdadero ayudante en el procesamiento de textos, se necesita pasar un largo camino de aprendizaje de la estructura de textos y de su formalización; más abajo vamos a hablar de algunos problemas en este camino. Pero si es tan largo el camino, ¿existe una razón práctica para trabajar en esta área ahora? Sí, existe, porque con cada paso obtenemos las herramientas que ya tienen gran valor práctico, que ayudan en nuestras tareas cotidianas.
1 Tareas y aplicaciones de procesamiento de lenguaje natural
¿Para qué sirve el procesamiento automático de lenguaje natural? En la práctica, se puede emplear en un rango muy amplio de tareas, desde bastante simples a las muy complejas. Las tareas simples ya se pueden hacer con el estado actual de la ciencia, aunque no perfectamente. Las tareas más complejas son las metas a alcanzar en el futuro. Sin embargo, las tareas simples también aprovechan los avances de la ciencia, como vamos a ver más abajo.
Consideramos aquí algunas de estas tareas, desde las más simples hasta las más complejas. Con cada una, mencionaremos los problemas lingüísticos que existen en esta tarea, es decir, en qué puede aprovechar el avance de la ciencia y la tecnología.
1.1 Ayuda en preparación de textos
Este tipo de aplicaciones es conocido hoy en día por quizás toda la gente que por lo menos una vez ha usado la computadora. Hablamos de las herramientas que proporcionan los procesadores de palabras como Microsoft Word. Aquí, sólo nos interesan las herramientas que emplean el procesamiento complejo de texto y requieren conocimiento lingüístico.
Guiones. La tarea de determinar los lugares donde las palabras se pueden romper para empezar una nueva línea es una de las más simples en procesamiento de textos. Por ejemplo, se puede romper la palabra como mara-villoso o maravillo-so, pero no maravil-loso o maravillos-o.
A pesar de ser un problema simple, a veces requiere una información bastante profunda. Por ejemplo, se debe saber cuáles son el prefijo y la raíz de la palabra: su-bir y sub-urbano, pero no sub-ir o su-burbano. O bien, a veces se debe saber el idioma del origen de la palabra: Pe-llicer, pero Shil-ler. También se debe saber la estructura del documento ya que quizás no se deben usar guiones en los títulos y encabezados.
Ortografía. La tarea de averiguar si una palabra está escrita correctamente o con un error ortográfico es un poco más difícil que la de los guiones. Por lo menos se debe saber todas las palabras del idioma dado. Ya que no es posible saber literalmente todas las palabras, se debe saber en primer lugar las formas de palabras, como inteligentísimas, satisfechos, piensen, etc.
Pero para detectar los errores de ortografía, o simplemente de escritura, se debe considerar el contexto de la palabra de una manera a veces bastante complicada. Ejemplos: Sé que piensen en el futuro. El terremoto causó una gran hola en el mar. Se iba a cazar con su novia en la iglesia bautista. Para detectar este tipo de errores, la computadora necesita hasta entender en cierto grado el sentido del texto.
Gramática. Los correctores de gramática detectan las estructuras incorrectas en las oraciones aunque todas las palabras en la oración estén bien escritas en el sentido de que son palabras legales en el idioma, por ejemplo: Quiero que viene mañana. El maestro de matemáticas, se fue. Me gusta la idea ir a Europa. Fuera magnífico si él venía a la fiesta.
El problema de detectar los errores de este tipo es que hay una gran variedad de estructuras permitidas, y enumerarlas todas resulta muy difícil. Para describir las estructuras de las oraciones en el idioma, se usan las llamadas gramáticas formales – los conjuntos de reglas de combinación de palabras y su orden relativo en las oraciones.
Estilo. Una tarea ya más complicada es detectar los problemas en el texto que consiste de las palabras correctamente escritas y las oraciones correctamente estructuradas, pero que es poco leíble, ambiguo, mal estructurado, inconsistente en el uso de palabras de diferentes estilos. Por ejemplo, el texto científico no debe usar las palabras de jerga; una carta a un amigo no debe usar las oraciones muy largas, profundamente estructuradas, con muchas palabras científicas.
Un ejemplo de una oración ambigua es «Detectar los errores en el texto con estructuras complejas»: sería mejor decir «Detectar los errores en el texto que tiene estructuras complejas» o «Detectar en el texto los errores que tienen estructuras complejas» o bien «Detectar a través de las estructuras complejas los errores en el texto». Para este tipo de procesamiento, en ciertas circunstancias hay que emplear un análisis bastante profundo.
Hechos y coherencia lógica. Probablemente en el futuro los correctores de texto serán capaces de encontrar los errores en los textos como éstos: «Cuando voy a Inglaterra, quiero visitar París, la capital de este país». «Primero vino Pedro y después José; ya que José llegó antes de Pedro, tomó el mejor asiento». Sin embargo, en el estado actual de procesamiento de lenguaje natural, no se puede todavía crear herramientas de este tipo suficientemente desarrolladas para ser útiles en la práctica.
1.2 Búsqueda y minería de texto
La búsqueda y el uso de la información contenida en el texto es una de las aplicaciones principales del análisis de texto. Las aplicaciones de este tipo varían desde las herramientas de búsqueda que simplemente ayudan al usuario a encontrar los documentos probablemente relevantes hasta las computadoras investigadoras que descubren el conocimiento nuevo que no está escrito en ninguno de los documentos disponibles.
Búsqueda de documentos. Los motores de búsqueda permiten encontrar en un montón de documentos aquellos que satisfagan una necesidad del usuario descrita en su petición. En el caso simple, la petición contiene las palabras clave, como «pensar y futuro», que quiere decir que el usuario necesita los documentos que contengan ambas de estas dos palabras. Hasta en este caso simple, se necesita un análisis bastante complejo: los documentos que contienen las palabras futuras, piensan y probablemente pensador y pensamiento también son relevantes. Si el usuario indica que necesita los documentos que dicen sobre la acción «pensar en futuro», entonces el documento que contiene la frase como «piensan en las futuras aplicaciones» probablemente es relevante, mientras que «en el futuro próximo voy a pensarlo» probablemente no lo es. Para hacer esta decisión, un análisis profundo del texto es necesario.
Además de los problemas lingüísticos, la búsqueda eficaz de documentos depende de las soluciones técnicas. No es posible analizar todos los documentos cada vez que el usuario hace su pregunta. Entonces, se hace y se maneja un índice de los documentos, es decir, una representación corta, simple y formal de los documentos. La representación de este índice, el tipo de información incluida en él, y los métodos matemáticos que se emplean en la búsqueda en él afectan mucho los resultados y eficiencia del proceso.
Responder preguntas. En lugar de buscar los documentos para encontrar en ellos la respuesta a su pregunta, el usuario podría desear directamente hacer su pregunta a la computadora: «¿Cómo se llama la reina de España?» Por supuesto se espere que la computadora encuentre en todos los artículos de periódicos la información sobre el rey de España, detecte cuáles de éstos tratan del último rey, y dónde se dice como se llama su esposa. Los sistemas de razonamiento lógico ya son capaces de este tipo de inferencia, pero el estado actual de la ciencia lingüística no es suficiente bueno para la realización de semejantes sistemas a gran escala.
Extracción de información. Lo que es más práctico hacer en el estado actual es encontrar en el texto proposiciones elementales, bastante simples, para compilar una base de datos a partir de un conjunto grande de texto. Por ejemplo, a partir de los periódicos, compilar una base de datos de las compras y ventas de compañías, o de los precios de abarrotes en las diferentes ciudades del país, etc. Claro está que para esta tarea, cierto entendimiento del lenguaje es necesario.
Minería de texto. La minería de texto consiste en descubrir, a partir de cantidades de texto grandes, el conocimiento que no está literalmente escrito en cualquiera de los documentos. Esto incluye buscar tendencias, promedios, desviaciones, dependencias, etc. Es el área emergente, y muy interesante, del procesamiento de texto y minería de datos.
Por ejemplo, con los métodos de minería de texto, a partir de los textos de periódicos mexicanos encontrados en Internet, se podría investigar preguntas como las siguientes: ¿Es la opinión promedio en la sociedad sobre el asunto del FOBAPROA positiva o negativa?, ¿Aumenta o disminuye el interés en este asunto en los últimos meses? ¿Hay diferencias en la actitud hacia este asunto en el D.F. y en Monterrey? ¿Cómo la noticia de privatización de la industria eléctrica afecta el interés social hacia el FOBAPROA? [8].
Las tareas de este tipo necesitan un grado de comprensión de texto, aunque en muchos casos basta con una comprensión parcial, de algunos pedazos de las oraciones.
1.3 Comprensión del lenguaje
La comprensión verdadera del texto es, en cierto sentido, la tarea final de la ciencia del análisis de texto. ¿Qué es comprensión? ¿Cómo podemos averiguar si una computadora comprende un texto? Hay varias opiniones, pero parece que la opinión más común entre la gente técnica es la siguiente: comprensión de texto es la transformación del mismo a una representación formal, ya sea a una red de conceptos y sus relaciones, o a un conjunto de predicados lógicos, etc. Como se discutirá más abajo, esta representación formal luego puede ser usada por los sistemas existentes de razonamiento lógico para contestar preguntas, compilar resúmenes, etc.
En el presente estado del arte, los resultados prácticos en comprensión de texto son relativamente modestos, pero hay mucho avance en los sistemas de laboratorio, y el esfuerzo principal en lingüística computacional está dirigido a esta tarea global.
1.4 Interfaces en lenguaje natural
Tradicionalmente, las personas manejan las computadoras con lenguajes especiales –lenguajes de programación– que son entendibles para las computadoras, pero... ¡no para las personas! Cada uno de nosotros tiene que aprender un idioma extranjero más – el idioma de las computadoras. No es cómodo, no es fácil de aprender, la educación computacional cuesta mucho dinero, pero es el único modo para comunicarse con las computadoras.
Ahora llegó el tiempo para que las computadoras aprendan nuestro lenguaje humano. Esto permitirá usar computadoras a la mayoría de la gente no especialista. Además, es más simple enseñarle a una sola computadora nuestro idioma y copiar el programa a todas las computadoras, que enseñar a todas las personas como usar las computadoras. También habilita a usar los medios de comunicación más comunes, por ejemplo, el teléfono, para usar los sistemas de información.
Los sistemas de interface en lenguaje natural tienen una historia de más de treinta años, pero sólo ahora, con los avances tanto en modelos de diálogo como en reconocimiento de voz, se hizo posible construir los sistemas que se usan en la práctica, por ejemplo, el sistema reciente TRAINS de J. Allen. Los sistemas de este tipo usualmente se concentran en un dominio –se dice «el mundo»– muy simple: uno de los primeros programas de T. Winograd tuvo como dominio el mundo de figuras geométricas sobre una mesa, mientras que en el sistema TRAINS se trata del horario de trenes y planificación de las rutas de ferrocarriles. El propósito del sistema es el uso en las centrales de información: la gente podrá llamar al sistema por teléfono y preguntar sobre cómo ir de Nueva York a Los Angeles, cuáles clases de trenes hay, dónde comprar los boletos, etc.
Evidentemente, los sistemas de interface se van a desarrollar muy rápido, y probablemente las computadoras del futuro próximo serán manejadas más con voz que con el teclado y ratón.
1.5 Traducción automática
En los últimos años, la calidad de la traducción automática ha mejorado dramáticamente. En el caso ideal, el traducir un texto consiste en entender este texto –en el sentido de transformarlo en una representación formal– y luego generar el texto, según el sentido entendido, en el otro idioma.
En el estado actual, generalmente no es posible entender todo el texto, con todas las relaciones entre los conceptos mencionados en él. Entonces, los traductores automáticos entienden algunas partes del texto, más grandes o más pequeñas, y las traducen en el orden en que aparecen en el texto fuente.
En muchos casos este no es suficiente. Por ejemplo, para traducir las oraciones como
John took a cake from the table and ate it.
John took a cake from the table and cleaned it.
se necesita realmente entender qué hizo John: tomó un pastel de la mesa y ¿lo comió o la comió? ¿lo limpió o la limpió? Al revés, para traducir el texto Juan le dio a María un pastel. Lo comió, hay que elegir entre las variantes He ate it, She ate it, It ate him, She ate him, etc.
1.6 Procesamiento de voz
¿De qué fuente viene la información para el procesamiento de lenguaje natural?
Más arriba, hablamos de la información en lenguaje natural y del texto como si fueron conceptos sinónimos: el conocimiento es algo escrito en un libro o archivo, no es algo hablado, ¿verdad? En la etapa contemporánea de la civilización sí, así es, pero no por la naturaleza del lenguaje. El modo más natural de comunicación para un ser humano es hablar y escuchar, no es escribir y leer. Tenemos que escribir y leer porque en esta forma podemos realizar las tareas principales de procesamiento de información: buscarla y compararla. También, la voz representa más información que el texto escrito: con entonaciones de la voz expresamos el énfasis, propósitos, relaciones lógicas que se pierden en el texto.
Hoy en día en los sistemas prácticos para los usuarios generales, cada vez más se usa la fuente alternativa de información: la voz. A pesar de los grandes problemas técnicos de convertir los sonidos de la voz a las palabras, hay grandes avances en este campo, y ya existen los sistemas capaces de hablar con los usuarios, incluso por ejemplo a través de teléfono. Si en el futuro remoto será fácil buscar y manejar la información en forma de lenguaje hablado, ¿quién sabe si los libros de aquel tiempo no serán dispositivos que nos contarán con la voz su contenido?
1.7 Generación de texto
¿Cómo puede la computadora comunicarle al usuario sus opiniones o pedirle información?
El complemento natural a la capacidad de entender el lenguaje es el segundo componente de la comunicación, que es la capacidad de producir el texto o bien el habla. En cierto grado es una tarea más simple que la comprensión, ya que por lo menos la computadora puede elegir las expresiones que sabe producir.
Uno podría pensar que para la generación de texto sólo es suficiente saber las reglas de gramática, es decir, saber palabras de cuales números, tiempos y géneros hay que usar en la oración y en que orden ponerlas. Sin embargo, hay algunos problemas en la generación de texto. Uno reside en la necesidad de elegir las palabras y expresiones que «se usan» en el contexto dado. Por ejemplo, hay que saber que para expresar la idea ‘muy, mucho’, hay que usar palabras diferentes: té cargado, voz alta, borracho como cuba, trabajar duro [3].
El otro problema es que el texto producido con los métodos de fuerza bruta es aburrido, incoherente y a veces no entendible. Hay que saber en qué ocasiones se deben usar los pronombres y en qué otras las palabras completas, en qué ocasiones hay que explicar, de qué se trata la oración y en qué otras es entendible para el lector. Esto se refiere a los métodos de la nombrada planificación textual.
1.8 Conducción de diálogo
Bueno, si la computadora aprende a entender y producir el texto, ¿ya puede conversar con las personas?
El problema es que en las situaciones de conversación no hablamos con los textos, es decir, con los párrafos, capítulos y documentos. Hablamos con réplicas cortas, y la mayoría de la información omitida es clara en el contexto previo, en la situación y en las acciones de los participantes, y en el conocimiento general sobre estos tipos de situaciones. Un diálogo en una cafetería podría ser: «¿De manzana?» – «Piña.» – «¡Por favor!» – «¿Este?» – «El otro.» – «Dos pesos más.» Claro que entender este tipo de conversación y participar en ella es una tarea muy diferente, y por supuesto más difícil, que entender un artículo con la introducción, definiciones de los términos y un flujo lógico de las ideas.
2 Problemas de procesamiento de lenguaje natural
Ya hemos visto que el procesamiento automático de lenguaje natural tiene gran importancia y utilidad. Entonces, ¿por qué no se ha hecho? ¿Cuáles problemas existen en esta área? ¿Cómo se abordan?
2.1 Niveles de lenguaje y estructura del procesador lingüístico
El propósito del lenguaje es transferir conocimientos de una persona a otra. El conocimiento es una estructura compleja, multidimensional, que usualmente se representa como una red, o grafo, de conceptos. Pero el modo que usamos para transferir el conocimiento es unodimensional: en cada momento sólo podemos decir un sonido, una letra. Entonces, el trabajo del lenguaje es codificar el conocimiento multidimensional en una cadena de letras, y después, en el cerebro del escuchante o el lector, decodificar esta secuencia en el conocimiento original, como se muestra en la Ilustración 1.
El lenguaje es una estructura muy compleja. Afortunadamente, el codificador y decodificador funcionan en pasos, construyendo las estructuras más complejas de ladrillos más simples:
- Palabras de letras,
- Oraciones de palabras,
- Textos de oraciones.
Como ya hemos mencionado, un programa para análisis automático de textos desempeña un papel semejante: traduce el texto a las estructuras lógicas, o bien formales. Semejante programa puede modelar, en cierto grado, el efecto del procesamiento de texto en el cerebro humano –no su estructura física y los procesos físico-químicos que acompañan la actividad del cerebro, sino la lógica de su procesamiento de texto y conocimiento.
|
Ilustración 1. El lenguaje es un codificador-descodificador. |
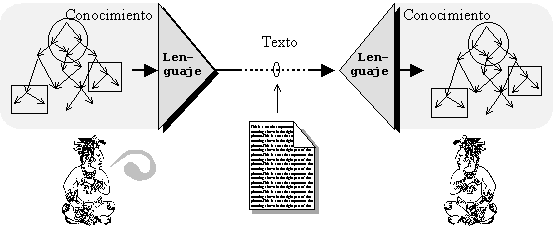
Un programa que traduce el texto a la representación lógica y vice versa, se llama procesador lingüístico. El procesador lingüístico no hace ningún razonamiento lógico, no busca información, no maneja las bases de datos, sino sólo traduce la información entre la representación textual y la representación formal equivalente, para que los programas de razonamiento, los sistemas expertos etc. hagan todas las operaciones lógicas mencionadas.
La estructura del lenguaje se refleja en la estructura del procesador lingüístico. Tradicionalmente se considera dividido en módulos independientes:
- El módulo morfológico reconoce las palabras y las convierte de cadenas de letras a números en el diccionario y a marcas de tiempo, género, número, etc. Toma como entrada el texto y pasa su salida –representación morfológica– al módulo siguiente.
- El módulo sintáctico reconoce las oraciones y las convierte de cadenas de palabras marcadas a las estructuras gráficas de oraciones, con las marcas de sujeto, objeto, etc. y las relaciones entre las palabras en la oración. Toma como entrada la representación morfológica y pasa su salida –representación sintáctica– al módulo siguiente.
- Los módulos semántico y pragmático reconocen la estructura completa del texto y lo convierten a una red semántica. Resuelven las relaciones entre los pronombres y sus antecedentes, restauran los sujetos cero, etc., reconocen las intenciones del autor. Toman como entrada la representación sintáctica y generan la salida del procesador lingüístico.
En cada paso existen problemas técnicos y teóricos, algunos ya resueltos en cierto grado, y algunos a resolver en el transcurso del desarrollo de la ciencia.
2.2 El problema de ambigüedad
Uno de los problemas más grave es la ambigüedad del texto: un pedazo del texto puede tener más de una interpretación. Se presenta muy a menudo, en casi cada oración. Aquí están unos ejemplos de la ambigüedad léxica, es decir, de palabras: habla, aviso – ¿verbo o sustantivo? hablamos – ¿presente o pasado? Aquí está un ejemplo de ambigüedad sintáctica, es decir, de la estructura de la oración: Veo al gato con el telescopio. – ¿‘uso telescopio para ver al gato’ o ‘veo al gato que tiene el telescopio’? En casi cada oración que tiene una preposición se presenta la ambigüedad de este tipo: no es claro si la preposición está ligada con el verbo, o con el objeto, o con el adjetivo, etc.
En cierto grado podemos decir que el problema principal del análisis automático de texto es resolver las ambigüedades. Para resolverlas, se emplean varias consideraciones sobre la posibilidad y probabilidad de una variante u otra, y las oportunidades de las variantes se comparan. Por lo general, la calidad de la resolución de ambigüedades es proporcional a la información disponible, de varias naturalezas y desde varias fuentes [9].
2.3 Complejidad del conocimiento lingüístico
Hay dos tipos de conocimiento necesario para el reconocimiento de las estructuras en el texto y para la resolución de ambigüedades en éstas: el conocimiento general y el conocimiento léxico. El conocimiento general son los algoritmos y las gramáticas, es decir, lo que se aplica a todo el lenguaje, a cualquier oración o texto. Gramáticas detalladas y algoritmos muy sofisticados, con una profunda base matemática pueden mejorar mucho la eficiencia de análisis de texto. Pero aunque los buenos algoritmos pueden aumentar la rapidez del proceso, en pocos casos pueden ellos mejorar la calidad de los resultados. Jamás un algoritmo astuto podrá entender el lenguaje sin un inmenso conocimiento sobre las palabras individuales.
El conocimiento léxico es específico para cada palabra, o a veces para grupos de palabras. Dependiendo de la calidad de análisis necesario, se puede requerir mucha información: cómo se conjuga la palabra, qué significa y qué relaciones impide a otras palabras en la oración, qué preposiciones usa para marcar sus objetos, cuáles palabras se usan para expresar los sentidos como ‘muy’, ‘hacer’, ‘resultado’, etcétera. La mayoría de esta información es específica para cada idioma: por ejemplo, casarse en español requiere la preposición con, en inglés el equivalente de a, en ruso de sobre; papel (rol) en español usa desempeñar para expresar el sentido de ‘hacer’, y en inglés el equivalente de jugar.
Uno de los problemas contemporáneos del procesamiento de texto es que la cantidad del conocimiento léxico necesario es tan inmensa que resulta muy difícil alcanzar el grado necesario de conocimiento en un sistema específico. La compilación, ya sea manual o semiautomáticamente, de los diccionarios de varios tipos –morfológicos, sintácticos, semánticos– es una de las más importantes tareas de hoy en la lingüística computacional.
|
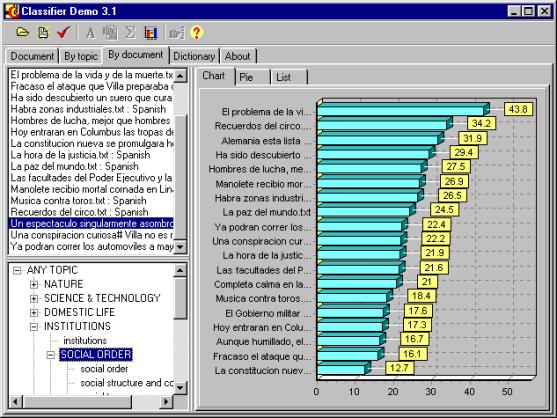
Ilustración 2. El sistema CLASSIFIER. |
Lo bueno es que esto no parece ser un problema insoluble: con el tiempo la humanidad acumulará los diccionarios hasta una cantidad suficiente; y cada nuevo diccionario o método de aprendizaje semiautomático de los diccionarios a partir de los textos nos acerca a la tarea final.
2.4 Conocimiento extralingüístico
Pero los diccionarios de las propiedades gramaticales de las palabras no son el único conocimiento necesario para entender el lenguaje. Lo que falta es el conocimiento de las propiedades de las cosas y de las situaciones en el mundo real. El problema es que el texto no comunica toda la información necesaria para entenderlo, sino que omite muchas ideas obvias, las cuáles se pueden simplemente restaurar por el humano que escucha... pero no por la computadora.
Consideremos una analogía. Cuando explicamos a alguien cómo ir al Metro, le decimos algo como esto: «Del Angel vas por Reforma dos paradas en la dirección opuesta a la Diana, bajas en el Caballito y das vuelta a la derecha». Tenemos en nuestra mente un mapa, y estamos seguros que el que oye también tiene en su mente un mapa igual al nuestro; lo único que necesitamos es darles unas pistas sobre su trayectoria en este mapa, unos puntos clave. Ahora bien, ¿qué sucederá si el que oye es un extranjero y no sabe ni qué son el Angel o la Diana, ni como llegar allá, ni siquiera cómo usar los peseros, cómo se ven, dónde subir, ni que hay que pagar y cuánto? Ésta es la situación de las computadoras: son extranjeras en nuestro mundo, no saben cómo usarlo, cómo se comportan las cosas en él. Las personas lo aprenden observando las cosas y participando en las situaciones. Las computadoras no tienen esta oportunidad.
|
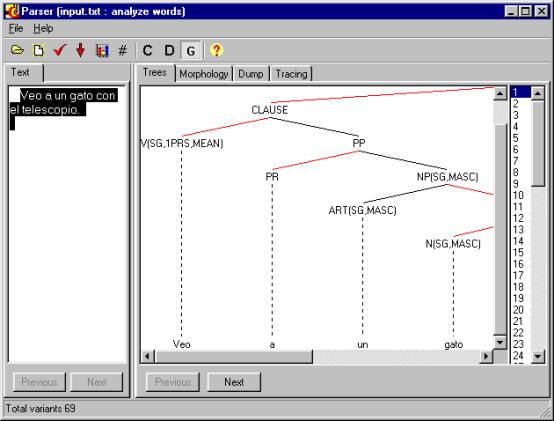
Ilustración 3. El sistema PARSER. |
Entones, nuestro texto es una línea de puntos, no es una trayectoria completa. Es el modo humano de hablar. No lo podemos cambiar. Siempre suponemos que hablamos con alguien que sabe del mundo casi todo lo que nosotros sabemos.
Ahora el problema es comunicarles a las computadoras este conocimiento humano del mundo real, por supuesto en la forma de diccionarios de relaciones entre objetos y de escenarios de las situaciones típicas. Estos diccionarios serán mucho más grandes de lo que hablamos en la sección anterior, y su compilación es una tarea a largo plazo, aunque ya existen unos diccionarios de este tipo. Como una alternativa posible, se pueden desarrollar métodos de aprendizaje semiautomático de esta cantidad enorme de conocimiento a partir de colecciones muy grandes de textos.
3 Procesamiento de lenguaje natural en el CIC
En 1996, el Director del Centro de Investigación en Computación, el Dr. Guzmán Arenas fundó el Laboratorio de Lenguaje Natural y Procesamiento de Texto del CIC. ¿Para qué? ¿Qué se hace ahora en el Laboratorio?
3.1 El camino al futuro
Como hemos visto, el procesamiento de texto tiene gran importancia tanto teórica como práctica. El procesamiento de lenguaje natural se usa para tomar decisiones económicas, para buscar e intercambiar el conocimiento tecnológico, en toda clase de tareas de publicación y uso de documentos, libros, periódicos. Los países que disponen de buenas herramientas para el análisis y generación de texto tienen en nuestro mundo competitivo una gran ventaja económica, tecnológica y quizás militar sobre los demás países. Desgraciadamente, ahora la mayoría de las investigaciones y el esfuerzo práctico en el mundo en el área de la lingüística computacional está orientada al inglés.
|
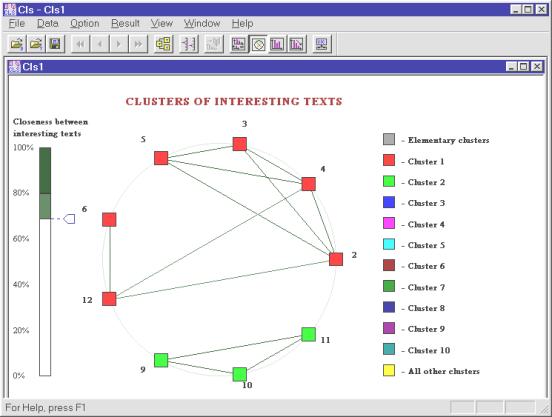
Ilustración 4. El sistema Text Classifier. |
La tarea de nuestro laboratorio es compilar los recursos –las gramáticas y sobre todo los diccionarios– que facilitan el procesamiento de texto en español, y desarrollar los sistemas para la búsqueda, clasificación y comprensión de documentos escritos en español. A continuación mencionamos algunos de los programas desarrollados recientemente en el laboratorio.
3.2 Hallando los temas principales del documento
Uno de los primeros pasos para clasificación, búsqueda y comprensión de documentos es determinar de qué temas trata un documento dado. En la Ilustración 2 se muestra el sistema desarrollado según las ideas del Dr. Guzmán Arenas, que usa un diccionario jerárquico para hallar los temas principales del documento, para comparar los documentos con un aspecto temático, y para buscar los documentos por sus temas [1, 2].
|
Ilustración 5. El sistema Text Recognizer. |
En la figura se muestra un histograma de la semejanza de los artículos de la colección del periódico El Universal al artículo elegido, con el aspecto elegido.
3.3 Análisis sintáctico conducido por un diccionario de subcategorización
El análisis sintáctico es el núcleo de los sistemas contemporáneos de análisis de texto. En la Ilustración 3 se muestra el analizador sintáctico para el español desarrollado en nuestro laboratorio. Una de las líneas de investigación en el laboratorio es la compilación de un diccionario grande del uso de las preposiciones (y de algunas características de las palabras) para resolver las ambigüedades sintácticas [5, 6, 7]. Esta línea de investigación incluye también otros varios métodos de estimación de las variantes de la estructura sintáctica, tal como el uso de un diccionario semántico grande, con el fin de elegir las variantes más probables [4].
En la figura se muestra una variante de la estructura sintáctica de una oración simple en español.
3.4 Clasificación e investigación de conjuntos de documentos
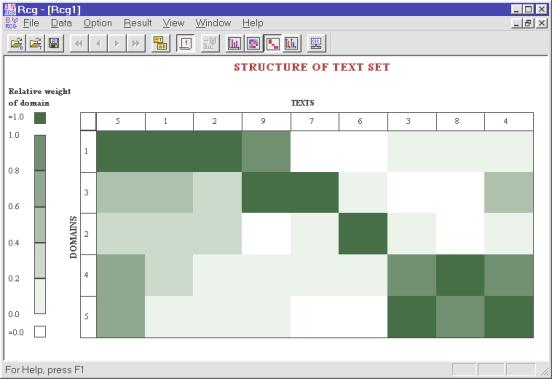
El otro sistema que se está desarrollando en el laboratorio es un conjunto de herramientas para la investigación de colecciones de documentos de forma tanto automática como semiautomática. Para la clasificación semiautomática se usa la representación gráfica del conjunto de documentos.
En la Ilustración 4 se muestra un conjunto de documentos clasificado automáticamente, con los vínculos entre los documentos, para que el usuario pueda elegir los parámetros de clasificación. En la Ilustración 5 se muestra el conjunto de documentos con la representación gráfica de cada uno en las columnas; las filas corresponden a diferentes dominios temáticos. El conjunto está agrupado semiautomáticamente, y se puede ver las dependencias entre los grupos de los documentos y los grupos de los dominios temáticos.
4 El futuro del procesamiento automático de lenguaje natural
Ya hay mucho avance en el área de procesamiento automático de lenguaje natural. ¿Cuáles son las líneas de su desarrollo en el futuro? ¿Cuál es su papel en la tecnología del futuro?
4.1 Semántica y pragmática
Hoy en día, la rama de la lingüística computacional que se desarrolla más dinámicamente es la sintaxis. Creemos que en el futuro próximo el énfasis se moverá a la teoría de semántica y pragmática del texto. La semántica estudia el significado del texto y desarrolla los métodos para formar este significado a través de una serie de representaciones sintácticas de las oraciones.
La pragmática estudia cómo las intenciones del autor del texto están expresadas en el texto. Cuando uno en la mesa hace la pregunta «¿Me podría pasar la sal?», la respuesta «Sí, soy capaz técnicamente de pasarle la sal.» no es la debida ¿Cómo puede la computadora saber la intensión, o la necesidad del usuario en los casos donde no están muy claramente y directamente expresadas en el texto? Esto es la materia de la pragmática.
4.2 Lingüística de texto
Se considera la ciencia del siglo veintiuno la lingüística de texto. Ésta estudia los medios de conexión de las oraciones en un flujo integral de texto. ¿Cómo están expresadas las ideas cuando están divididas entre varias oraciones? ¿Cómo las personas saben en qué pedazos hay que dividir una idea compleja para expresarla en oraciones distintas, porque no la expresan en una sola oración larguísima? ¿Cómo reunir estos pedazos del sentido para restaurar el sentido original? Esto es la materia de la lingüística de texto, la ciencia lingüística del siglo que viene.
4.3 Hablar es: saber más pensar
Ahora bien, si desarrollamos todos los diccionarios, las gramáticas, los algoritmos lingüísticos – ¿ya es suficiente para que la computadora nos entienda y hable como nosotros hablamos? No. Para entender y hablar, el brillante dominio del idioma no es suficiente – hay que saber mucho, y hay que pensar. En el futuro se necesita una síntesis de las ciencias de lenguaje y las ciencias de razonamiento. En este camino lograremos nuestra tarea: convertir las computadoras en nuestros verdaderos ayudantes en la ocupación principal de la raza humana – pensar y comunicar.
4.4 Las computadoras hablan con nosotros
La tarea final de lingüística computacional es el desarrollo de los robots que pueden actuar en el mundo real –el mundo de las cosas y de las personas– en el modo parecido al modo en que actuamos las personas. Para vivir en el mundo de las cosas, un robot necesita poder distinguirlas y afectarlas con sus acciones. Pero para vivir en el mundo de las personas, también necesita entenderlas y afectarlas... pero en este caso, a través de lenguaje, pues éste es nuestra manera de entender y afectar a las personas.
El desarrollo de tales sistemas tiene grandes ventajas tanto para la practica como para la ciencia. Para la practica, habilitará a todas las personas obtener la ayuda de las máquinas sin aprender manejarlas, regularlas y programarlas. Es mucho más barato una vez desarrollar una maquina, aunque muy muy compleja, y copiar su programa a millones de las máquinas iguales a ésta, que educar a millones de personas cómo programar una máquina simple.
Para la ciencia, el desarrollo de los robots autónomos permitirá verificar las teorías de lenguaje en su funcionamiento real, observando cómo los programas que entienden y producen el lenguaje logran sus tareas, en qué situaciones tienen problemas y cómo las resuelven.
4.5 Las computadoras hablan... ¡entre sí!
De todo de que hemos hablado, se produce la impresión de que el uso de lenguaje natural –¡tal natural para nosotros!– es un agobio totalmente innecesario para las computadoras; tienen que aprender nuestro lenguaje –el español, inglés o que sea– sólo porque somos demasiado perezosos para aprender su lenguaje –Java o C++. ¿Acaso así es? ¿Sólo nuestro lenguaje es bueno para las criaturas de proteínas y no es útil para todos los demás?
Miremos al desarrollo de programación en su retrospectiva. Con cada nuevo paradigma de programación, del Ensamblador, a través de la programación estructural y hasta la programación orientada a objetos, los programas o partes de programas se hicieron cada vez más autónomos, aislados, mientras sus interfaces se hicieron cada vez más desarrolladas y complejas. Un objeto complejo en C++ ya tiene una interfaz semejante a un lenguaje, y el uso del objeto parece a un diálogo con él. El siguiente paso en el desarrollo de los métodos de programación es el emergente paradigma de programación orientada a agentes.
Un agente es parecido a un objeto, pero en lugar de muchos órdenes (métodos) de un objeto, tiene sólo una entrada –entiende un mensaje en un lenguaje especial, y sólo tiene una salida –puede enviar mensajes a otros agentes. Este permita mucho más flexibilidad en la comunicación con entre los agentes que los órdenes de formato fijo de los objetos.
Ahora bien, como los agentes típicamente son los programas muy complejos, algunos de éstos se desarrollan por los equipos grandes de programadores y lo que es más importante, los equipos diferentes. Para que los agentes comuniquen, necesitan usar el mismo lenguaje. Entonces, se necesita un estándar para el lenguaje de comunicación entre los objetos –un estándar fijo, exacto, rígido, para todas las tareas que los agentes hacen o van a hacer en el futuro. ¿Ya es un círculo vicioso: buscamos la flexibilidad y llegamos a un estándar fijo, por supuesto muy complejo, que, además, todos los equipos que desarrollan los objetos lo deben aprender? Pero ya contamos con un lenguaje muy flexible (aunque complejo), un lenguaje especialmentebueno para la comunicación en las situaciones complejas y –lo mejor– ya conocido por todos los desarrolladores. Es el lenguaje natural. Por eso hay mucho interés entre tanto los científicos en la ciencia de computación como los programadores prácticos al lenguaje natural, en primer lugar, a su semántica y las ontologías de las palabras [10]. Probablemente en el futuro, aunque no muy próximo, las computadoras van a hablar en lenguaje natural entre sí.
5 Conclusiones
Entonces, el procesamiento de lenguaje natural es difícil, pero es posible y tiene una gran importancia para los países hispanohablantes en nuestro mundo competitivo, en nuestra época de información. Es un área de la ciencia que se desarrolla muy dinámicamente, con grandes inversiones, con miles de investigadores involucrados en los países industriales, en primer lugar, en los Estados Unidos y en la Comunidad Europea.
Ahora en el Politécnico, en el CIC, se conduce investigación en la lingüística computacional en el Laboratorio de Lenguaje Natural y Procesamiento de Texto. Los investigadores de este Laboratorio se pueden contactar a la dirección electrónica gelbukh(?)cic.ipn.mx.
1. Adolfo Guzmán-Arenas. Hallando los temas principales en un artículo en español. Soluciones Avanzadas. Vol. 5, No. 45, p. 58, No. 49, p. 66, 1997.
2. Adolfo Guzmán-Arenas. Finding the main themes in a Spanish document. Journal Expert Systems with Applications, Vol. 14, No. 1/2. Jan/Feb 1998, pp. 139-148.
3. I. A. Bolshakov, A. Gelbukh. Lexical functions in Spanish. CIC-98 - Simposium Internacional de computación, November 11 - 13, 1998, México D.F., pp. 383 - 395.
4. Alexander Gelbukh. Using a semantic network for lexical and syntactic disambiguation. Proc. of Simposium Internacional de Computación: Nuevas Aplicaciones e Innovaciones Tecnológicas en Computación, November 1997, México.
5. A.Gelbukh, I. Bolshakov, S. Galicia-Haro. Statistics of parsing errors can help syntactic disambiguation. CIC-98 - Simposium Internacional de Computación, November 11 - 13, 1998, México D.F., pp. 405 - 515.
6. I.A. Bolshakov, A.F. Gelbukh, S.N. Galicia-Haro. Syntactical managing patterns for the most common Spanish verbs. CIC’97, Nuevas Aplicaciones e Innovaciones Tecnológicas en Computación, Simposium Internacional de Computación, 12-14 de noviembre, pp. 367 - 371, 1997, CIC, IPN, México D.F.
7. I. A. Bolshakov, A. Gelbukh, S. Galicia Haro, M. Orozco Guzmán. Government patterns of 670 Spanish verbs. Technical report. CIC, IPN, 1998.
8. Manuel Montes y Gómez, Aurelio López López, Alexander Gelbukh. Text Mining as a Social Thermometer. Text Mining Workshop (forthcoming) at IJCAI'99, Stockholm, August, 1999.
9. A. Gelbukh, S. Galicia-Haro, I.Bolshakov. Three dictionary-based techniques of disambiguation. TAINA-98, International Workshop on Artificial Intelligence, CIC-IPN, México D.F., pp. 78 - 89.