Resumen[1]
Se presenta la aplicación del formalismo de la Teoría Texto Û Significado (MeaningÛ Text Theory) al análisis sintáctico del español. En este método, basado en gramáticas de dependencias, se emplea un diccionario combinatorio para el análisis sintáctico, compuesto de patrones para palabras, principalmente verbos, donde se describen todas sus valencias, sintácticas y semánticas, y las formas en que ellas se realizan. Estos patrones no solamente ayudan a reducir el número de posibles variantes generadas sino que permiten detectar información del nivel sintáctico que está conectada con la semántica de la palabra y que es requerida a niveles más profundos del análisis de lenguaje natural.
Presentamos las bases metodológicas y las herramientas necesarias para la aplicación de este formalismo al español. Aportamos una nueva forma de descripción de los patrones para incluir características cualitativas. A partir de un corpus se recopila información estadística de las realizaciones de cada valencia y de las combinaciones de valencias para cada verbo con el propósito de incrementar la eficiencia del analizador sintáctico. Se presentan algunos ejemplos para ilustrar esta aplicación.
1. Introducción
Para la representación de la estructura sintáctica, las investigaciones para el análisis sintáctico por computadora del inglés adoptaron las estructuras consideradas por las teorías lingüísticas derivadas del estructuralismo norteamericano, basadas en constituyentes o estructura de frase. Esas teorías lingüísticas también han sido empleadas para la representación sintáctica de otros lenguajes (alemán, francés, etc.). En cambio las teorías lingüísticas desarrolladas a partir de los estudios de [Tesnière, 59], las gramáticas de dependencias, no han sido ampliamente empleadas.
La estructura de subcategorización se ha considerado como una información lingüística básica necesaria en los diccionarios para el procesamiento de lenguaje natural [EAGLES, 96], principalmente se han empleado con la finalidad de restringir el número de variantes generadas en el análisis sintáctico y para la generación de textos. Los marcos de subcategorización que se han compilado con este propósito, manualmente ALVEY [Boguraev, 87] y COMLEX [Grishman et al, 94], y automáticamente [Briscoe & Carrol, 97] están basados en teorías de estructura de frase o de constituyentes.
Los formalismos basados en dependencias difieren de los formalismos basados en constituyentes, en cuanto a subcategorización se refiere, en que los primeros hacen una clara separación entre los complementos reales y los circunstanciales. En la Teoría Texto Û Significado (MeaningÛ Text Theory, MTT) [Mel’cuk, 1988] se describe la diátesis de cada verbo, es decir, la correspondencia entre los actuantes semánticos y los de la sintaxis superficial. Por lo que, la información de subcategorización es específica para casi cada verbo y, además, se separan las representaciones de una misma forma de palabra para un verbo dado con diferentes significados.
En los formalismos basados en constituyentes, esta separación no existe, por lo que pueden incluirse predicados cuya ocurrencia es obligatoria en el contexto local de la frase pero que no son seleccionados semánticamente por el verbo. Al no considerarse la información de subcategorización de una forma específica para cada verbo, generalmente se realiza una clasificación y entonces cada clase (marco de subcategorización) es un patrón de composición de complementos que puede ser compartido por varios verbos. Bajo este esquema la alternación de la diátesis considera que el verbo puede aparecer en una diversidad de marcos de subcategorización.
En el análisis sintáctico por computadora del español, considerando como finalidad el procesamiento de textos sin restricciones, existen dificultades al querer describir los objetos de los verbos en la forma en que se ha hecho para el inglés, mediante formalismos de constituyentes. Algunas características del español requieren de una descripción más adecuada, como su orden menos rígido, la inversión del sujeto, etc.
En la MTT se emplean los llamados Government Patterns (Patrones de Manejo, PM) [Steele, 90] para la descripción de todos los objetos de los verbos. Los PM permiten definir, de una manera más adecuada, esas características del español. En las descripciones de los PM cada palabra encabezado describe su significado, sus actuantes, las palabras específicas que introducen los complementos que realizan sus valencias y las combinaciones de esos complementos, incluyendo el orden de sus ocurrencias, para las opciones permitidas y prohibidas. Este formalismo permite incluir cierto conocimiento semántico: el significado de la palabra encabezado del verbo y sus valencias, y su animidad (si es necesario).
Primero describimos brevemente los Patrones de Manejo y la estructura jerárquica en la MTT. Después las características que tienen una representación más adecuada bajo este formalismo, mediante algunos ejemplos tomados de un corpus grande del español (LEXESP)[2], tanto características del español como las características que permiten detectar información del nivel sintáctico conectada con las valencias semánticas. Enseguida se describe la metodología para obtener la información de subcategorización necesaria para la aplicación de la MTT al español y su nueva descripción. Finalmente se presentan algunos ejemplos de aplicación del método descrito al análisis sintáctico.
2. Patrones de Manejo
En la teoría MTT se describe, con la ayuda de una tabla de PM, la información de correspondencia entre las valencias semánticas y sintácticas de la palabra encabezado, todas las formas en que se realizan las valencias sintácticas y la indicación de obligatoriedad de la presencia de cada actuante, si es necesario.
Después de la tabla de PM se presentan dos secciones: restricciones y ejemplos. Las restricciones consideradas en los PM son de todo tipo: semánticas, sintácticas o morfológicas. La sección de ejemplos cubre todas las posibilidades: ejemplos para cada actuante, ejemplos de todas las posibles combinaciones de actuantes y finalmente los ejemplos de combinaciones imposibles o indeseables.
La parte principal de la tabla de PM es la lista de valencias sintácticas de la palabra encabezado. Se listan de una manera arbitraria pero se prefiere el orden de incremento en la oblicuidad: sujeto, objeto directo, objeto indirecto, etc. También la forma de expresión del significado[3] de la palabra encabezado influye en el orden, por ejemplo la expresión para acusar: Person X accuses person Y in action Z at person W. Esta expresión precede cada PM.
Otra información obligatoria en cada valencia sintáctica es la lista de todas las posibles formas de expresión de la valencia en los textos. El orden de opciones para una valencia dada es arbitraria, pero las opciones más frecuentes aparecen normalmente primero. Las opciones se expresan con símbolos de categorías gramaticales o palabras específicas.
A continuación presentamos una descripción para el verbo acusar aunque una descripción más amplia de este diccionario aparece en [Galicia et al, 98]. En esta descripción NP representa un sintagma nominal e INF representa un verbo en infinitivo.
|
1 = V |
2 = W |
3 = X |
4 = Y |
|
1. NP |
2. a NP |
1. de NP |
4. ante NP |
|
|
|
2. de INF |
|
|
Obliga- |
Obliga- |
|
|
|
C.1 + C.2 |
La policía acusa a Ana. |
|
C.1 + C.2 + C.3.1 |
La policía acusa a Ana de robar. |
|
C.1 + C.2 + C.3.1 + C.4 |
La policía acusa a Ana de robo ante el M.P. |
|
Prohibidas: |
|
|
C.1 + C.3.1 |
La policía acusa de robar. |
|
C.3.1 + C.4 |
Acusa de robo ante el M.P. |
3. Representación jerárquica en la MTT
El árbol de dependencias es la estructura jerárquica que describe las relaciones entre las palabras en las gramáticas de dependencias. Se reconocen pares de palabras relacionadas. Una de ellas es la rectora y la otra subordinada. La palabra rectora puede ser a su vez subordinada en otro par de palabras.
Por ejemplo, en la oración Siqueiros acusó a Rivera de pintar para turistas[4], existen diferentes pares como Siqueiros acusó, acusó a, a Rivera, etc. donde las palabras subrayadas son las rectoras. La única palabra que no está subordinada a otra es la raíz del árbol.
En esta representación jerárquica, a diferencia de los constituyentes, el orden no es importante porque la información se mantiene a través de las etiquetas de dependencias, marcadas en los arcos del árbol.
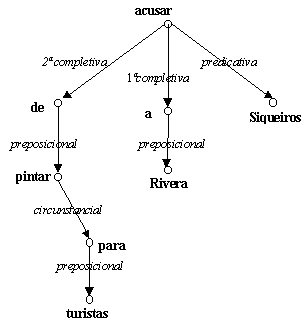
En este ejemplo del árbol de dependencias se expresan los objetos del verbo acusar, que se describieron en su patrón de manejo. Puede observarse también cómo para esta frase se hace la diferencia de un complemento circunstancial para el verbo pintar. Este árbol se obtendría directamente de los patrones de ambos verbos.
Principalmente los verbos, aunque también los adjetivos y los sustantivos son las palabras para las cuales se compilan los patrones de manejo sintáctico que permiten establecer las relaciones marcadas.
4. Representación de algunas características en la MTT
Algunas características del español no tienen una representación adecuada en los formalismos de constituyentes. De entre ellas consideramos el orden de palabras, el sujeto, la animidad, y la identificación de valencias sintácticas a través de la detección de palabras específicas.
4.1 Orden de palabras
El orden de palabras en el español es más libre comparado con el inglés. Por ejemplo, en las frases siguientes el objeto indirecto no aparece después del verbo, de tres maneras distintas: 1) en la forma a NP (grupo nominal) antes del verbo, 2) como pronombre reflexivo entre sujeto y verbo, y 3) como clítico dentro del verbo.
1. A quienes acusan de comportamiento arrogante.
2. El fiscal me acusa de delito de alta traición.
3. Acusándole de ser el sostenedor y portavoz de Mario Segni.
Para el español, esta información de posibles posiciones de cada valencia es necesaria para el analizador sintáctico y corresponde a las combinaciones posibles en la MTT.
4.2 Sujeto y animidad
La descripción del sujeto como una valencia más del verbo permite el reconocimiento correcto de valencias del verbo. La inversión del sujeto es considerada como un recurso estilístico de frecuencia de aparición menor, sin embargo, [Zubizarreta, 94] explica que investigaciones recientes sobre el orden de las palabras en el español indican que el español y el italiano permiten la inversión libre del sujeto, a diferencia del francés. Por ejemplo, en las siguientes frases, el sujeto aparece después del verbo en dos formas distintas, como nombre propio y como NP.
Le acusaba Apel de desembocar en una ilusión idealista por ....
A quien acusaron varios testigos.
En ambos casos, en el análisis sintáctico por computadora, puede haber un reconocimiento erróneo de valencias o del significado del verbo o ambos. Mientras en la primera frase el reconocimiento de nombre propio evitaría el error, en la segunda frase se requiere diferenciar entre entidad animada y grupo nominal para reconocer el sujeto de acusar1 (denunciar a alguien como culpable de algo). La valencia realizada como NP corresponde al verbo acusar2 (revelar algo, ponerlo de manifiesto) [DEUM, 96]. Si varios testigos se reconoce como NP resultará en una asignación de estructura incorrecta o de otro significado.
La animidad (an) en español tiene ciertas particularidades. En muchos lenguajes europeos el objeto directo está conectado con el verbo sin preposiciones; pero en español, las entidades animadas están conectadas mediante la preposición a y las no animadas directamente (veo a mi vecina y veo una casa). La animidad se considera como una personificación, por ejemplo gobierno en español es un sustantivo animado y al dirigirse a él se utiliza la preposición a (al gobierno). Además de personas, la animidad abarca grupos de personas, animales, países, entidades abstractas (organizaciones, partidos políticos), etc. En cambio, por ejemplo, en ruso los grupos de personas, los países, las ciudades no se personifican en sentido gramatical.
Aunque la preposición a también tiene otros usos, aquí nos referimos exclusivamente a su conexión con el objeto directo. Este uso sirve para diferenciar el significado de algunos verbos, por ejemplo, querer algo (tener el deseo de obtener algo) y querer a alguien (amar o estimar a alguien). Así que la animidad es una característica evidentemente sintáctica pero con alusión semántica que se considera para la realización de las valencias, por ejemplo: a NP(an) para la valencia W de acusar1.
4.3 Información detectable a nivel sintáctico
Existe información semántica detectable a nivel sintáctico requerida en niveles más profundos del procesamiento de lenguaje natural. Por ejemplo, la detección de valencias sintácticas que se enlazarán a las valencias semánticas, y la distinción entre complementos reales del verbo y complementos circunstanciales realizados con la misma descripción de subcategorización.
Para algunos verbos una sola palabra se identifica como la palabra que introduce los complementos que expresan una valencia, como en el ejemplo de acusar, en cambio en otros verbos varias palabras se emplean con el mismo propósito. Por ejemplo, para el verbo plantear laspreposiciones a y ante (a NP, ante NP) se emplean para realizar la valencia que describe a quién se plantea algo.
Para algunos verbos, un marco de subcategorización describe tanto valencias del verbo como circunstancias. Por ejemplo, algunos verbos locativos [Rojas, 88] requieren complementos con la noción de espacio, cuya marca aparece tanto en la palabra introductora del complemento como en el complemento mismo, por ejemplo el verbo poner. En la frase pone el cuadro en este momento en el espacio disponible, el marco de subcategorización en NP describe tanto una valencia (en el espacio disponible) como un complemento irrelevante para su significado (en este momento). Esta marca de locatividad (loc) al igual que la de animidad se introducen en la descripción de las valencias.
5. Descripción de la Información de Subcategorización
En esta sección presentamos tanto la información de subcategorización requerida para el análisis sintáctico del español como la nueva descripción de los patrones de manejo que en base a ella se propone.
La información completa requerida la denominamos Marco Avanzado de Subcategorización (MAS). Esta información corresponde principalmente con la información expuesta en la sección 2. La indicación de obligatoriedad de la presencia de cada actuante, las posibles combinaciones de actuantes y las combinaciones prohibidas las hemos considerado de otra forma.
|
Figura 1. Marco Avanzado de Subcategorización Donde: + denota uno o más elementos V_INF verbo en infinitivo * denota cero o más elementos PPR pronombre personal ~ denota el verbo
|

Consideramos la obtención de pesos estadísticos; si una valencia tiene presencia en todas las oraciones extraídas para un verbo específico se considera como una evidencia de obligatoriedad. El analizador sintáctico empleará esta evidencia para buscar las valencias aún en enlaces distantes. Por ejemplo, el verbo acusar requiere la presencia del objeto directo, con esta indicación, el analizador sintáctico buscará este pedazo de información alrededor del verbo, considerando también las probabilidades de su aparición antes y después del verbo.
En el método propuesto, obtenemos los pesos estadísticos para cada valencia, referidos a las palabras introductoras de ellas, y después los pesos estadísticos de las combinaciones de valencias referidas a la posición de cada valencia respecto al verbo. Esta información estadística da un rango de las descripciones de los tipos específicos de cada valencia y de sus combinaciones, que permitirán incrementar la eficiencia del analizador sintáctico.
En la figura 1 se muestra la descripción general de los MAS, su forma es similar con las formas presentadas por el formalismo de constituyentes HPSG (Head-driven Phrase Structure Grammar, en inglés) [Pollard & Sag., 94] y con la descripción de subcategorización en [EAGLES, 96].
En las figuras 2 y 3 se muestran los MAS obtenidos a partir de un total de 264 oraciones de LEXESP para el verbo acusar, en una presentación más práctica que la definida en la figura 1, por ejemplo, a NP(an) se describe como (a, an). Todas las estadísticas del método propuesto se muestran en ambas figuras. De la información obtenida, se reconocen acusar1 y acusar2. Mientras acusar1 requiere más palabras introductoras, acusar2 no las requiere. Así que la valencia W realizada mediante NP, solamente presente en este último verbo, marca la diferencia entre los dos, siempre y cuando pueda discriminarse entre grupos nominales animados y no animados. Un análisis más detallado de estos MAS se presenta en [Galicia et al, 99].
|
Figura 2. MAS para el verbo acusar1
|

Una de las desventajas para la aplicación del formalismo de la MTT es la obtención del conocimiento lingüístico descrito en los MAS. En su aplicación a otros lenguajes se ha realizado manualmente con los inconvenientes que esto representa en cuanto a recursos humanos y tiempo, requeridos. Una herramienta necesaria para su aplicación debería obtener en forma automática la información descrita en los MAS.
Una aproximación para la obtención de esta información, a partir de un corpus, en cuanto a detección de las frases preposicionales y complementos que expresan las valencias se describe en [Gelbukh et al, 98]. La detección de valencias del verbo y la distinción de significados actualmente se considera con anotación manual, aunque la información extraída para la compilación de los MAS facilita este trabajo.
6. Ejemplos de análisis sintáctico del español
Para la realización del análisis sintáctico consideramos la estrategia natural y general de análisis sintáctico en dos pasos de las gramáticas lexicalizadas.
El primer paso selecciona el conjunto de estructuras correspondientes a cada palabra en la oración de entrada. El segundo paso analiza sintácticamente la oración respecto a las estructuras seleccionadas.
A continuación presentamos cuatro ejemplos extraídos de textos de la Gaceta de la UNAM, donde se subrayan los verbos para los cuales se debe contar con sus Patrones de Manejo. El verbo en común es el verbo acusar. En estos ejemplos solamente se considera el análisis de los fragmentos para este verbo, ya que para él se mostraron los MIS obtenidos a partir del corpus LEXESP.
1. Si sabemos que los dientes son las piezas más duras del cuerpo humano y que continúan intactos durante muchos años después de la muerte, cuando ya la mayor parte de la estructura ósea acusa un alto grado de deterioro, se entenderá la gravedad de la estadística citada ...
2. En aquellos años, comentó, Siqueiros acusó públicamente a Rivera de venderse y pintar para turistas burgueses niños de caras tristes y felices vendedores de mercado, pero él mismo se vio forzado a completar sus ingresos de forma similar.
3. De todo se le acusó a Lewis, agregó, pero sin duda, la mejor de todas las acusaciones fue que lo había inventado todo, incluso a los Sánchez, que jamás habían existido; y que lejos de ser un conjunto de testimonios era una novela que había sido escrita con el propósito de denigrar a México.
4. Asimismo está el general Esteban Moctezuma, quien se levantó en armas junto con Vicente Guerrero para proclamar la República en 1822, y quien tiempo después también se alzó en armas contra Anastasio Bustamante, a quien acusó, junto con José Antonio Barragán, del asesinato de Guerrero.
En el ejemplo 1, la parte de la oración relacionada al verbo acusar es cuando ya la mayor parte de la estructura ósea acusa un alto grado de deterioro. Tratándose del verbo acusar1 debería de existir la valencia W que se presenta en 52.4% de los casos mediante la preposición introductora a o por pronombre personal en la mayoría de los casos restantes. Tratándose del verbo acusar2 cumple con la combinación para el 97.3% de los casos, [V ~ W, 97.3%].
En el ejemplo 2, la parte relacionada al verbo acusar es Siqueiros acusó públicamente a Rivera de venderse y pintar para turistas burgueses niños de caras tristes y felices vendedores de mercado. Se consideran los dos verbos en infinitivo ya que uno de los PM para el verbo acusar considera el caso de V_INF. Aquí el adverbio públicamente tiene una relación directa con el verbo, y la parte restante empata con la combinación [V ~ W X, 40.97%] donde la valencia X corresponde a la realización (de, V_INF, 48.9%). La unión de venderse y pintar se debe establecer mediante otro tipo de relaciones sintácticas.
|
Figura 3. MAS para el verbo acusar2
|

El ejemplo 3, en el fragmento De todo se le acusó a Lewis, ilustra el caso de la combinación [X V ~ W, 0.44%], aunque aquí se presenta un caso que requiere más estudio, la repetición de valencias sintácticas que corresponden a una sola valencia semántica. Tanto le como a Lewis corresponden a la valencia W, que deberá registrarse en los patrones de manejo de verbos que acepten esta repetición.
El último ejemplo, muestra el caso de la combinación [W V ~ X, 10.13%], en el fragmento a quien acusó, junto con José Antonio Barragán, del asesinato de Guerrero. La frase junto con José Antonio Barragán corresponde a un complemento circunstancial al no estar descrito en el Patrón de Manejo.
Conclusiones
Se describió la aplicación del formalismo considerado en la teoría Texto Û Significado para el análisis sintáctico del español, las ventajas de su uso al describir más adecuadamente características del lenguaje, la información requerida para el diccionario de patrones de manejo y la forma en que se podría realizar el análisis sintáctico.
Se presentó la necesidad de discriminar las valencias y las formas en que ellas se realizan. Se mostró la necesidad de incluir información estadística tanto para representar combinaciones de valencias y la condición de obligatoriedad de algunas valencias, como para incrementar la eficiencia del analizador sintáctico
Bajo este formalismo se espera un análisis sintáctico más preciso y la posibilidad de relacionar cierta información del nivel sintáctico que está conectada con la semántica de la palabra y que se requiere a niveles más profundos del procesamiento de lenguaje natural.
El trabajo futuro, incluirá el estudio de otras particularidades del español como la repetición de valencias sintácticas.
Referencias
Boguraev, B. et al. 1987. The derivation of a grammatically-indexed lexicon from the Longman Dictionary of Contemporary English. In Proceedings of the 25th Annual Meeting of the Association for Computational Linguistics, Stanford, CA.
Briscoe, E. & J. Carroll. 1997. Automatic extraction of subcategorization from corpora. In Proceedings of the 5th ACL Conference on Applied Natural Language Processing. Washington, DC.
DEUM. 1996. Diccionario del Español usual en México. El Colegio de México.
EAGLES. 1996. Recommendations on Subcategorization. http:// www.ilc.pi. cnr.it/EAGLES96/synlex/synlex.html
Galicia-Haro, S. N., I. Bolshakov & A. Gelbukh.1998. Diccionario de patrones de manejo sintáctico para análisis de textos en español. Proc. XIV Congreso Internacional de la SEPLN, Septiembre 23-25, Alicante, España.
Galicia-Haro, S. N., A. Gelbukh, & I. Bolshakov. 1999. Advanced subcategori-zation frames for languages with relaxed word order constraints (on Spanish examples). Accepted to Proc. Venecia per il Trattamento Automatico delle Lingue (VEXTAL), November 22 to 24 1999.
Gelbukh, A., I. Bolshakov and S. Galicia-Haro. 1998 Statistics of parsing errors can help sintactic disambiguation. Proc. CIC-98 - Simposium Internacional de Computación, November 11 - 13, Mexico D.F., pp. 405 - 515.
Grishman, R., C. Macleod & A. Meyers. 1994. Comlex syntax: building a computational lexicon. In the proceedings of the 15th Conference on Computational Linguistics, pp. 268-272 (COLING-94).
Mel’cuk, I. A. 1988. Dependency Syntax: Theory and Practice. State University of New York Press. Albany
Pollard, C. J. & I. A. Sag. 1994. Head-Driven Phrase Structure Grammar. The University of Chicago Press, Chicago & London.
Rojas, C. 1988. Verbos locativos en español. Aproximación sintáctico-semántica. Universidad Autónoma de México.
Steele, J. 1990. Meaning – Text Theory. Linguistics, Lexicography, and Implications. James Steele, editor. University of Ottawa press.
Tesnière, L. 1959. Éléments de Syntaxe Structurale. 2nd edition. Paris: Klincksieck.
Zubizarreta, María Luisa. 1994. El orden de palabras en español y el caso nominativo. En Gramática del Español, edición a cargo de Violeta Demonte. El Colegio de México.